 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











敏捷方法论承诺灵活性、响应性和持续改进。然而,现实往往伴随着挫折。一次失败的冲刺并非异常,而是一个数据点。团队如何应对失败,比庆祝完美周期更能决定长期成功。
本文探讨了一个开发团队完全未能达成冲刺目标的具体情况。我们将分析其中涉及的技术和人为因素,回顾用于诊断问题的回顾流程,以及为恢复速度和质量所采取的具体措施。
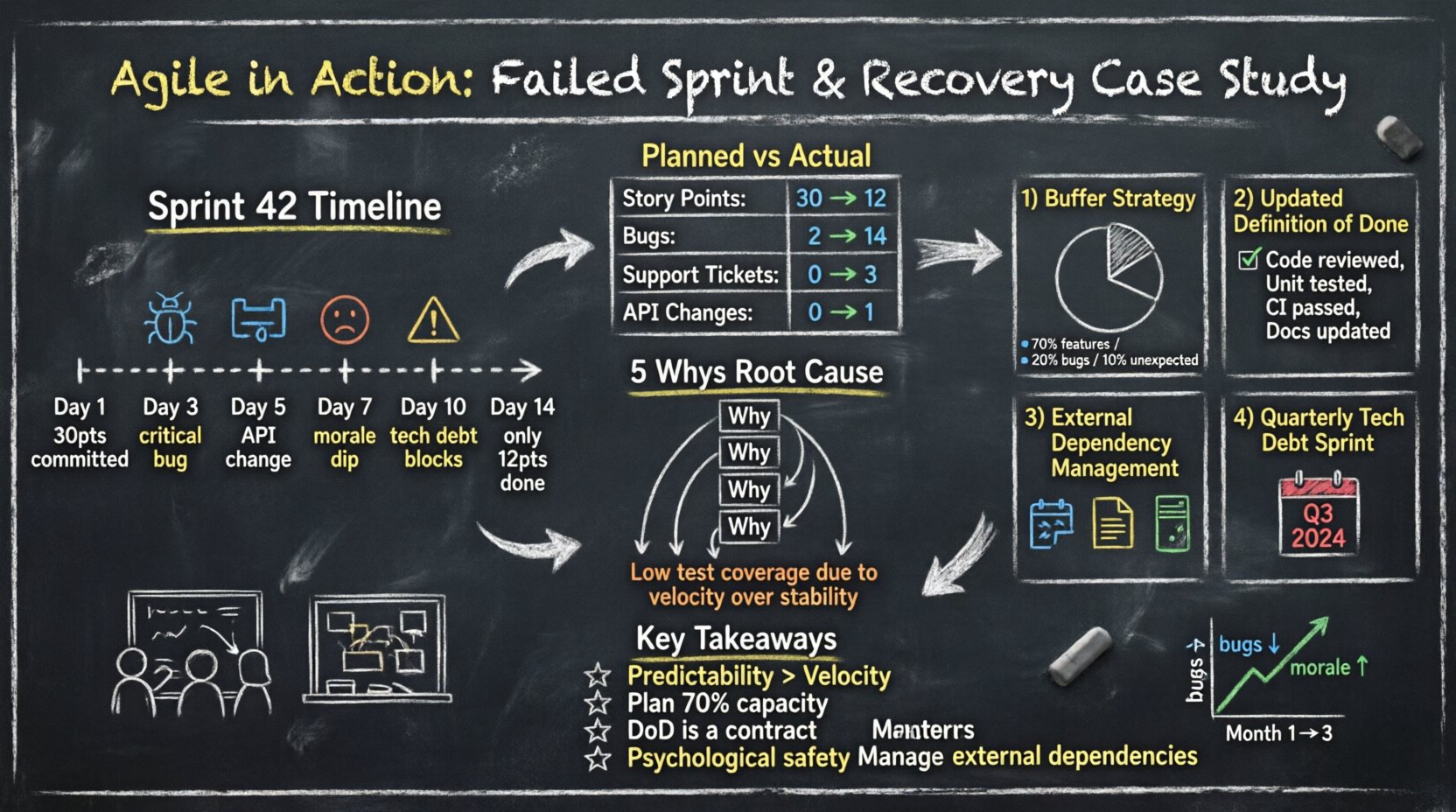
要理解失败的原因,我们必须首先了解团队的结构。该组织采用跨职能团队模式,团队由五名开发人员、一名产品负责人和一名专职测试人员组成。工作以两周为一个周期进行组织。
团队使用实体和数字看板来管理流程。故事从待办事项列表移动到进行中,最后移动到已完成。目标是在不牺牲代码质量的前提下,持续交付价值。
冲刺42开始时势头强劲。团队从待办事项列表中提取了30个故事点。到第三天,进度看似稳定。第五天,问题开始显现。到第十天,团队意识到无法完成承诺的工作。
失败并非由单一灾难性事件引起,而是多个问题叠加,逐步侵蚀了团队的承载能力。
数据比感受更能说明问题。下表展示了计划投入与实际交付之间的差异。
| 类别 | 计划 | 实际 | 差异 |
|---|---|---|---|
| 完成的故事点数 | 30 | 12 | -18 |
| 冲刺期间发现的缺陷 | 2 | 14 | +12 |
| 处理的支持工单 | 0 | 3 | +3 |
| 外部依赖变更 | 0 | 1 | +1 |
这些数据揭示了资源的重大偏离。原本的开发工作演变成了维护和危机管理。
指责个人并不能解决系统性问题。团队进行了一次无责的根本原因分析,以识别根本问题。
为了深入挖掘,团队应用了五问法 方法来解决错过截止日期的问题。
根本问题并非计划准确性,而是可持续的工程实践。
回顾是敏捷改进的引擎。然而,一次失败的冲刺需要一种特定类型的回顾。标准格式往往感觉像是走形式。这次会议需要心理安全感和深入探究。
会议前,产品负责人收集了数据。团队被要求独立反思哪些做得好,哪些没有做好。这确保了沉默的成员有时间整理思路。
团队讨论了容量规划的概念。他们意识到自己已经将100%的时间都投入到新功能开发中,对于生产环境中不可避免的中断完全没有缓冲余地。
他们还讨论了完成的定义。目前,“完成”意味着“代码已编写”,但不包括“代码已审查”或“测试已编写”。这种差异导致了冲刺末期的瓶颈。
了解问题是战斗的一半。恢复计划需要对工作流程、预期和专业技术标准进行调整。
团队停止承诺将所有可用时间都投入工作。他们采用了缓冲策略.
这一改变减轻了必须交付完美数字的压力,并允许更现实地应对中断。
团队更新了他们的完成的定义检查清单。一个故事无法进入完成,除非满足以下标准:
这防止了技术债务悄然积累。它确保了交付的内容确实是可用的。
与外部供应商的沟通渠道已正式确立。团队现在要求:
团队同意每季度专门安排一次冲刺来减少技术债务。这可以防止糟糕代码的复利效应。它向利益相关者表明,稳定性是一种特性,而非事后考虑。
变更在第43个冲刺中立即实施。恢复并非立竿见影,但趋势发生了转变。
团队并未试图恢复旧的30分速度。他们追求的是可预测性。与其过度承诺而失败,不如承诺更少但持续交付,这样更好。
为了确保恢复持续进行,团队在接下来的三个月里跟踪了特定的指标。
| 周 | 冲刺目标达成 | 缺陷数量 | 团队士气(1-5) |
|---|---|---|---|
| 第1个月 | 是 | 12 | 3 |
| 第2个月 | 是 | 8 | 4 |
| 第3个月 | 是 | 5 | 5 |
数据显示,流程变化与团队健康状况之间存在明显关联。缺陷减少带来了压力降低,从而提升了士气。
失败是老师。以下是本案例研究中得出的教训,适用于任何敏捷环境。
没有稳定性的速度只是一种幻觉。团队应优先考虑稳定交付,而非单纯追求产出量。利益相关者更信任那些能够兑现承诺的团队,即使这些承诺规模较小。
始终为意外情况留出余地。如果你有100小时可用,就只计划70小时的工作量。剩余时间用于消化软件开发中不可避免的摩擦。
完成的定义不是建议。它是团队与产品负责人之间的合同。如果一个故事未达到完成的定义,就不具备发布条件。
当出现问题时,团队必须感到可以安全地发声。如果成员害怕受到惩罚,他们会隐瞒问题,直到问题演变成危机。
软件并非孤立存在。对第三方服务的依赖必须像管理内部代码一样严格对待。
许多团队试图通过更加努力来解决失败。这是一个常见的错误。在恢复期间,应避免以下行为。
敏捷的目标不仅仅是交付代码,更是建立一个能够持续交付代码的系统。可持续的节奏是这个系统的基础。
恢复之后,团队建立了一个持续改进的节奏。每两周,他们不仅回顾冲刺,还审视工作流程的健康状况。他们会提出诸如:
这种持续的审视能够防止小问题再次演变成大失败。
与利益相关者保持透明至关重要。当冲刺失败时,应尽早沟通。解释影响、原因和应对计划。这能建立信任。
利益相关者常常将失败的冲刺视为无能。但若将其解释为改进的数据点,这反而体现了专业成熟度。他们更倾向于一个承认问题并解决问题的团队,而不是掩盖问题的团队。
失败是正常的。根据领域不同,10%的失败率通常是可以接受的。持续的高失败率表明存在系统性的计划问题。
通常不应停止。停止冲刺会浪费已投入的时间。最好完成能完成的部分,然后为下一个周期重新开始。
是的,如果您的速度因过度承诺而被人为抬高。将其降低到符合现实水平,能提升准确性和可预测性。
短期解决方案是可能的,但长期恢复需要流程变革。否则,失败将重复发生。
敏捷是一种适应性的旅程。一次失败的冲刺并非道路的终点;它是一个指向更好实践的路标。通过深入分析失败原因并实施结构性变革,团队能够变得更强大、更具韧性。