 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











敏捷方法論承諾靈活性、回應力與持續改進。然而,現實中經常伴隨挫折。一次失敗的迭代並非異常;而是一個數據點。團隊如何應對失敗,比慶祝完美週期更能決定長期的成功。
本文將探討一個開發團隊完全未能達成迭代目標的具體情境。我們將分析其中涉及的技術與人為因素,回顧用來診斷問題的過程,以及實際採取的措施以恢復速度與品質。
要理解失敗的原因,我們必須先了解團隊結構。該組織採用跨功能團隊模式,團隊由五名開發人員、一名產品負責人及一名專職測試人員組成。工作以兩週為一個週期進行組織。
團隊使用實體與數位追蹤看板來管理流程。故事從待辦事項移動到進行中,最後到達完成。目標是在不犧牲程式碼品質的前提下,持續交付價值。
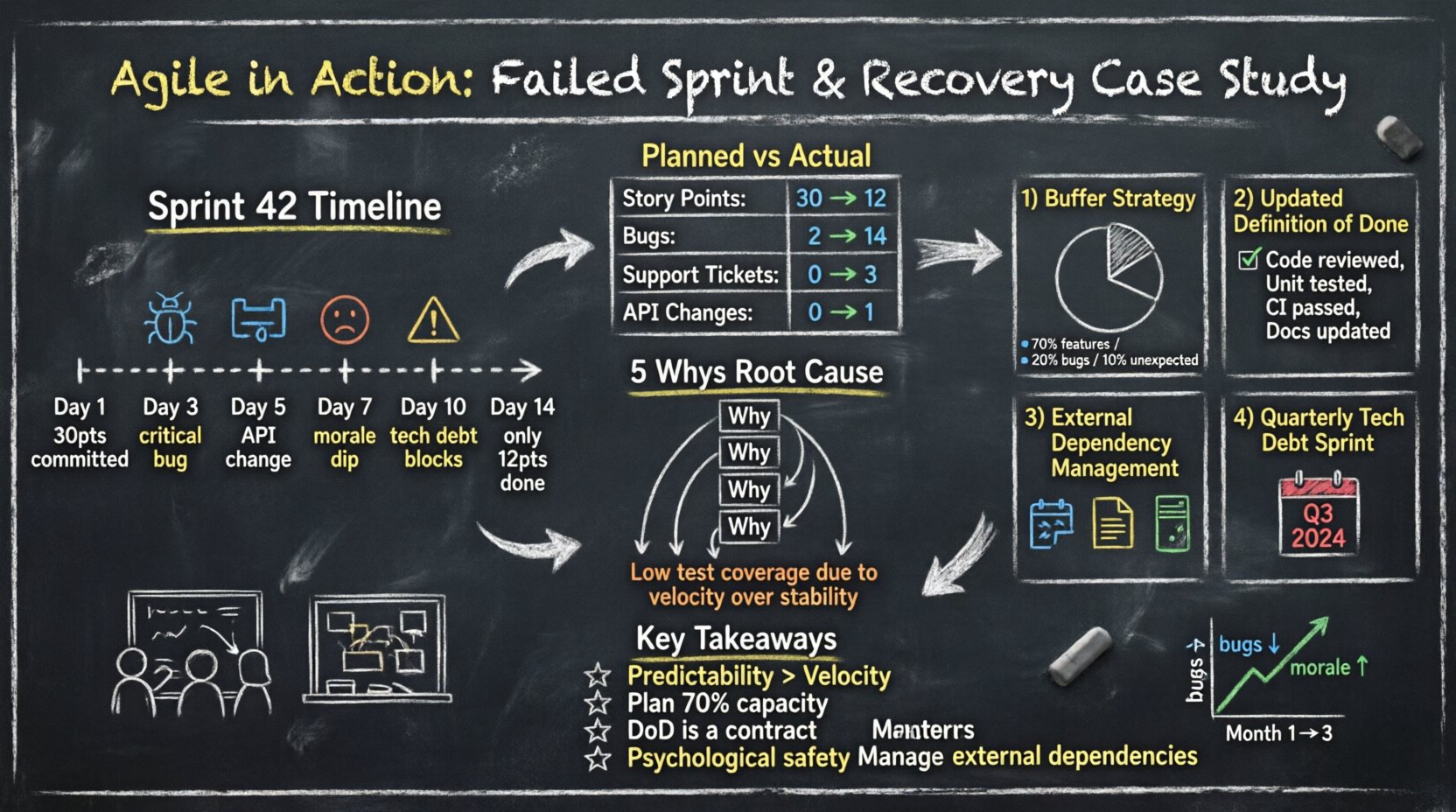
第42次迭代開始時動能強勁。團隊從待辦事項中拉取了30個故事點。第三天時,進度看似穩定。第五天時,摩擦開始出現。到了第十天,團隊意識到無法完成承諾的工作。
這次失敗並非由單一災難性事件導致,而是多個問題累積所致,逐漸削弱了團隊的承載能力。
� 數據比感受更能說明問題。下表展示了計劃投入與實際交付之間的差異。
| 類別 | 計劃 | 實際 | 差異 |
|---|---|---|---|
| 完成的故事點數 | 30 | 12 | -18 |
| 在迭代期間發現的錯誤 | 2 | 14 | +12 |
| 處理的支持工單 | 0 | 3 | +3 |
| 外部依賴變更 | 0 | 1 | +1 |
這些數據揭示了資源的重大偏移。原本的開發工作轉變為維護與危機應對。
責怪個人無法解決系統性問題。團隊進行了無責備的根本原因分析,以識別背後的根本問題。
為了深入探討,團隊應用五個為什麼 方法來探討錯過期限的問題。
核心問題並非規劃準確性,而是可持續的工程實踐。
回顧是敏捷改進的引擎。然而,一次失敗的衝刺需要一種特定類型的回顧。標準格式往往讓人覺得像填表作業。這次會議需要心理安全感與深入探詢。
會議前,產品負責人收集了資料。團隊被要求獨立反思哪些做得好,哪些不理想。這確保了較為安靜的成員有時間整理想法。
團隊討論了「容量規劃」的概念。他們意識到自己已將100%的時間投入於新功能開發。對於生產環境中不可避免的中斷,毫無應變空間。
他們也討論了「完成定義」。目前「完成」僅代表「程式碼已撰寫」,並未包含「程式碼審查完成」或「測試已撰寫」。這種落差導致了衝刺結束時的瓶頸。
了解問題僅是戰勝困難的一半。復原計畫需要對工作流程、預期目標與技術標準進行調整。
團隊停止承諾所有可用時數的100%。他們採用了「緩衝策略.
此項調整減輕了必須交付完美數字的壓力,並允許更實際地應對中斷。
團隊更新了他們的「完成定義檢查清單。一個故事無法移動到完成,除非滿足以下標準:
這防止了技術債項默默累積。確保了交付的內容確實可用。
與外部供應商的溝通管道已正式化。團隊現在要求:
團隊同意每季專門撥出一個迭代來減少技術債項。這可防止劣質程式碼產生複利效應。這向利益相關者傳達了穩定性是一項功能,而非事後補救。
變更已在第43個迭代中立即實施。恢復並非瞬間完成,但趨勢已發生轉變。
團隊並未試圖回到舊的30點速度。他們追求的是可預測性。承諾較少並穩定交付,總比過度承諾卻失敗來得好。
為了確保復甦持續,團隊在接下來的三個月裡追蹤了特定指標。
| 週 | Sprint目標達成 | 錯誤數量 | 團隊士氣(1-5) |
|---|---|---|---|
| 第一個月 | 是 | 12 | 3 |
| 第二個月 | 是 | 8 | 4 |
| 第三個月 | 是 | 5 | 5 |
數據顯示流程變更與團隊健康之間有明顯關聯。錯誤減少導致壓力降低,進而提升了士氣。
失敗是一種老師。以下是從本案例研究中學到的教訓,適用於任何敏捷環境。
沒有穩定性的速度只是一種幻覺。團隊應優先考慮穩定交付,而非原始產出。利益相關者會信任那些實現承諾的團隊,即使這些承諾規模較小。
永遠要為意外情況做規劃。如果你有100小時可用,就規劃70小時的工作。剩餘時間用來吸收軟體開發中不可避免的摩擦。
完成定義不是建議。它是團隊與產品負責人之間的合約。如果一個故事未達成完成定義,就不具備發布資格。
當事情出錯時,團隊必須感到有安全感才敢發言。如果成員害怕懲罰,他們會隱藏問題,直到問題演變成危機。
軟體並非孤立存在。對第三方服務的依賴必須以與內部程式碼同等嚴謹的方式進行管理。
許多團隊試圖透過更努力工作來解決失敗。這是一個常見的錯誤。在恢復期間,應避免以下行為。
敏捷的目標不僅是交付程式碼,更是建立一個能無限持續交付程式碼的系統。可持續的節奏是這個系統的基礎。
恢復後,團隊建立了持續改進的節奏。每兩週,他們不僅回顧每次衝刺,還檢視工作流程的健康狀況。他們會提出類似以下問題:
這種持續的審查能防止小問題再次演變成重大失敗。
與利害關係人保持透明至關重要。當衝刺失敗時,應盡早溝通。說明影響、原因與應對計畫。這能建立信任。
利害關係人常將失敗的衝刺視為無能。但若將其解釋為改進的數據點,便展現了專業的成熟度。他們更傾向於一個承認問題並解決問題的團隊,而非隱藏問題的團隊。
失敗是正常的。根據領域不同,10%的錯過率通常可接受。持續高錯過率則顯示系統性規劃問題。
通常不應停止。停止衝刺會浪費已投入的時間。不如完成能完成的部分,再為下一週期重新啟動。
是的,如果您的速度因過度承諾而被虛高。將其降低至符合現實,能提升準確性與可預測性。
短期的解決方案是可能的,但長期的恢復需要流程變更。否則,失敗將會重複。
敏捷是一段適應的旅程。一次失敗的迭代並非道路的終點;它是一個指向更好實踐的路標。透過深入分析失敗並實施結構性變更,團隊能夠變得更強大、更具韌性。