 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Создание визуального представления того, как информация перемещается через систему, является фундаментальным навыком для аналитиков, разработчиков и бизнес-заинтересованных сторон. Диаграмма потоков данных, широко известная как DFD, выполняет именно эту задачу. Она отображает поток данных между внешними сущностями, внутренними процессами и хранилищами данных, не обязательно детализируя конкретную логику или временные параметры. Это руководство предлагает структурированный подход к эффективному созданию вашей первой DFD.
Многие люди считают создание диаграмм пугающим, опасаясь, что для этого требуются сложные инструменты или много времени. Однако основные принципы моделирования потоков данных просты. При четком понимании символов и систематическом подходе вы сможете нарисовать функциональную диаграмму за короткий промежуток времени. В этой статье мы рассмотрим основные компоненты, пошаговый процесс построения и проверки, необходимые для обеспечения точности.
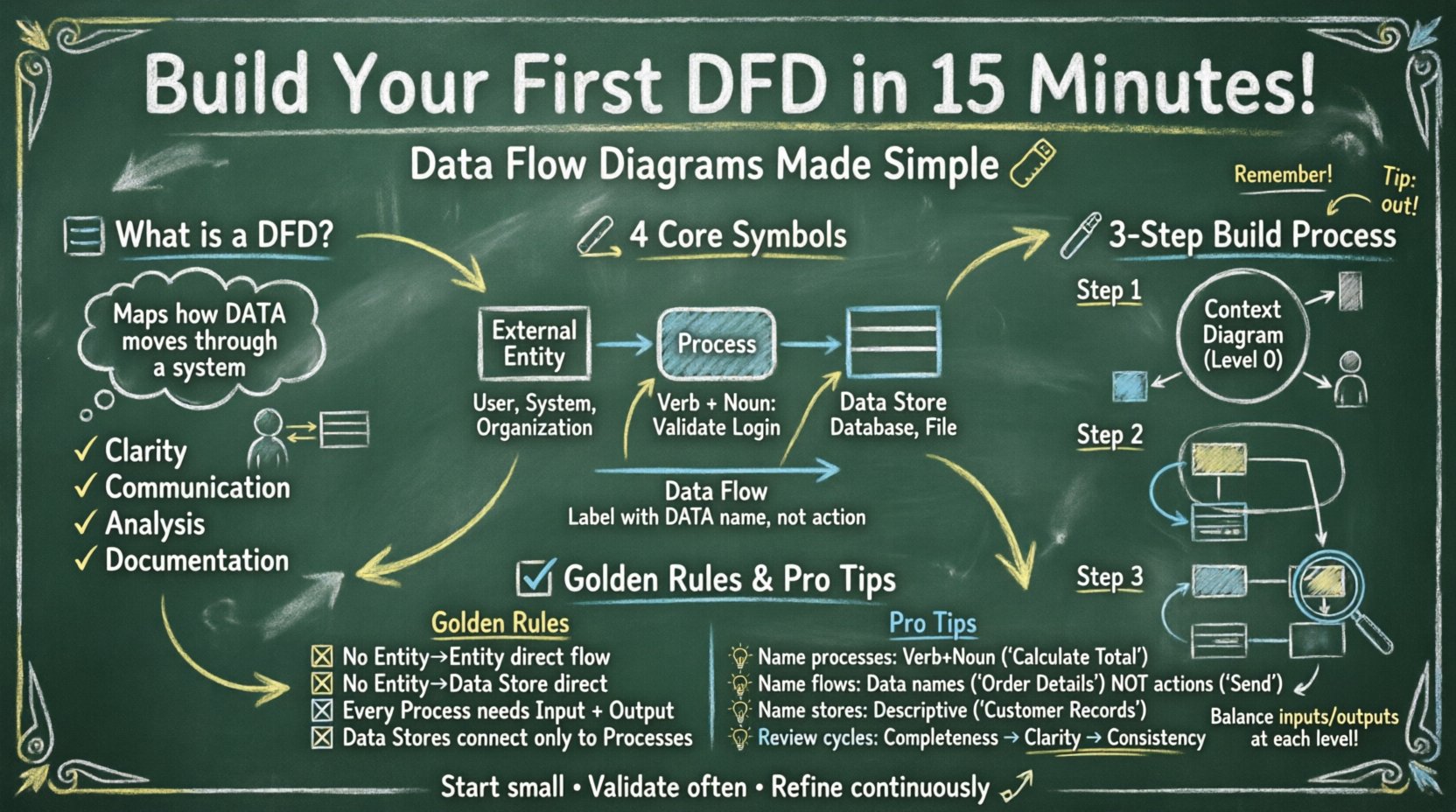
Прежде чем рисовать линии и фигуры, важно понять, что представляет собой DFD. Это функциональная модель. Она фокусируется на что что делает система, а не как это делает. В отличие от блок-схемы, которая отслеживает пути принятия решений и логические последовательности, DFD отслеживает перемещение пакетов данных от источника к месту назначения.
Ключевые преимущества использования этой методологии включают:
Когда вы начинаете это упражнение, помните цель: визуализировать границы и взаимодействия вашей конкретной системы. Для начала вам не нужно продвинутое программное обеспечение. Доска, лист бумаги и ручка — достаточные инструменты для первоначического наброска.
DFD опираются на стандартизированный набор графических элементов. Хотя существуют различия в нотации (например, Yourdon/DeMarco против Gane/Sarson), основные концепции остаются неизменными. Ниже приведено описание четырех основных компонентов, с которыми вы столкнетесь.
| Компонент | Форма | Описание |
|---|---|---|
| Внешняя сущность | Прямоугольник или квадрат | Источник или место назначения данных вне системы (например, пользователь, другая система). |
| Процесс | Округлый прямоугольник или круг | Преобразует входные данные в выходные. Изменяет форму или содержание. |
| Хранилище данных | Открытый прямоугольник или параллельные линии | Хранилище, где находятся данные (например, база данных, файловый шкаф). |
| Поток данных | Стрелка | Путь, по которому данные перемещаются между компонентами. Он представляет перемещение, а не действие. |
Понимание этих различий имеет решающее значение. Например, процесс должен иметь хотя бы один вход и один выход. Хранилище данных не может просто существовать в изоляции; оно должно быть подключено к процессу, чтобы его можно было читать или записывать. Внешние сущности находятся за пределами границы системы и выступают в роли триггера или получателя.
Чтобы построить вашу диаграмму в указанные сроки, следуйте этой логической последовательности. Этот метод гарантирует, что вы определите границы до того, как углубитесь в детали.
Начните с диаграммы контекста (часто называемой уровнем 0). Это наиболее высокий уровень представления. Он показывает систему как единый процесс и её взаимодействие с внешним миром.
Например, в системе библиотеки «Заемщик» — это сущность. Процесс «Выдать книгу» — это система. Поток данных может быть «Запрос на выдачу» или «Сведения о книге».
Как только контекст установлен, вы должны расширить единственный центральный процесс до подпроцессов. Это создаёт диаграмму уровня 0.
Убедитесь, что каждый элемент, выходящий из сущности в диаграмме контекста, по-прежнему присутствует на диаграмме уровня 0, но теперь он может подключаться к различным внутренним процессам.
Это приводит к диаграмме уровня 1. Вы выбираете один процесс на уровне 0 и детализируете его дальше.
Диаграмма бесполезна, если её метки неоднозначны. Чёткие правила именования предотвращают путаницу при проверке и реализации.
Имена процессов должны следовать структуре глагол-существительное. Это уточняет выполняемое действие.
Избегайте общих названий, таких как «Процесс 1», если только вы не находитесь на очень ранней стадии чернового наброска. Конкретные названия способствуют лучшему пониманию.
Стрелки представляют данные, а не действия. Обозначьте их названием пакета данных.
Они должны указывать на хранимый контент.
После черновика проверьте диаграмму по стандартным правилам, чтобы обеспечить целостность. Допустимая диаграмма потоков данных должна соответствовать определённым логическим ограничениям.
Даже опытные аналитики допускают ошибки при первоначальном моделировании. Следите за этими распространенными ошибками:
Создание диаграммы потоков данных редко бывает одноразовым мероприятием. Это итеративный процесс уточнения. Ваш первый черновик, скорее всего, будет содержать пробелы или ошибки. Это нормально.
Цикл проверки 1: Проверьте полноту. Все ли требования пользователей учтены? Учитывается ли каждый источник данных?
Цикл проверки 2: Проверьте ясность. Может ли новый член команды посмотреть на это и понять поток без вопросов?
Цикл проверки 3: Проверьте согласованность. Соответствуют ли имена на разных уровнях диаграммы? Если поток данных в уровне 0 называется «Информация о клиенте», он должен оставаться таким же на уровне 1, если только он не разбит на отдельные атрибуты.
Не спешите завершать диаграмму. Уделите время обратной связи от заинтересованных сторон. Их мнение часто выявляет скрытые требования к данным или процессы, которые вы упустили.
По мере роста вашей системы одна страница может оказаться недостаточной. Вам может понадобиться управлять несколькими диаграммами. Вот как логически организовать их.
Используйте перекрёстные ссылки. Если процесс на уровне 1 расширен на уровне 2, пометьте родительский процесс на уровне 1 кодом ссылки (например, «См. диаграмму 2.3»). Это позволяет сохранять диаграммы управляемыми, не теряя деталей.
При моделировании потоков данных вы также неявно моделируете безопасность данных. Хотя стандартная DFD не показывает протоколы шифрования или аутентификации, она показывает перемещение конфиденциальных данных.
Если поток данных содержит персональную информацию (PII) или финансовую информацию, укажите это в легенде или метках. Например, пометьте поток как «Зашифрованные данные платежа». Это напоминает разработчикам, что к этому каналу должны быть применены конкретные меры безопасности.
Как только диаграмма будет завершена и проверена, она становится чертежом для разработки. Она руководит проектированием базы данных, определением API и компоновкой пользовательского интерфейса. Это гарантирует, что конечный продукт соответствует первоначальным требованиям.
Помните, что инструменты второстепенны по сравнению с пониманием. Независимо от того, используете ли вы цифровую доску или ручку и бумагу, логика остаётся той же. Ценность заключается в чёткости мышления, которую вы вносите в структуру системы.
Следуя описанным выше шагам, вы сможете создать диаграмму потоков данных профессионального уровня, которая будет надёжной опорой для вашей команды проекта. Начинайте с малого, часто проверяйте и постоянно улучшайте. Такой дисциплинированный подход приводит к прочным архитектурным решениям.