 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Проектирование надежной информационной системы требует больше, чем просто программирование; необходимо четкое понимание того, как данные перемещаются через процесс. Диаграмма потока данных (DFD) служит чертежом для этого перемещения. Она визуализирует поток информации между внешними объектами, внутренними процессами и хранилищами данных. Это руководство подробно рассматривает создание эффективных DFD, обеспечивая структурированный, логичный и масштабируемый анализ вашей системы.
Независимо от того, проектируете ли вы новое приложение или проводите аудит существующего, принципы потока данных остаются неизменными. Это пошаговое руководство охватывает анатомию, уровни, этапы создания и лучшие практики, необходимые для построения профессиональных диаграмм без использования конкретных инструментов. Основное внимание уделяется методологии и логике, лежащей в основе визуализации.
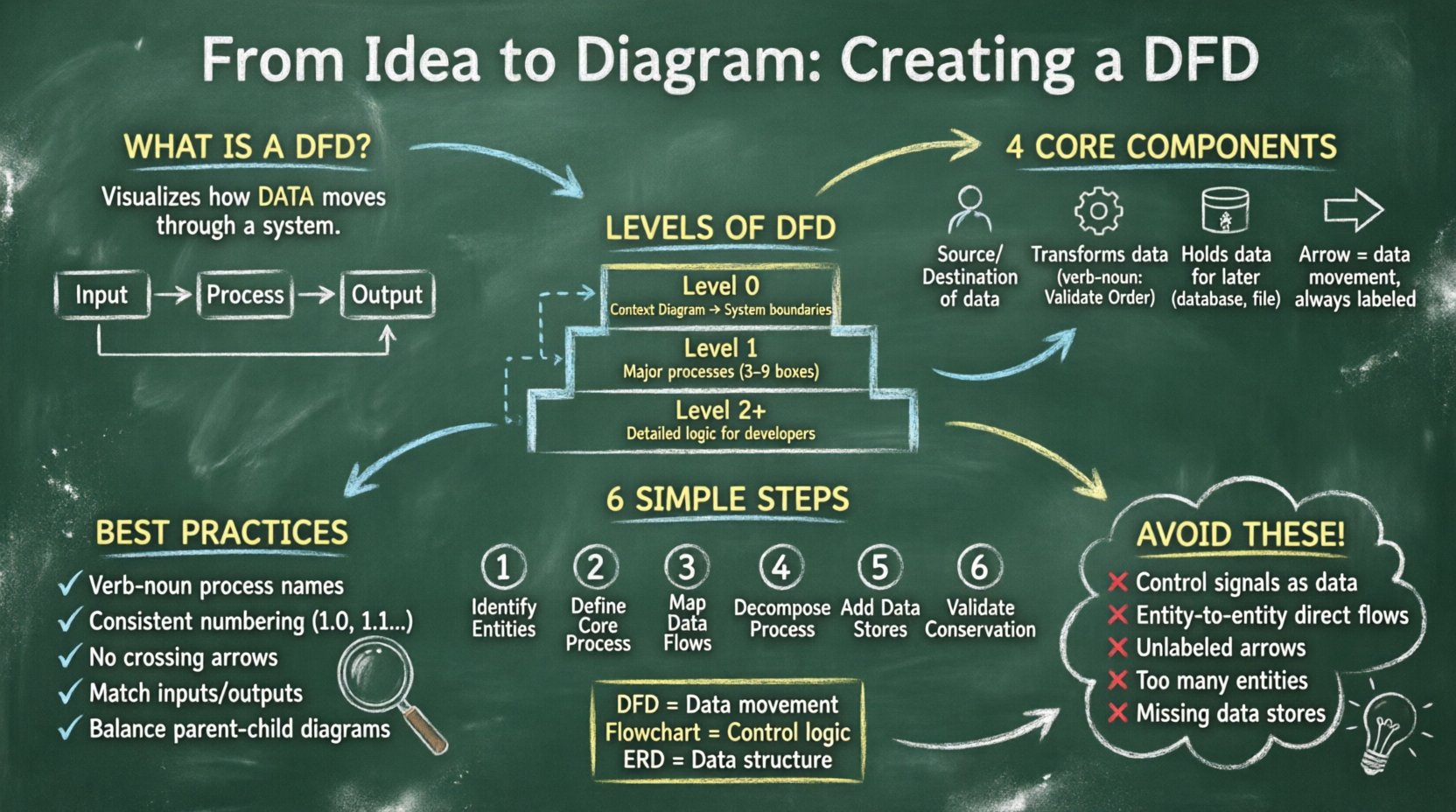
Диаграмма потока данных — это графическое представление потока данных через информационную систему. В отличие от блок-схемы, которая фокусируется на логике управления и шагах принятия решений, DFD фокусируется на самих данных. Она отвечает на вопросы: откуда берутся данные? Что с ними происходит? Куда они идут? И где они хранятся?
DFD являются неотъемлемой частью методологий структурированного анализа и проектирования. Они помогают заинтересованным сторонам визуализировать границы системы и выявлять отсутствующие пути передачи данных или избыточную сложность. Разбивая сложные системы на управляемые уровни, аналитики могут обеспечить, чтобы каждый элемент данных имел определенную цель и конечное назначение.
Для построения корректной DFD необходимо понимать четыре основных символа, используемых на всей диаграмме. Эти символы универсальны и не меняются независимо от используемого стиля нотации (например, Yourdon/DeMarco или Gane/Sarson). Овладение этими компонентами необходимо для точного моделирования.
В следующей таблице кратко описано взаимодействие между этими компонентами:
| Компонент | Функция | Требуется вход | Требуется выход |
|---|---|---|---|
| Внешний объект | Начинает или получает данные | Нет | Да (или нет для приемников) |
| Процесс | Преобразует данные | Да | Да |
| Хранилище данных | Хранит данные | Да (запись) | Да (чтение) |
| Поток данных | Передает данные | Н/Д | Н/Д |
Сложные системы нельзя описать в одном представлении. Чтобы управлять сложностью, диаграммы потоков данных создаются на разных уровнях детализации. Этот метод известен как «декомпозиция». Вы начинаете с высокого уровня обзора и постепенно разбиваете процессы на подпроцессы до тех пор, пока уровень детализации не станет достаточным для реализации.
Диаграмма контекста — это самый высокий уровень абстракции. Она показывает всю систему как один процесс и её взаимодействие с внешними сущностями. Эта диаграмма устанавливает границы системы. Она отвечает на вопрос: «Что представляет собой система в целом?»
На диаграмме уровня 1 единственный процесс из диаграммы контекста разбивается на основные подпроцессы. Это раскрывает внутреннюю структуру системы, не вдаваясь в мелкие детали. Она соединяет основные функциональные области с внешними сущностями.
Диаграммы уровня 2 дополнительно декомпозируют конкретные процессы уровня 1. Этот процесс продолжается до тех пор, пока процессы не станут достаточно простыми, чтобы их могли понять разработчики или операторы. Для очень сложных алгоритмов или финансовых расчетов может потребоваться диаграмма уровня 3 или 4.
| Уровень | Фокус | Сложность | Основная аудитория |
|---|---|---|---|
| Диаграмма контекста | Границы системы | Низкий (1 процесс) | Заинтересованные стороны, руководство |
| Уровень 1 | Основные функциональные области | Средний (3–9 процессов) | Аналитики, менеджеры проектов |
| Уровень 2 и выше | Конкретные подпроцессы | Высокий (подробная логика) | Разработчики, программисты |
Создание диаграммы потоков данных — это систематический процесс. Просто нарисовать фигуры недостаточно; необходимо соблюдать логическую последовательность, чтобы обеспечить целостность данных и их согласованность на всех уровнях.
Начните с перечисления всех источников и пунктов назначения данных. Это пользователи, другие системы или отделы, взаимодействующие с вашей системой. Избегайте размещения внутренних хранилищ данных здесь; держите их отдельно. Каждая сущность должна иметь четкое название, например, «Клиент», «Администратор» или «Шлюз оплаты». Избегайте неопределенных терминов, таких как «Пользователь», если существует несколько типов пользователей.
Для диаграммы контекста нарисуйте один круг, представляющий систему. Обозначьте его названием системы. Это ваша опорная точка. Убедитесь, что все потоки данных, входящие в этот круг и выходящие из него, соответствуют сущностям, определенным на шаге 1.
Нарисуйте стрелки, соединяющие сущности с процессом. Подпишите каждую стрелку конкретными данными, передаваемыми по ней. Вместо «Данные» укажите «Сведения о заказе» или «Счет». Такая конкретность крайне важна на последующих этапах разработки. Убедитесь, что ни одна стрелка не пересекает другую без четкой точки соединения.
Чтобы создать уровень 1, замените один круг системы несколькими процессами. Эти процессы должны представлять основные функции, например, «Проверка заказа», «Обработка оплаты» и «Обновление инвентаря». Соедините эти процессы между собой и с внешними сущностями с использованием ранее выявленных потоков данных.
Определите, где должны храниться данные. Если данные необходимы для последующего процесса или для отчетности, они должны быть помещены в хранилище данных. Подключите хранилище данных к процессу, который в него записывает, и к процессу, который из него читает. Помните, что процесс не может напрямую записывать в другой процесс; при необходимости сохранения данных он должен проходить через хранилище.
Проверьте каждый процесс, чтобы убедиться, что входы равны выходам. Это принцип сохранения данных. Вы не можете создать данные из ничего, и не можете удалить их без записи. Если процесс имеет входы, но не имеет выходов, это «черная дыра». Если процесс имеет выходы, но не имеет входов, это «чудо». Оба случая являются ошибками в модели.
Диаграмма потоков данных — это инструмент коммуникации. Если она трудно читаема, она не выполняет свою основную цель. Соблюдение строгих правил помогает сохранить ясность в команде.
Даже опытные аналитики могут допускать ошибки. Признание этих распространенных ошибок на ранних этапах может значительно сэкономить время на доработке позже.
Часто путают DFD с другими методами диаграммирования. Понимание различий гарантирует, что вы используете правильный инструмент для задачи.
| Тип диаграммы | Фокус | Наилучшее применение |
|---|---|---|
| Диаграмма потоков данных | Передвижение информации | Требования к системе, логика процессов |
| Схема процессов | Логика управления, Решения | Проектирование алгоритмов, Пошаговые процедуры |
| Диаграмма сущность-связь | Структура данных, Связи | Проектирование базы данных, Определение схемы |
В то время как схема процессов показывает порядок операций (если Х, то У), DFD показывает зависимости между преобразованиями данных. DFD не интересуется порядком выполнения, а только потоком информации. Это делает DFD идеальным инструментом для анализа требований к системе до окончательного утверждения логики.
Системы развиваются. Требования меняются, добавляются новые функции. Диаграмма, созданная в начале проекта, может устареть. Крайне важно поддерживать диаграмму в актуальном состоянии по мере развития системы.
Создание диаграммы потока данных — это дисциплина, требующая терпения и точности. Она заставляет думать о данных, а не только о функциях. Следуя структурированному подходу, описанному выше, вы обеспечиваете точность, поддерживаемость и полезность полученной модели на протяжении всего жизненного цикла системы.
Помните, что цель — не создать идеальное изображение сразу. Цель — создать карту, которая направляет команду разработчиков. Начните с диаграммы контекста, проверьте границы, а затем углубитесь в детали. По мере практики процесс декомпозиции станет более интуитивным, а ваши диаграммы станут мощным инструментом коммуникации для вашей команды.
Сохраняйте фокус на данных. Убедитесь, что каждый элемент имеет цель, каждый процесс выполняет преобразование, а каждый хранилище имеет причину для существования. Такой дисциплинированный подход приводит к созданию надежных, масштабируемых систем, соответствующих бизнес-потребностям.