 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











На ранних этапах создания технологической компании ясность — это валюта. Основатели часто сразу приступают к программированию, не полностью визуализируя движение данных в системе. Такой подход часто приводит к накоплению технического долга и сложным сессиям отладки в будущем. Диаграмма потоков данных (DFD) предлагает структурированный способ визуализации движения информации через систему. В этом руководстве рассматривается реальный случай, когда стартап использовал этот метод для уточнения своей архитектуры до написания первого строчки кода.
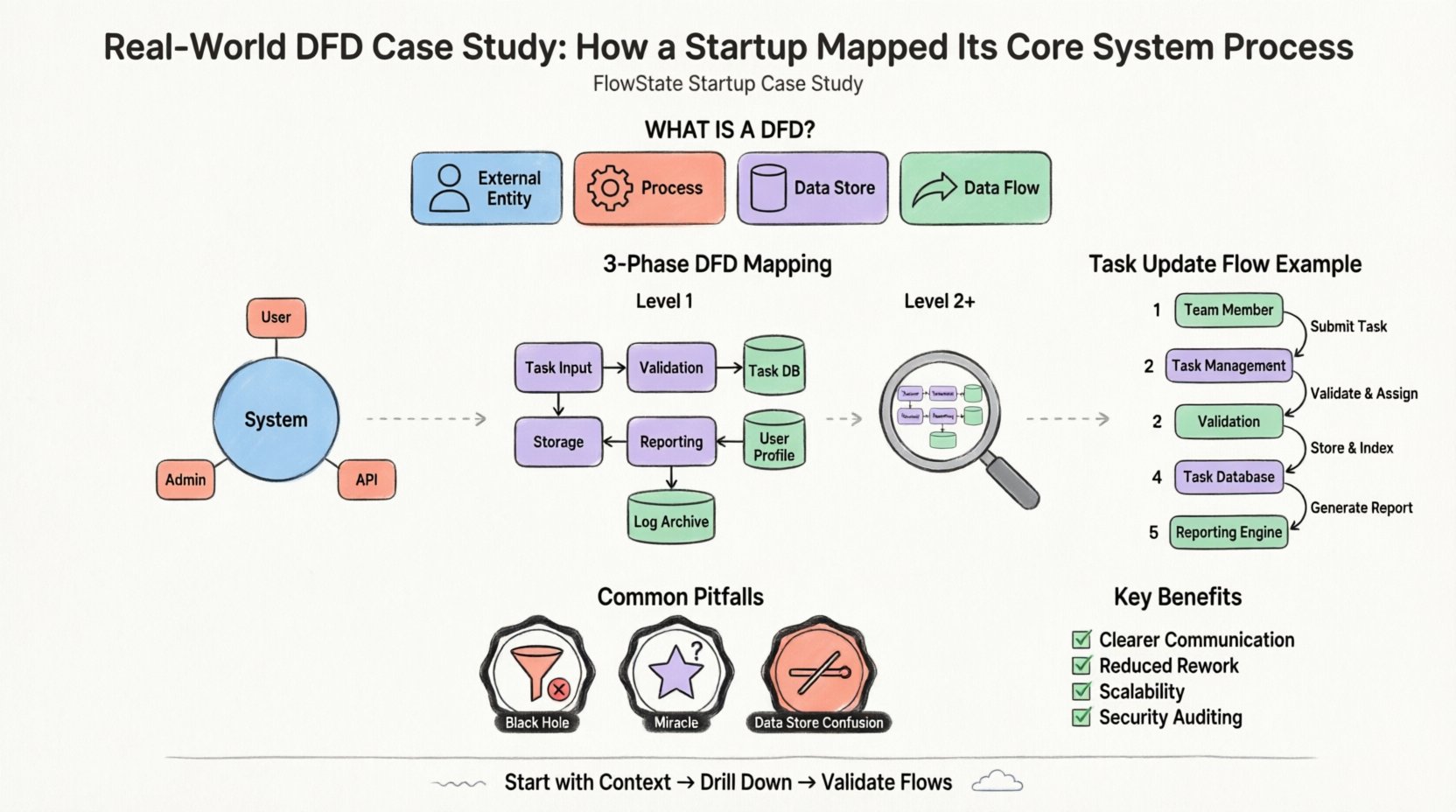
Представим гипотетический стартап под названием «FlowState», который стремится создать платформу для управления проектами для удалённых команд. Основная ценность заключается в распределении задач, обновлениях статуса в реальном времени и автоматизированном отчёте. Основательская команда столкнулась с распространённой проблемой: у них было неясное понимание того, как пользовательские данные должны перемещаться от интерфейса к базе данных и обратно.
Без чёткой схемы команда разработчиков рисковала:
Решением не стали больше совещаний, а лучшее моделирование. Они применили метод диаграммы потоков данных для документирования логики системы. Такой подход позволил им увидеть систему как серию преобразований, а не как статическую базу данных.
Диаграмма потоков данных — это графическое представление движения данных через информационную систему. Она не показывает временные интервалы процессов или логику принятия решений (как алгоритм), а лишь движение данных от источника к месту назначения. Она фокусируется на «что», а не на «как»что, а не на как.
Стандартные компоненты, используемые в этом методе моделирования, включают:
Разбив проект FlowState на эти компоненты, команда смогла выявить узкие места и обеспечить целостность данных до реализации.
Первый шаг при построении системы — диаграмма контекста. Это общий обзор, определяющий границы системы. Она показывает систему как единый процесс и её взаимодействие с внешними сущностями.
Для FlowState граница — это сама программа управления проектами. Все, что находится внутри, является частью системы; все, что находится снаружи, — это сущность. Команда определила три основные внешние сущности:
Команда нарисовала стрелки, чтобы представить входные и выходные потоки. Например:
Этот один диаграмма прояснила границы. Она предотвратила случайное включение функций, таких как «Обработка счетов», если они не входили в состав основной системы на данный момент. Был установлен четкий договор между системой и ее пользователями.
Как только был установлен общий контекст, команде нужно было понять внутреннюю работу системы. Это достигается с помощью декомпозиции на уровне 1. Единственный процесс из диаграммы контекста распадается на подпроцессы.
Система «FlowState» была разделена на логические функциональные группы. Команда определила следующие ключевые процессы:
Ключевым моментом является то, что диаграмма уровня 1 ввела хранилища данных. Это показывает, где информация сохраняется. Команда выделила три основных хранилища:
Явно назвав эти хранилища, разработчики сразу увидели, какая информация должна быть записана в базу данных, а какая — храниться во временной памяти.
После того как структура уровня 1 была реализована, команда проанализировала конкретные потоки данных между процессами и хранилищами. На этом этапе часто выявляются ошибки на ранней стадии.
Давайте проследим движение одного элемента данных: «Изменение статуса задачи».
Этот анализ выявил потенциальную проблему. Команда поняла, что «Система отчетов» запускается вручную каждый раз, когда изменяется задача. Они решили оптимизировать этот процесс, запуская формирование отчета только при установке специфического флага «Статус = Завершено», что снизило нагрузку на систему.
Понимание различий между уровнями диаграмм имеет решающее значение для поддержания ясности по мере роста проекта. В таблице ниже описаны различия.
| Уровень | Фокус | Наилучшее применение |
|---|---|---|
| Контекст (уровень 0) | Граница системы | Общение на высоком уровне с заинтересованными сторонами |
| Уровень 1 | Основные процессы | Архитектурное проектирование и определение границ |
| Уровень 2+ | Детализация подпроцессов | Конкретная логика реализации и отладка |
Даже при чёткой методологии команды часто допускают ошибки при создании этих диаграмм. Команда FlowState столкнулась с несколькими препятствиями и научилась их избегать.
Процесс, который имеет вход, но не имеет выхода, является чёрной дырой. Данные заходят и исчезают. В первоначерском черновике «Обработчик уведомлений» получал данные, но не имел стрелки, выходящей к внешнему сущности. Команда поняла, что забыла определить реальный механизм отправки. Каждый процесс должен иметь выход.
Процесс, который имеет выход, но не имеет входа, является чудом. Это означает, что данные создаются из ниоткуда. Команда изначально имела процесс «Генерация отчёта», который создавал данные без чтения из «Базы данных задач». Они исправили это, добавив поток данных от хранилища к процессу.
Процессы взаимодействуют с хранилищами данных, но сущности — нет. В начале команда провела линию непосредственно от «Члена команды» к «Базе данных задач». Это нарушает правило, согласно которому данные должны проходить через процесс для преобразования или проверки. Все данные, взаимодействующие с хранилищем, должны сначала пройти через процесс.
Одно из самых важных правил методологии DFD — балансировка. Входы и выходы родительского процесса должны соответствовать входам и выходам его дочерней диаграммы (разбиению).
Для FlowState процесс «Управление задачами» на диаграмме уровня 1 имел конкретные входы (данные о задачах) и выходы (обновление статуса). Когда они разбили его на диаграммы уровня 2 (например, «Создание задачи», «Удаление задачи»), они убедились, что совокупные потоки всё ещё соответствуют родительскому процессу. Это гарантирует, что при разбиении не теряются и не создаются данные.
Зачем тратить время на этот этап документирования? Преимущества выходят за рамки первоначального составления схем.
Перед переходом к разработке команда FlowState использовала следующий чек-лист для проверки своей работы.
Переход от концепции к функциональному продукту требует больше, чем просто навыков программирования. Требуется глубокое понимание информационной экосистемы, которую вы создаете. Сопоставив потоки данных, FlowState убедился, что их архитектура была надежной до развертывания.
Этот кейс-стади показывает, что диаграмма потоков данных — это не просто упражнение по рисованию. Это инструмент критического мышления. Он заставляет команду задавать сложные вопросы о происхождении данных, их направлении и способах изменения. Для любой стартап-компании, стремящейся создать надежную систему, затраты времени на этот этап моделирования — это стратегическое преимущество.
Помните, цель — не совершенство в первом черновике. Цель — ясность. Начните с контекста, переходите к процессам и проверяйте потоки. Такой дисциплинированный подход приводит к системам, которые проще поддерживать, защищать и масштабировать.
Когда вы начнете собственное проектирование, помните об этих принципах. Сосредоточьтесь на перемещении данных, уважайте границы и проверяйте каждый соединение. Ваш будущий вы скажет вам спасибо за ясность, установленную сегодня.