 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Projektowanie solidnego systemu informacyjnego wymaga więcej niż tylko programowania; wymaga jasnego zrozumienia, jak dane poruszają się przez proces. Diagram przepływu danych (DFD) pełni rolę projektu tego przepływu. Wizualizuje przepływ informacji między jednostkami zewnętrznymi, wewnętrznymi procesami i magazynami danych. Ten przewodnik zapewnia szczegółowe omówienie tworzenia skutecznych DFD, zapewniając, że analiza systemu będzie zorganizowana, logiczna i skalowalna.
Niezależnie od tego, czy projektujesz nową aplikację, czy audytujesz istniejącą, zasady przepływu danych pozostają niezmienne. Ten przewodnik obejmuje anatomię, poziomy, kroki tworzenia oraz najlepsze praktyki wymagane do tworzenia profesjonalnych schematów bez użycia konkretnych narzędzi. Nacisk położony jest na metodologię oraz logikę stojącą za wizualizacją.
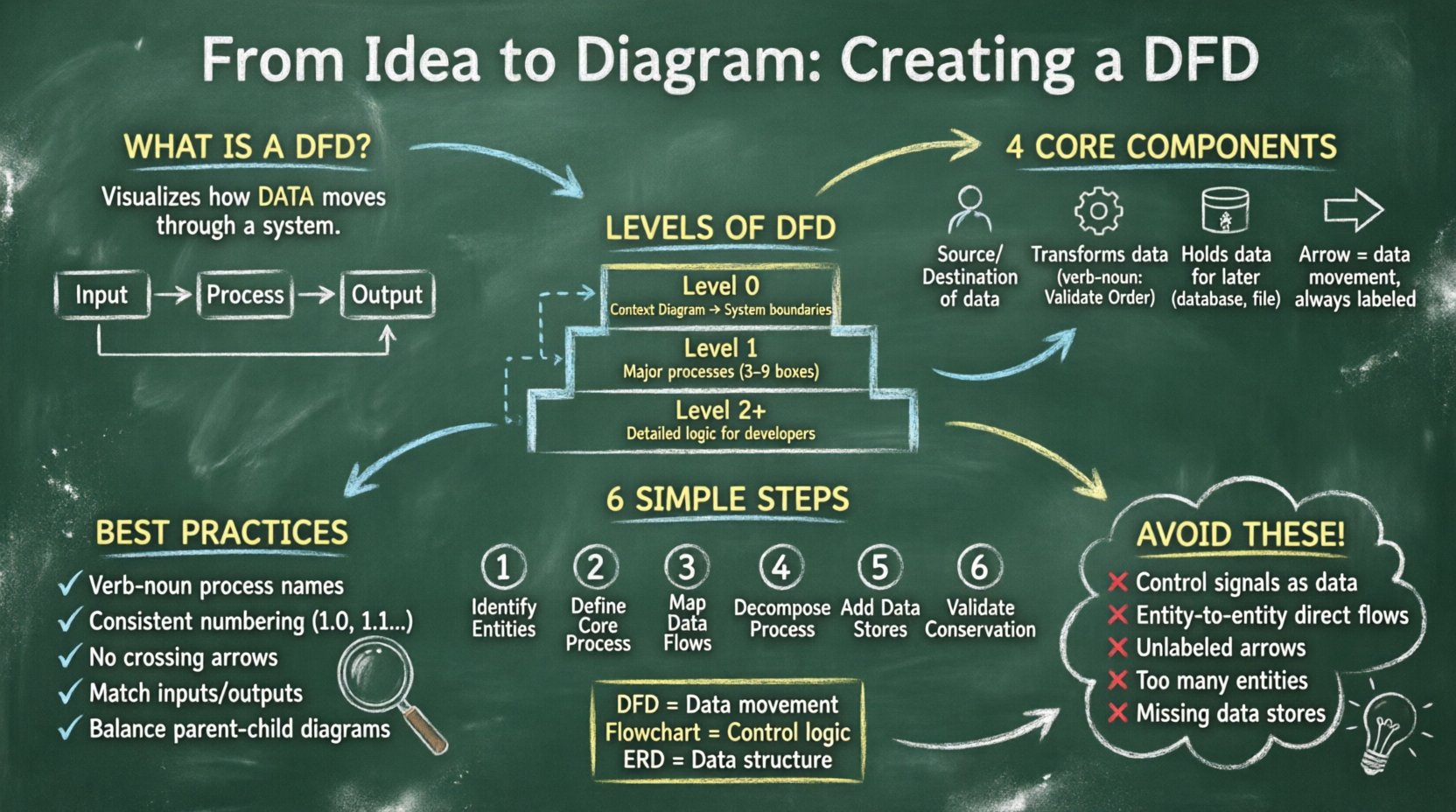
Diagram przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. W przeciwieństwie do schematu blokowego, który skupia się na logice sterowania i krokach podejmowania decyzji, DFD skupia się na samych danych. Odpowiada na pytania: skąd pochodzą dane? Co z nimi dzieje się? Dokąd idą? I gdzie są przechowywane?
DFD są nieodłącznym elementem metodologii analizy i projektowania strukturalnego. Pomagają stakeholderom wizualizować granice systemu oraz identyfikować brakujące ścieżki danych lub nadmiarową złożoność. Przez rozkładanie skomplikowanych systemów na zarządzalne warstwy analitycy mogą zapewnić, że każdy fragment danych ma zdefiniowane przeznaczenie i cel.
Aby stworzyć poprawny DFD, należy zrozumieć cztery podstawowe symbole używane w całym schemacie. Te symbole są uniwersalne i nie zmieniają się niezależnie od stylu notacji (takiej jak Yourdon/DeMarco lub Gane/Sarson). Opanowanie tych komponentów jest kluczowe dla dokładnego modelowania.
Poniższa tabela podsumowuje interakcje między tymi komponentami:
| Komponent | Funkcja | Wymagane dane wejściowe | Wymagane dane wyjściowe |
|---|---|---|---|
| Jednostka zewnętrzna | Zaczyna lub odbiera dane | Nie | Tak (lub nie dla ujść) |
| Proces | Przekształca dane | Tak | Tak |
| Magazyn danych | Zachowuje dane | Tak (Zapis) | Tak (Odczyt) |
| Przepływ danych | Przesyła dane | N/D | N/D |
Złożone systemy nie mogą być opisane w jednym widoku. Aby zarządzać złożonością, DFD tworzy się na różnych poziomach szczegółowości. Ta technika nazywa się „rozkładaniem”. Zaczynasz od ogólnego przeglądu na najwyższym poziomie i stopniowo rozkładasz procesy na podprocesy, aż osiągniesz poziom szczegółowości wystarczający do implementacji.
Diagram kontekstowy to najwyższy poziom abstrakcji. Pokazuje cały system jako pojedynczy proces oraz jego interakcje z zewnętrznymi jednostkami. Ten diagram ustala granice systemu. Odpowiada na pytanie: „Co to jest system jako całość?”
Na diagramie poziomu 1 pojedynczy proces z diagramu kontekstowego jest rozwinięty na główne podprocesy. Pokazuje to strukturę wewnętrzną systemu bez wnikania w drobne szczegóły. Łączy główne obszary funkcjonalne z jednostkami zewnętrznymi.
Diagramy poziomu 2 dalsze rozkładają konkretne procesy z poziomu 1. Proces ten kontynuuje się, aż procesy będą wystarczająco proste, aby mogły być zrozumiałe przez programistów lub operatorów. Diagram poziomu 3 lub 4 może być konieczny dla bardzo złożonych algorytmów lub obliczeń finansowych.
| Poziom | Skupienie | Złożoność | Główna grupa docelowa |
|---|---|---|---|
| Diagram kontekstowy | Granice systemu | Niska (1 proces) | Uczestnicy, zarządzanie |
| Poziom 1 | Główne obszary funkcjonalne | Średnia (3-9 procesów) | Analitycy, menedżerowie projektów |
| Poziom 2+ | Konkretne podprocesy | Wysoka (szczegółowa logika) | Programiści, programowani |
Tworzenie DFD to proces systematyczny. Nie wystarczy po prostu narysować kształtów; należy przestrzegać logicznego ciągu, aby zapewnić integralność danych i spójność na wszystkich poziomach.
Zacznij od wyliczenia wszystkich źródeł i miejsc docelowych danych. Są to użytkownicy, inne systemy lub działы, które oddziałują z Twoim systemem. Unikaj umieszczania wewnętrznych magazynów danych tutaj; trzymaj je osobno. Każda jednostka powinna mieć jasne oznaczenie, takie jak „Klient”, „Administrator” lub „Brama płatności”. Unikaj nieprecyzyjnych określeń takich jak „Użytkownik”, jeśli istnieje więcej niż jeden rodzaj użytkowników.
W diagramie kontekstowym narysuj pojedynczy okrąg reprezentujący system. Oznacz go nazwą systemu. To jest Twój punkt odniesienia. Upewnij się, że wszystkie przepływy danych wchodzące i wychodzące z tego okręgu odpowiadają jednostkom zidentyfikowanym w Kroku 1.
Narysuj strzałki łączące jednostki z procesem. Oznacz każdą strzałkę konkretnymi danymi przesyłanymi. Zamiast pisać „Dane”, napisz „Szczegóły zamówienia” lub „Faktura”. Ta szczegółowość jest kluczowa dla późniejszych etapów rozwoju. Upewnij się, że żadna strzałka nie przecina innej bez jasnego punktu połączenia.
Aby stworzyć poziom 1, zastąp pojedynczy okrąg systemu wieloma procesami. Te procesy powinny reprezentować główne funkcje, takie jak „Weryfikacja zamówienia”, „Przetwarzanie płatności” i „Aktualizacja magazynu”. Połącz te procesy ze sobą oraz z jednostkami zewnętrznymi przy użyciu wcześniej zidentyfikowanych przepływów danych.
Zidentyfikuj, gdzie dane muszą być zapisane. Jeśli dane są potrzebne dla późniejszego procesu lub do raportowania, muszą trafić do magazynu danych. Połącz magazyn danych z procesem, który do niego zapisuje, oraz z procesem, który z niego odczytuje. Pamiętaj, że proces nie może bezpośrednio zapisywać do innego procesu; musi przejść przez magazyn, jeśli potrzebna jest trwałość.
Sprawdź każdy proces, aby upewnić się, że wejścia są równe wyjściom. Jest to zasada zachowania danych. Nie możesz stworzyć danych z niczego, ani usunąć ich bez zapisu. Jeśli proces ma wejścia, ale nie ma wyjść, to „czarna dziura”. Jeśli ma wyjścia, ale nie ma wejść, to „czarodziejstwo”. Oba są błędami w modelu.
DFD to narzędzie komunikacji. Jeśli jest trudne do odczytania, nie spełnia swojego podstawowego celu. Przestrzeganie rygorystycznych zasad pomaga utrzymać przejrzystość w całej drużynie.
Nawet doświadczeni analitycy mogą popełniać błędy. Wczesne rozpoznanie tych typowych błędów może zaoszczędzić znaczne prace nad poprawką w przyszłości.
Często myli się DFD z innymi metodami rysowania schematów. Zrozumienie różnicy zapewnia, że używasz odpowiedniego narzędzia do zadania.
| Typ schematu | Skupienie | Najlepiej używane do |
|---|---|---|
| Schemat przepływu danych | Ruch informacji | Wymagania systemu, logika procesu |
| Schemat blokowy | Logika sterowania, Decyzje | Projektowanie algorytmów, procedury krok po kroku |
| Schemat relacji jednostek | Struktura danych, Relacje | Projektowanie bazy danych, definicja schematu |
Podczas gdy schemat blokowy pokazuje kolejność operacji (jeśli X, to Y), DFD pokazuje zależności między przekształceniami danych. DFD nie interesuje się kolejnością wykonywania, tylko przepływem informacji. Dzięki temu DFD jest idealny do analizy wymagań systemu przed ustaleniem logiki.
Systemy ewoluują. Wymagania się zmieniają, a do systemu dodawane są nowe funkcje. Schemat DFD stworzony na początku projektu może się wygryźć. Kluczowe jest utrzymywanie schematu wraz z rozwojem systemu.
Tworzenie diagramu przepływu danych to dyscyplina wymagająca cierpliwości i precyzji. Zmusza Cię do myślenia o danych, a nie tylko o funkcjach. Przestrzegając strukturalnego podejścia przedstawionego powyżej, zapewnisz, że ostateczny model będzie dokładny, łatwy w utrzymaniu i przydatny przez cały cykl życia systemu.
Pamiętaj, że celem nie jest stworzenie idealnego obrazu od razu. Chodzi o stworzenie mapy, która prowadzi zespół programistów. Zacznij od diagramu kontekstowego, zwaliduj granice, a następnie przejdź do szczegółów. W miarę ćwiczeń proces dekompozycji stanie się bardziej intuicyjny, a Twoje diagramy będą skutecznym narzędziem komunikacji w Twoim zespole.
Zachowaj skupienie na danych. Upewnij się, że każdy strzałka ma cel, każdy proces przeprowadza przekształcenie, a każdy magazyn ma powód do istnienia. To dyscyplinowane podejście prowadzi do systemów odpornych, skalowalnych i zgodnych z potrzebami biznesowymi.