 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Metoda Agile zapowiada elastyczność, szybką reakcję i ciągłe doskonalenie. Jednak rzeczywistość często wiąże się z niepowodzeniami. Nieudany sprint to nie zjawisko wyjątkowe, lecz punkt danych. Zrozumienie, jak zespół radzi sobie z porażką, decyduje o długoterminowym sukcesie bardziej niż świętowanie idealnych cykli.
Ten artykuł analizuje konkretny przypadek, w którym zespół deweloperski całkowicie nie osiągnął celów sprintu. Przeanalizujemy czynniki techniczne i ludzkie, które weszły w grę, proces retrospekcji wykorzystany do diagnozy problemu oraz konkretne kroki podjęte w celu odzyskania prędkości i jakości.
Aby zrozumieć porażkę, najpierw musimy zrozumieć strukturę. Organizacja działa według modelu zespołu wielodyscyplinarnego. Zespół składa się z pięciu programistów, jednego właściciela produktu oraz dedykowanego testera. Praca jest organizowana w cyklach dwutygodniowych.
Zespół wykorzystywał fizyczny i cyfrowy tablicę śledzenia do zarządzania przepływem. Historie były przenoszone z Zagłębienia do W trakcie a na końcu do Zrobione. Celem było spójne dostarczanie wartości bez kompromitowania jakości kodu.
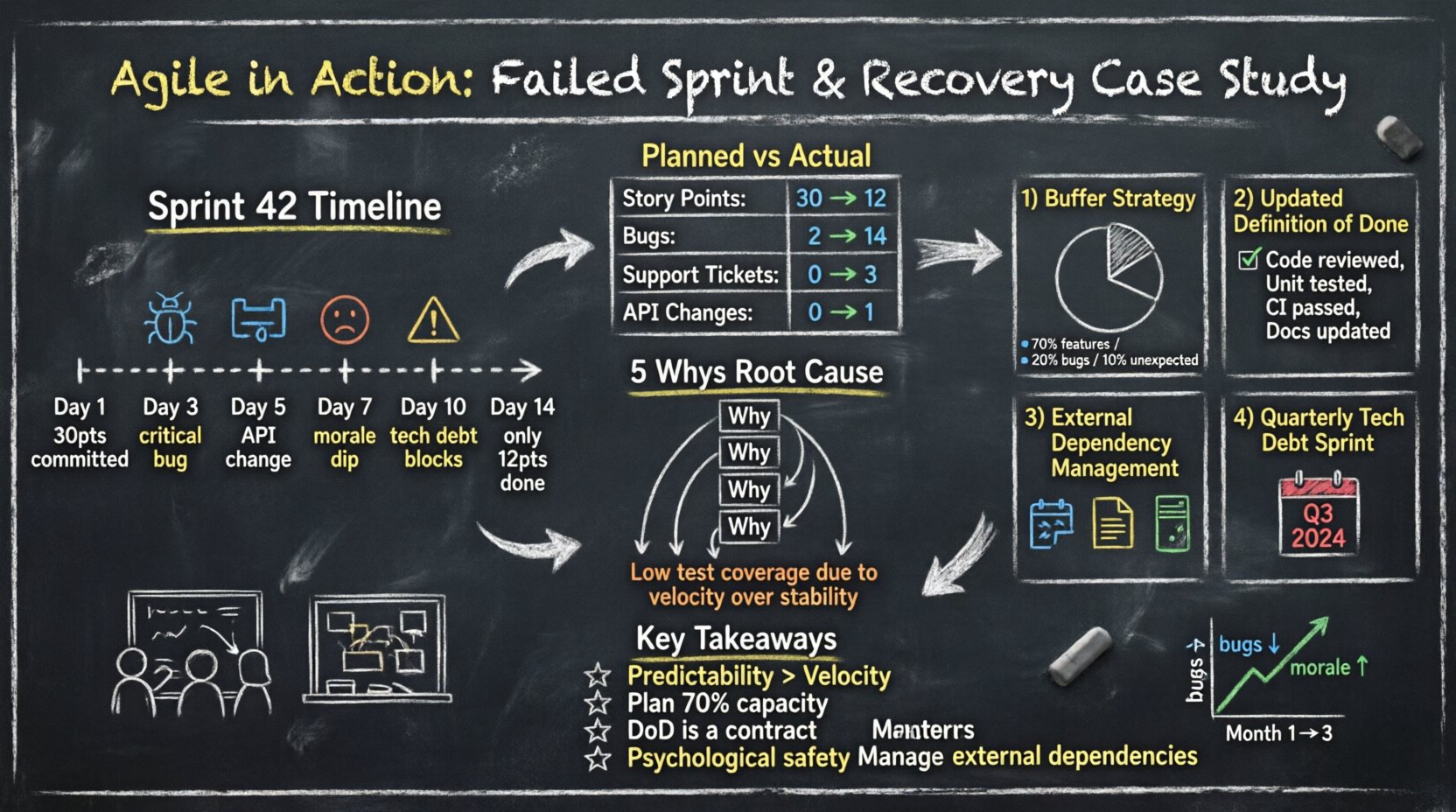
Sprint 42 rozpoczął się z dużym impulsem. Zespół wyciągnął 30 punktów historii z listy zadań. Już w trzeci dzień tempo wydawało się stabilne. W piątek pojawiły się trudności. W dziesiąty dzień zespół zrozumiał, że nie uda mu się ukończyć założonej pracy.
Porażka nie była spowodowana jednym katastrofalnym zdarzeniem. Była to kumulacja wielu problemów, które stopniowo osłabiały zdolność zespołu.
Liczby mówią jasniej niż uczucia. Poniższa tabela ilustruje różnicę między zaplanowanym wysiłkiem a rzeczywistym wynikiem.
| Kategoria | Zaplanowane | Rzeczywiste | Różnica |
|---|---|---|---|
| Ukończone punkty historii | 30 | 12 | -18 |
| Znalezione błędy (w trakcie sprintu) | 2 | 14 | +12 |
| Obsłużone zgłoszenia pomocy | 0 | 3 | +3 |
| Zmiany zależności zewnętrznych | 0 | 1 | +1 |
Te dane ujawniają istotne przesunięcie zasobów. To, co zaczęło się jako praca nad rozwojem, przekształciło się w utrzymanie i zarządzanie kryzysami.
Przypisywanie winy osobom nie rozwiązuje problemów systemowych. Zespół przeprowadził analizę przyczyn głębokich bez oskarżania, aby zidentyfikować ukryte problemy.
Aby zgłębić problem, zespół zastosowałmetodę pięciu dlaczegodo problemu nieprzestrzegania terminów.
Głównym problemem nie była dokładność planowania; była to zrównoważona praktyka inżynierska.
Retrospektywa to silnik poprawy w podejściu agilnym. Jednak nieudany sprint wymaga specyficznej formy retrospektywy. Standardowe formaty często wydają się być tylko sprawdzaniem pól. Ten moment wymagał bezpieczeństwa psychicznego i głębokiego zastanawiania się.
Zanim odbyła się spotkanie, właściciel produktu zebrali dane. Zespół został poproszony o samodzielne rozważenie, co poszło dobrze, a co nie. Zapewniło to cichym członkom zespołu czas na przemyślenie swoich myśli.
Zespół omawiał koncepcjęplanowania pojemności. Zrozumieli, że zadeklarowali 100% swojego czasu na nowe funkcje. Nie było żadnego zapasu na nieuniknione przerywania, które występują w środowiskach produkcyjnych.
Również zajęli sięDefinicją Gotowości. Obecnie „Gotowe” oznaczało „Kod napisany”. Nie obejmowało to „Kod przeszedł recenzję” ani „Testy napisane”. Ta różnica powodowała zator na końcu sprintu.
Znajomość problemu to tylko połowa walki. Plan odbudowy wymagał zmian w przepływie pracy, oczekiwań oraz standardów technicznych.
Zespół przestał zadeklarowywać 100% swoich dostępnych godzin. Wprowadziłstrategię buforowania.
Ta zmiana zmniejszyła presję, by dostarczyć idealne liczby, i pozwoliła na realistyczne radzenie sobie z przerywaniem.
Zespół uaktualnił swójlistę kontrolną DoD. Historia nie mogła przejść do Gotowebez spełnienia tych kryteriów:
Zapobiegło niewidzialnemu gromadzeniu długu technicznego. Zapewniło, że dostarczony produkt był naprawdę użyteczny.
Kanały komunikacji z zewnętrznymi dostawcami zostały uregulowane. Zespół teraz wymaga:
Zespół zgodził się poświęcać jeden sprint co kwartał specjalnie redukcji długu technicznego. To zapobiega skumulowanemu efektowi złego kodu. Wskazuje inwestorom, że stabilność to cecha produktu, a nie pożądane dopiero po zakończeniu.
Zmiany zostały natychmiast wdrożone w Sprint 43. Odzyskanie nie było natychmiastowe, ale kierunek zmienił się.
Zespół nie dążył do powrotu do poprzedniej prędkości 30 punktów. Dążył do przewidywalności. Lepiej zaangażować się w mniej i stale dostarczać, niż przesadzić i zawieść.
Aby zapewnić, że odzyskanie trwa, zespół śledził konkretne metryki przez następne trzy miesiące.
| Tydzień | Cel Sprintu osiągnięty | Liczba błędów | Moral zespołu (1-5) |
|---|---|---|---|
| Miesiąc 1 | Tak | 12 | 3 |
| Miesiąc 2 | Tak | 8 | 4 |
| Miesiąc 3 | Tak | 5 | 5 |
Dane pokazują wyraźną korelację między zmianami procesu a zdrowiem zespołu. Mniejsza liczba błędów prowadziła do mniejszego stresu, co poprawiło moralny.
Niepowodzenie jest nauczycielem. Oto lekcje wynikające z tego przypadku, które mają zastosowanie w każdym środowisku agilnym.
Szybkość bez stabilności to iluzja. Zespoły powinny stawiać przede wszystkim na spójne dostarczanie, a nie tylko na ilość wyników. Stakeholderzy ufają zespołom, które spełniają swoje obietnice, nawet jeśli te obietnice są mniejsze.
Zawsze planuj na nieoczekiwane. Jeśli masz 100 godzin dostępnych, planuj 70 godzin pracy. Pozostały czas pochłania nieuniknioną tarcie związane z rozwojem oprogramowania.
DoD to nie sugestia. To umowa między zespołem a właścicielem produktu. Jeśli historia nie spełnia DoD, nie jest gotowa do wypuszczenia.
Kiedy coś pójdzie nie tak, zespół musi czuć się bezpiecznie, by móc mówić o tym. Jeśli członkowie boją się kary, ukryją problemy, aż staną się kryzysami.
Oprogramowanie nie istnieje w próżni. Zależności od usług zewnętrznych muszą być zarządzane z taką samą starannością, jak kod wewnętrzny.
Wiele zespołów próbuje naprawić niepowodzenie, pracując intensywniej. To powszechny błąd. Poniższe działania należy unikać podczas okresu odzyskiwania.
Celem agilności nie jest jedynie wysyłanie kodu, ale budowanie systemu, który może bezustannie wysyłać kod. Trwały temp jest fundamentem tego systemu.
Po odzyskaniu zespół ustanowił rytm ciągłego doskonalenia. Co dwa tygodnie przeglądają nie tylko sprint, ale także stan przepływu pracy. Zadają pytania takie jak:
Ta ciągła kontrola zapobiega temu, by małe problemy ponownie stały się dużymi niepowodzeniami.
Przejrzystość wobec stakeholderów jest kluczowa. Gdy sprint się nie powiedzie, komunikuj jak najszybciej. Wyjaśnij skutki, przyczynę i plan działania. To buduje zaufanie.
Stakeholderzy często traktują nieudany sprint jako niekompetencję. Gdy jest on wyjaśniony jako punkt danych do poprawy, staje się dowodem dojrzałości zawodowej. Preferują zespół, który przyznaje problem i go naprawia, przed zespołem, który ukrywa problem.
Niepowodzenia są normalne. Stosunek 10% niepowodzeń jest często akceptowalny w zależności od dziedziny. Stałe wysokie wskaźniki niepowodzeń wskazują na problem systemowy w planowaniu.
Zazwyczaj nie. Zatrzymanie sprintu marnuje czas już spędzony. Lepiej zakończyć to, co można zakończyć, i rozpocząć kolejny cykl.
Tak, jeśli Twoja prędkość została sztucznie podniesiona przez nadmierną zobowiązań. Obniżenie jej do rzeczywistości poprawia dokładność i przewidywalność.
Krótkoterminowe naprawy są możliwe, ale długoterminowe uzdrowienie wymaga zmiany procesu. W przeciwnym razie niepowodzenie się powtórzy.
Agile to podróż dostosowania. Nieudany sprint to nie koniec drogi; jest to wskazówka wskazująca na lepsze praktyki. Analizując niepowodzenie głęboko i wprowadzając zmiany strukturalne, zespoły mogą wyjść silniejsze i bardziej odporności.