 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Na wczesnym etapie budowy firmy technologicznej jasność jest walutą. Założyciele często od razu wchodzą w kodowanie, nie w pełni wizualizując ruch danych w tle. Ten podejście często prowadzi do zadłużenia technicznego i skomplikowanych sesji debugowania w przyszłości. Diagram przepływu danych (DFD) oferuje strukturalny sposób wizualizacji ruchu informacji przez system. Niniejszy przewodnik bada rzeczywisty przypadek, w którym startup wykorzystał tę metodologię, aby wyjaśnić architekturę systemu, zanim napisano jedno zdanie kodu.
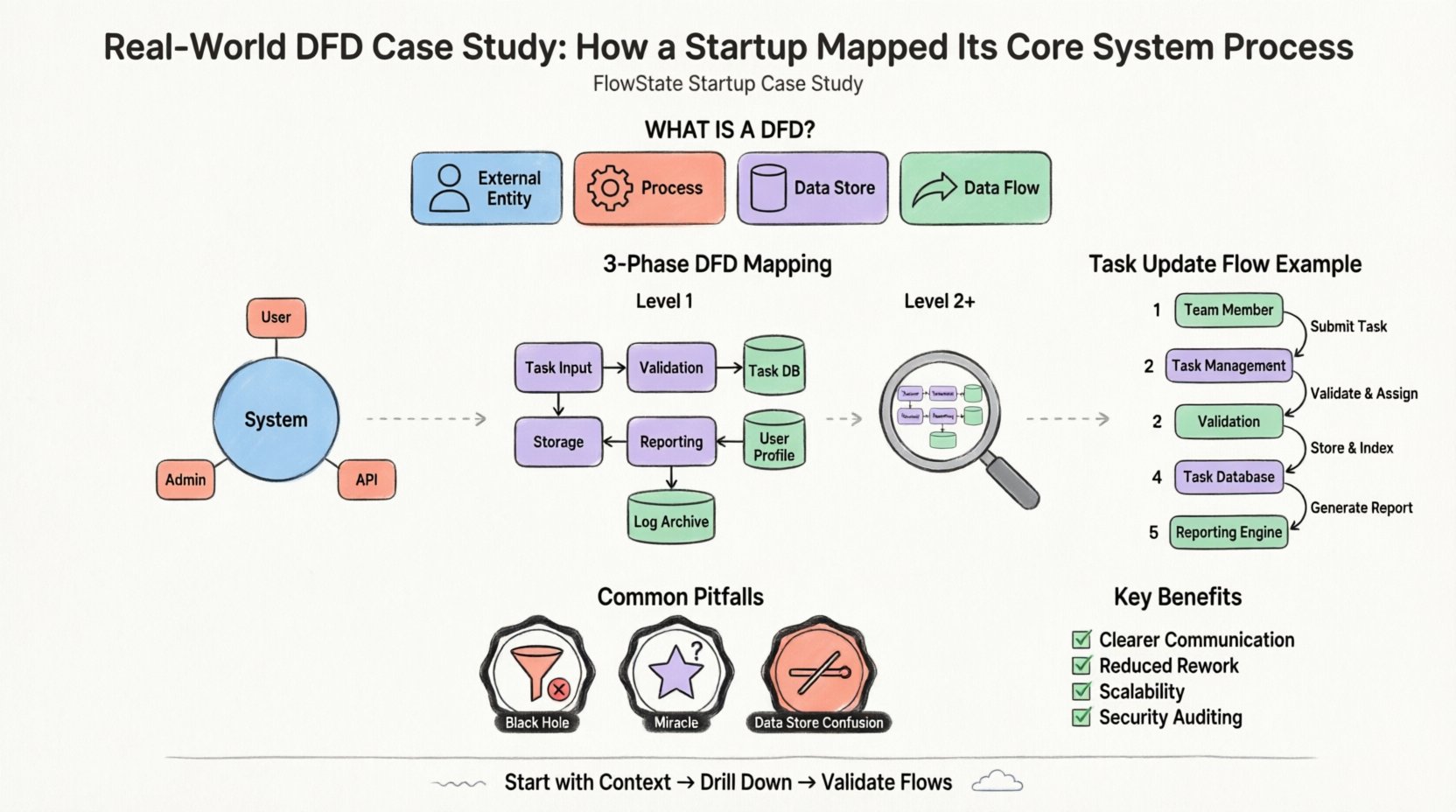
Wyobraźmy sobie hipotetyczny startup o nazwie „FlowState”, który ma na celu stworzenie platformy do zarządzania projektami dla zespołów zdalnych. Kluczowa wartość oferowana przez startup obejmuje przypisywanie zadań, aktualizacje statusu w czasie rzeczywistym oraz automatyczne raportowanie. Zespół założycielski stoczył się przed typowym problemem: miał niejasne zrozumienie, jak dane użytkownika powinny przemieszczać się od interfejsu do bazy danych i z powrotem.
Bez jasnej mapy zespół deweloperski ryzykował:
Rozwiązaniem nie były kolejne spotkania, ale lepsze modelowanie. Zespół przyjął metodę Diagramu Przepływu Danych w celu dokumentowania logiki systemu. Ta metoda pozwoliła im zobaczyć system jako serię przekształceń, a nie statyczną bazę danych.
Diagram przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. Nie pokazuje czasu działania procesów ani logiki podejmowania decyzji (jak algorytm), ale raczej ruch danych od źródła do celu. Skupia się na tym, co, a nie na tym, jak.
Standardowe składniki używane w tej metodzie modelowania to:
Rozkładając projekt FlowState na te składniki, zespół mógł zidentyfikować węzły zatorów i zapewnić integralność danych przed wdrożeniem.
Pierwszym krokiem w mapowaniu systemu jest Diagram kontekstowy. Jest to widok najwyższego poziomu, który definiuje granice systemu. Pokazuje system jako pojedynczy proces oraz sposób jego interakcji z jednostkami zewnętrznymi.
Dla FlowState granica to sama aplikacja do zarządzania projektami. Wszystko wewnątrz należy do systemu; wszystko poza nią to jednostka. Zespół zidentyfikował trzy główne jednostki zewnętrzne:
Zespół narysował strzałki, aby przedstawić strumienie wejściowe i wyjściowe. Na przykład:
Ten jeden diagram wyjaśnił zakres. Zapobiegł przypadkowemu włączeniu funkcji takich jak „Przetwarzanie rozliczeń”, jeśli nie były one częścią systemu głównego w tym czasie. Ustalił jasny kontrakt między systemem a jego użytkownikami.
Gdy ustalono ogólny kontekst, zespół musiał zrozumieć działanie wewnętrzne. Działa to poprzez rozkład poziomu 1. Jedno proces z diagramu kontekstowego jest rozbijane na podprocesy.
System „FlowState” został podzielony na logiczne grupy funkcjonalne. Zespół zidentyfikował następujące kluczowe procesy:
Kluczowe jest to, że diagram poziomu 1 wprowadził magazyny danych. Pokazuje on, gdzie informacje są trwale przechowywane. Zespół zidentyfikował trzy główne magazyny:
Poprzez jawne oznaczenie tych magazynów, programiści od razu widzieli, które dane muszą być zapisane w bazie danych, a które przechowywane w pamięci tymczasowej.
Po ustaleniu struktury poziomu 1 zespół przeanalizował konkretne przepływy danych między procesami i magazynami. Krok ten często pozwala wyłapać błędy na wczesnym etapie.
Prześledźmy ruch pojedynczego punktu danych: „Zmiana statusu zadania.”
Ten przebieg ujawnił potencjalny problem. Zespół zrozumiał, że „Silnik raportów” jest aktywizowany ręcznie za każdym razem, gdy zadanie się zmienia. Postanowili go zoptymalizować, aktywując proces raportowania tylko wtedy, gdy ustawiony jest określony flaga „Status = Zakończone”, co zmniejszyło obciążenie systemu.
Zrozumienie różnicy między poziomami diagramów jest kluczowe dla utrzymania przejrzystości w miarę wzrostu projektu. Poniższa tabela przedstawia różnice.
| Poziom | Skupienie | Najlepiej używane do |
|---|---|---|
| Kontekst (poziom 0) | Granica systemu | Komunikacja na wysokim poziomie z zaangażowanymi stronami |
| Poziom 1 | Główne procesy | Planowanie architektury i definiowanie zakresu |
| Poziom 2+ | Szczegóły podprocesów | Specyficzna logika implementacji i debugowanie |
Nawet przy jasnej metodologii zespoły często popełniają błędy podczas tworzenia tych schematów. Zespół FlowState napotkał kilka przeszkód i nauczył się ich unikać.
Proces, który ma wejście, ale nie ma wyjścia, to czarna dziura. Dane wchodzą i znikają. W pierwszym szkicu „Obsługa powiadomień” otrzymywała dane, ale nie miała strzałki wychodzącej do zewnętrznej jednostki. Zespół zrozumiał, że zapomniał zdefiniować rzeczywistego mechanizmu wysyłania. Każdy proces musi mieć wyjście.
Proces, który ma wyjście, ale nie ma wejścia, to cud. Oznacza to, że dane powstają z niczego. Zespół początkowo miał proces „Generuj raport”, który tworzył dane bez odczytu z „Bazy danych zadań”. Poprawili to, dodając przepływ danych z magazynu do procesu.
Procesy interagują z magazynami danych, ale jednostki nie. Na początku zespół narysował linię bezpośrednio od „Członka zespołu” do „Bazy danych zadań”. Narusza to zasadę, że dane muszą przejść przez proces, aby zostać przekształcone lub zweryfikowane. Wszystkie dane dotykające magazynu muszą najpierw przejść przez proces.
Jedną z najważniejszych zasad w metodologii DFD jest zrównoważenie. Wejścia i wyjścia procesu nadrzędnego muszą odpowiadać wejściom i wyjściom jego diagramu potomka (rozkładu).
Dla FlowState proces „Zarządzanie zadaniami” na diagramie poziomu 1 miał określone wejścia (Dane zadania) i wyjścia (Aktualizacja stanu). Gdy rozłożyli go na diagramy poziomu 2 (np. „Utwórz zadanie”, „Usuń zadanie”), upewnili się, że połączone przepływy nadal odpowiadają procesowi nadrzędnemu. Zapewnia to, że podczas rozkładu nie tracimy ani nie tworzymy danych.
Dlaczego inwestować czas w ten etap dokumentacji? Korzyści sięgają poza początkowe mapowanie.
Zanim przeszli do rozwoju, zespół FlowState użył poniższej listy kontrolnej do weryfikacji swojej pracy.
Przejście od koncepcji do funkcjonalnego produktu wymaga więcej niż tylko umiejętności programowania. Wymaga głębokiego zrozumienia ekosystemu informacji, który budujesz. Przez mapowanie przepływów danych FlowState zapewnił, że ich architektura była solidna przed wdrożeniem.
Ten przypadek pokazuje, że schemat przepływu danych to nie tylko ćwiczenie rysunkowe. To narzędzie myślenia krytycznego. Zmusza zespół do zadawania trudnych pytań o pochodzenie danych, ich kierunek i sposób zmian. Dla każdej stартupu, która chce stworzyć solidny system, inwestycja czasu w tym etapie modelowania to przewaga strategiczna.
Pamiętaj, celem nie jest doskonałość w pierwszym szkicu. Celem jest jasność. Zaczynaj od kontekstu, przechodź do procesów, a następnie weryfikuj przepływy. Ta dyscyplinowana metoda prowadzi do systemów łatwiejszych w utrzymaniu, bezpieczniejszych i skalowalnych.
Gdy zaczynasz mapowanie własnego projektu, pamiętaj o tych zasadach. Skup się na przepływie danych, szanuj granice i weryfikuj każdą połączenie. Przyszły Ty podziękuje Ci za jasność, którą dziś stworzyłeś.