 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











软件项目常常并非因为代码质量差而失败,而是因为需求被误解。当团队在没有清晰的数据流动图的情况下直接进入设计或开发阶段时,结果往往是技术债务和范围蔓延。这时,数据流图(DFD)的价值便凸显出来。它作为一种视觉语言,弥合了业务利益相关者与技术架构师之间的鸿沟。
数据流图是信息系统中数据流动的图形化表示。与侧重于控制逻辑和决策点的流程图不同,数据流图关注的是信息流。它展示了数据如何进入系统、如何被转换、存储在何处,以及如何离开。在需求收集的背景下,这种区分至关重要,它将讨论的重点从“系统做什么”转向系统做什么转向系统处理哪些数据.
本指南探讨了数据流图的机制、优势及其战略应用。我们将分析它们如何澄清模糊性、支持验证,并确保最终产品与业务需求保持一致。
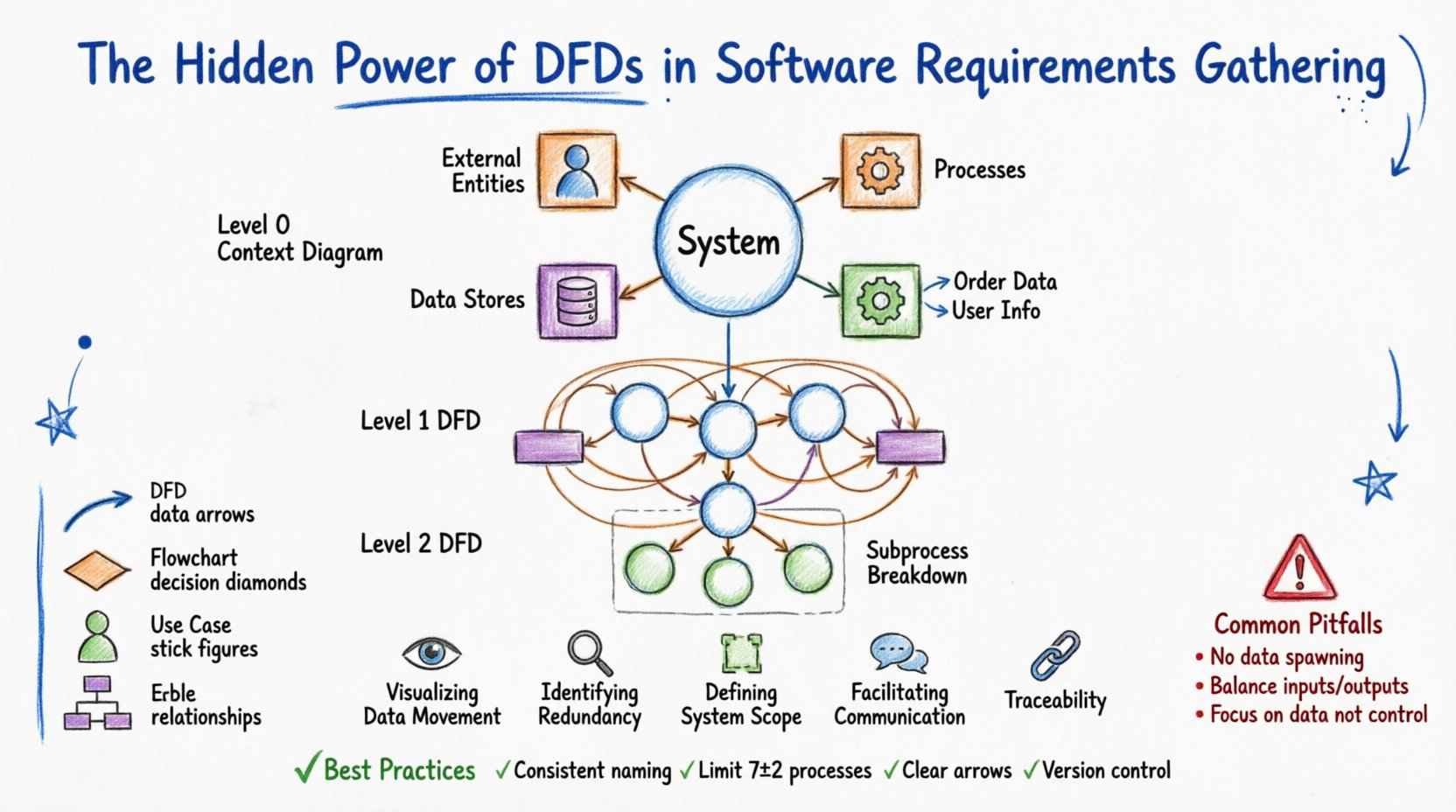
在将数据流图应用于复杂项目之前,必须先理解其基本构成。数据流图由四个基本元素组成。每个元素都有特定的几何表示形式,并对其在系统中的功能有严格定义。
理解这些组件可以避免在需求工作坊中产生混淆。利益相关者常常将处理过程与数据存储混淆。一张清晰的图表能明确指出,“客户”是一个实体,而“客户记录”则是一个存储。这种区分是准确系统建模的基础。
需求文档常常因文字过多而难以理解,容易产生歧义。数据流图提供了一个可视化且空间化的单一事实来源。这就是为什么它们在分析阶段不可或缺的原因。
DFD并非一次性在单一视图中创建。它们通过分层分解来管理复杂性。这种方法使分析人员可以从高层次概览开始,逐步深入到具体细节,而不会让读者感到信息过载。
这是最高层级。它将整个系统表示为一个单一的过程。它展示了系统与外部世界的关系。你会看到中心位置有一个单一的过程,周围环绕着所有通过数据流连接的外部实体。该图回答的问题是:“系统是什么,它与谁交互?”
在此层级,上下文图中的单一过程被展开为若干主要子过程。该层级通常包含5到9个过程,展示了系统的各个主要功能区域。它包含数据存储和外部实体,但重点在于主要的数据转换。
第1层的每个过程都可以进一步分解为第2层的图表。这在处理复杂逻辑时非常有用。例如,“处理付款”过程可能被分解为“验证卡片”、“扣款账户”和“更新账本”。当过程简单到足以作为一个单一模块或函数实现时,分解即停止。
构建一个有效的DFD需要纪律。这不仅仅是画线,更在于准确捕捉逻辑。遵循这一结构化方法,以确保质量。
即使是经验丰富的分析人员也会犯错。及早识别这些错误,可以在开发阶段节省大量时间。以下是建模需求时最常见的问题。
| 陷阱 | 描述 | 纠正方法 |
|---|---|---|
| 数据凭空产生 | 数据在没有输入来源的情况下凭空出现。 | 每个箭头必须源自一个实体、过程或存储。 |
| 数据销毁 | 数据流入一个过程,但没有输出或存储就消失了。 | 确保每个输入都产生有意义的输出或被保存。 |
| 控制逻辑 | 使用DFD来表示决策逻辑(if/else),而不是数据流。 | 使用流程图进行逻辑控制;使用DFD表示数据流动。 |
| 不平衡的图 | 子图的输入/输出与父图不同。 | 审查分解过程,确保所有数据流都已考虑在内。 |
| 幽灵过程 | 不改变数据或不存储数据的过程。 | 删除不执行转换的过程。 |
| 实体到实体的直接数据流 | 数据在两个外部实体之间流动,而不经过系统。 | 这超出了系统范围。系统必须处理这种交互。 |
人们常常混淆DFD与其他绘图方法。每种工具在软件工程生命周期中都有特定用途。了解何时使用哪种图可以避免混淆。
为了确保您的图表在整个项目生命周期中保持有用,应遵循这些标准。一致性是维护需求模型完整性的关键。
一个结构良好的DFD最具威力的方面之一,就是它能够支持可追溯性矩阵。可追溯性确保每个需求都得到满足,且不会无目的地构建任何内容。
创建DFD时,可以为每个过程和数据存储分配唯一ID。例如,过程P1.0可能对应需求REQ-001。如果利益相关者请求新增功能,你可以将其映射到特定的过程ID。如果能在图中找到该过程,你就确切知道数据逻辑需要在何处修改。
这在回归测试期间尤为重要。如果“计算利息”过程被修改,DFD会明确告诉质量保证团队哪些数据流受到影响。他们知道需要专门测试输入(本金金额)和输出(利息支付)。如果没有DFD,测试人员可能会遗漏与数据转换相关的边界情况。
一些团队认为DFD对于敏捷方法论来说过于沉重。他们更倾向于使用用户故事和验收标准。虽然用户故事在功能方面表现优异,但往往缺乏对数据流的系统性视角。如果将DFD作为动态文档使用,它能很好地融入敏捷流程。
DFD通常与数据字典配合使用。数据字典为图中显示的每个数据元素提供技术定义。它明确说明了数据类型、长度和格式。
例如,图中标记为“出生日期”的数据流在字典中可能被定义为“YYYY-MM-DD,ISO 8601,可为空”。这种精确性可防止开发人员猜测如何存储数据。当需求收集同时包含DFD和数据字典时,数据类型不匹配的风险会显著降低。
考虑为你的数据字典包含以下组件:
从概念到代码的旅程充满了误解。数据流图在此过程中起到了稳定作用。它们迫使团队面对数据流动的现实。在编写任何代码之前,就能暴露逻辑上的漏洞。
投入时间创建高质量的数据流图,能有效减少返工。当利益相关者验证图表时,他们实际上是在验证系统的逻辑。这种共同理解减少了业务与技术团队之间的摩擦,使讨论从主观意见转向客观事实。
请记住,数据流图并非静态交付物。随着需求的演变,它也会随之更新。应以与代码库同等的严谨态度对待它。保持其更新、保持可访问,并用它来指导开发工作。通过掌握数据建模的艺术,确保你所构建的软件不仅功能完备,而且逻辑严谨,与业务需求保持一致。
数据流图的隐性力量在于其简洁性。它们剔除了实现细节的干扰,聚焦于核心真理:数据必须正确流动。当数据流动正确时,系统就能正常运行;当数据缺失或流向错误时,系统就会失败。使用这一工具,可以自信而精准地指导需求收集工作。