 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











设计一个复杂的软件系统需要清晰地了解数据的流动方式以及数据的存储位置。如果没有结构化的方法,系统架构可能会变得脆弱、难以维护,并容易出现逻辑错误。系统工程中最基础的两种建模技术是数据流图(DFD)和实体关系图(ERD)。尽管两者都具有关键的可视化功能,但它们关注的是系统中截然不同的方面。
理解这两种模型之间的区别不仅仅是一个学术上的练习;对于系统架构师、业务分析师和开发人员来说,这是实际的必要需求。在开发的错误阶段使用错误的模型,可能导致沟通失误、数据库效率低下或业务逻辑断裂。本指南探讨了每种图表类型的细微差别、其特定组成部分,以及在何种战略场景下一种模型应优先于另一种。
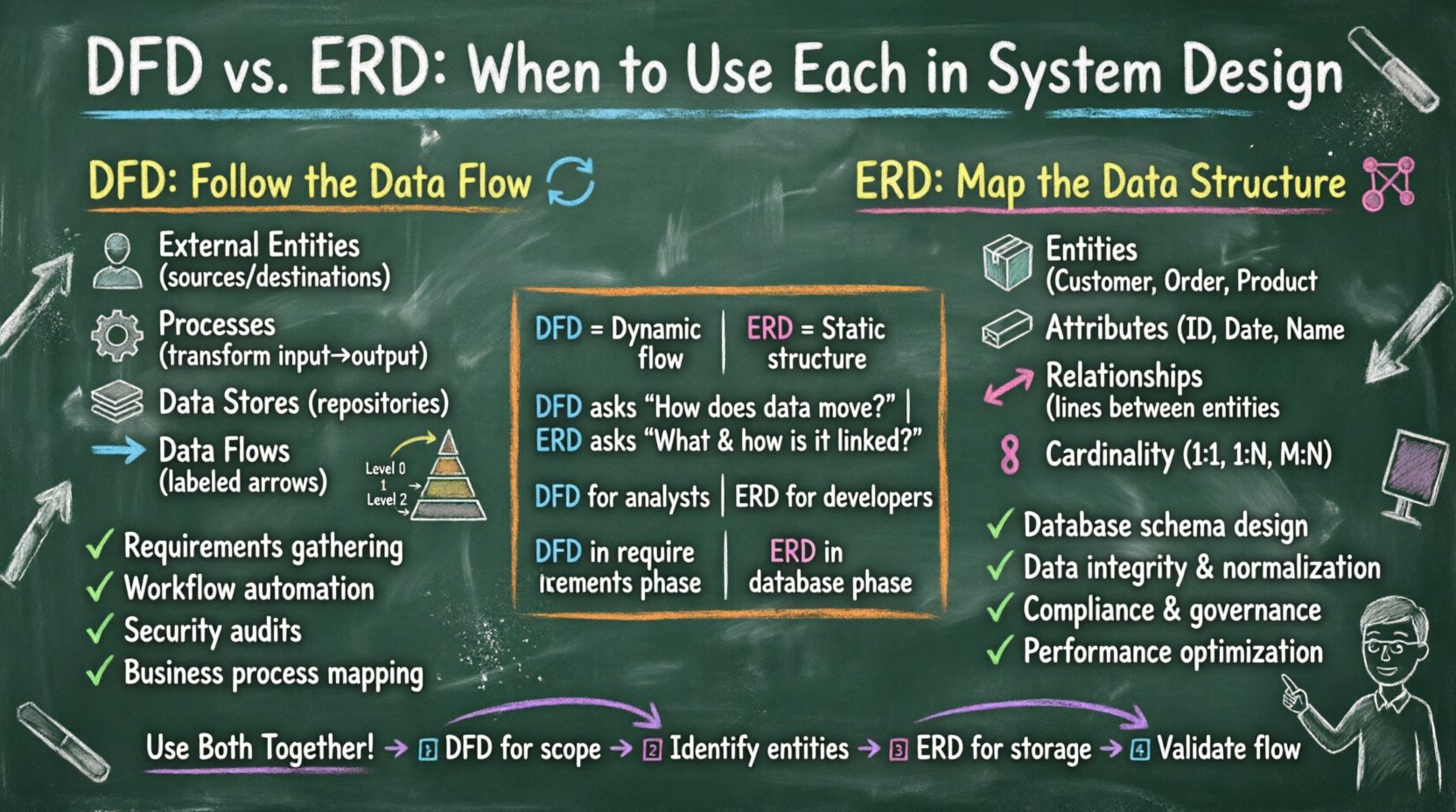
数据流图关注的是数据在系统中的流动。它可视化信息如何被处理、转换和存储。DFD不关心物理实现细节或过程的时间安排,而是提供信息逻辑流动的高层次视图。
DFD通常以分层方式创建,以管理复杂性:
DFD在需求收集和功能设计阶段最为有效。它们帮助利益相关者在不被技术限制干扰的情况下,可视化系统的运行行为。它们特别适用于:
虽然DFD追踪的是数据的流动,但实体关系图(ERD)则关注结构。ERD是一种概念模型,用于定义数据库中的数据需求和关系。它描述了数据的静态特性,确保数据的完整性和规范化。
ERD通常是规范化的起点。规范化是组织数据以减少冗余并提高完整性的过程。ERD有助于在创建物理表之前可视化逻辑模式。它确保:
ERD在数据库设计阶段至关重要。它们弥合了业务需求与技术实现之间的差距。它们最适合在以下情况使用:
将这两个模型并列比较,突显了它们不同的目的。尽管它们在视觉复杂性上可能相似,但其意图却显著不同。
| 特性 | 数据流图(DFD) | 实体关系图(ERD) |
|---|---|---|
| 主要关注点 | 过程与数据流动 | 数据结构与关系 |
| 时间维度 | 动态(显示随时间的流动) | 静态(显示某一点的结构) |
| 核心问题 | 数据如何流动? | 存储了哪些数据,它们是如何关联的? |
| 目标受众 | 业务分析师、利益相关者 | 数据库管理员、后端开发人员 |
| 生命周期阶段 | 需求分析、功能设计 | 数据库设计、实现 |
| 逻辑 vs. 存储 | 侧重于逻辑 | 侧重于存储 |
| 复杂性 | 由于存在大量流程,可能变得复杂 | 由于关系复杂,可能变得复杂 |
在某些特定场景下,DFD会成为系统设计的主要工具。当业务逻辑是系统中最复杂的部分时,优先选择DFD通常是正确的路径。
在这些情况下,过早关注ERD可能会掩盖系统的逻辑。数据库可以设计得完美无缺,但如果流程存在缺陷,应用程序将无法满足用户需求。
相反,有些情况下,数据的完整性和结构是决定成败的关键因素。当数据量、关系和约束是主要驱动力时,ERD应优先考虑。
在这些场景中跳过 ERD 可能导致出现“意大利面式数据库”,其中表冗余、关系模糊,性能会随时间逐渐下降。
虽然区分 DFD 和 ERD 有其用处,但最成功的系统通常同时使用两者。它们是互补的,而非互斥的。稳健的系统设计过程通常是从流程走向结构。
在 DFD 中,数据存储是一个通用占位符。在 ERD 中,该数据存储变为详细的表定义。映射过程包括:
例如,如果 DFD 显示“客户”发送多个“订单”,则 ERD 必须反映客户与订单实体之间的“一对多”关系。如果 DFD 暗示一个复杂的多对多关系(例如,“学生”和“课程”),则 ERD 必须引入一个关联实体来解决该问题。
混合使用这些模型或误用它们可能导致严重的技术债务。以下是一些需要警惕的常见错误。
不要在ERD中包含处理逻辑。ERD应定义结构,而非行为。如果你发现自己在ERD中绘制代表“处理”的箭头,那么你很可能实际上是在描述DFD。
DFD不应是代码的流程图。它不应详细描述每一个条件分支或错误处理流程。应将DFD保持在逻辑层面。如果详细列出每一个“if-else”语句,图表将变得难以阅读,并失去其高层概览的价值。
在未定义基数的情况下在实体之间绘制连线是一种常见错误。仅凭一条线无法说明一个客户可以有零个订单或一百万个订单。必须始终明确指定1:1、1:N或M:N以避免歧义。
当数据属性模糊时,两种图表都会受到影响。在DFD中,数据流应使用描述性名称(例如“已验证的支付信息”,而不是“数据”)。在ERD中,属性应尽可能定义数据类型和约束条件。
在DFD中,一个处理过程不能在没有数据流入或流出的情况下存在。确保每个处理框至少有一个输入流和一个输出流。孤立的处理过程表明存在死逻辑或缺失的数据需求。
为保持清晰性和实用性,请遵循这些文档标准。
在数据流图和实体关系图之间进行选择,并非意味着二选一。而是要为设计生命周期的特定阶段选择合适的工具。DFD揭示了数据的流动路径,确保系统按预期运行。ERD则锚定这些数据,确保其被可靠且高效地存储。
通过掌握这两种模型的不同用途,架构师可以构建出既逻辑严谨又结构稳固的系统。目标并非制作完美的图表,而是形成对系统的清晰理解。当团队能够通过DFD看到流程,通过ERD看到数据时,成功项目的基石便已奠定。
请记住,这些模型是沟通工具。它们的价值在于团队成员之间建立的共同理解。无论你是在绘制复杂的交易流程,还是定义用户资料,都应始终聚焦于清晰性、准确性和与业务目标的一致性。通过恰当结合流程与结构,系统设计便成为一门有纪律的艺术,而非盲目猜测。