数据流图(DFD)是系统设计与分析的基石。它们以可视化方式展示信息在系统中的流动过程,突出显示处理过程、数据存储以及外部交互。然而,一张图表的价值取决于其准确性和清晰度。若缺乏严格的验证,DFD可能导致期望错位、开发错误和安全漏洞。
本指南提供了一份全面的检查清单,用于验证您的数据流图。我们将从结构完整性到逻辑一致性,全面审视图表的每一个方面,确保您的文档不仅是绘图,更是一种可用于工程与沟通的功能性工具。🛠️
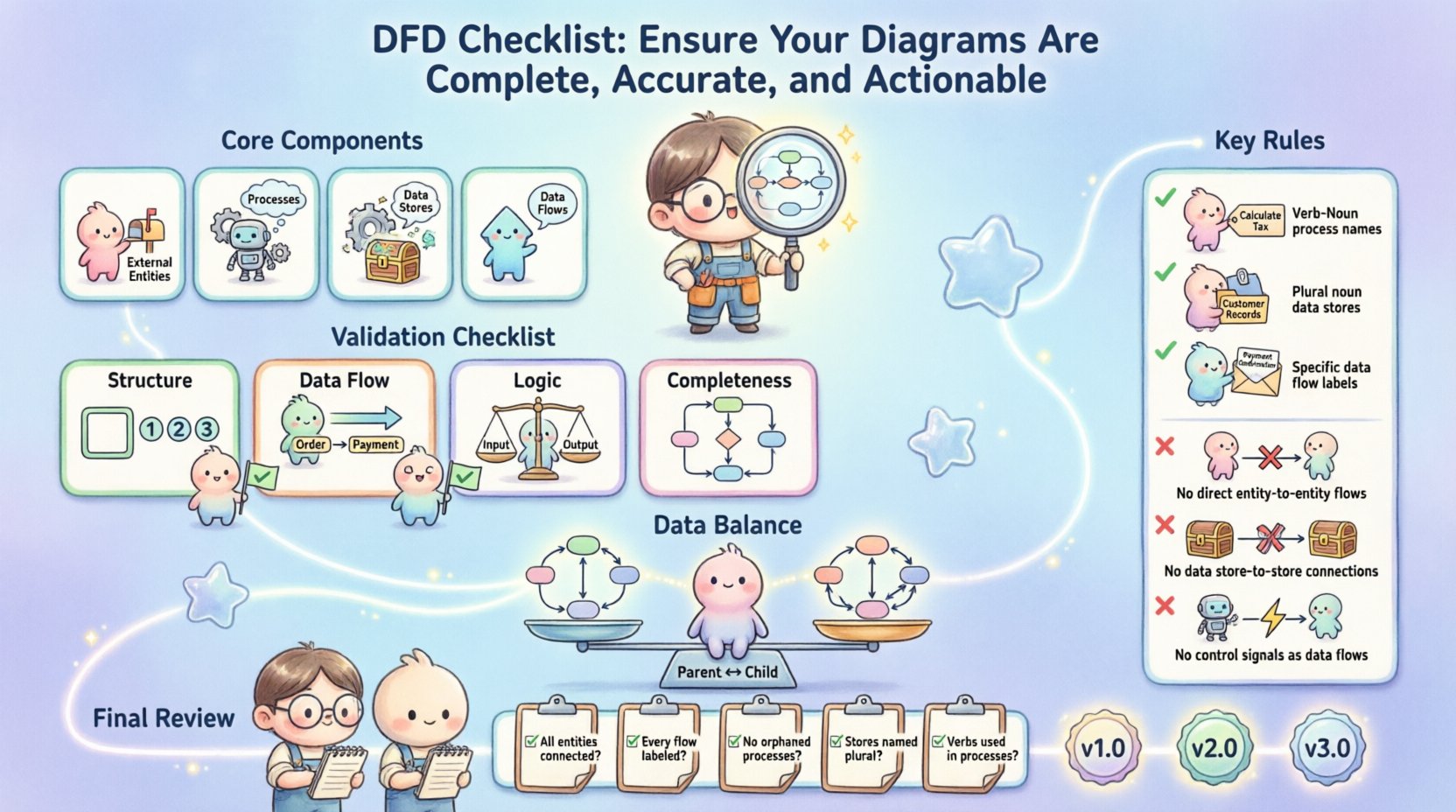
理解核心组件 🧩
在应用检查清单之前,必须确认基本元素均已存在且定义正确。一个有效的DFD依赖于四个特定组件。若其中任何一项缺失或使用不当,图表的完整性将受到损害。
- 外部实体: 这些是系统边界之外的数据源或目的地。它们代表与系统交互的用户、其他系统或硬件设备。
- 处理过程: 这些代表对数据执行的操作或转换。它们接收输入数据,对其进行修改,并生成输出数据。
- 数据存储: 这些代表数据静止存放的位置。包括数据库、文件或物理存档。
- 数据流: 这些是连接各组件的箭头,表示信息流动的方向。
每个组件都必须遵循特定的符号规则。尽管符号风格有所不同,但其基本逻辑保持一致。请确保您熟悉组织中所使用的具体标准,无论是Gane和Sarson还是Yourdon和DeMarco。
绘图前准备 📝
验证工作始于绘制第一根箭头之前。充分的准备工作可减少绘图阶段的错误。请使用以下准备步骤,为后续工作奠定坚实基础。
- 定义系统边界: 明确区分系统内部与外部的内容。这决定了哪些处理过程应被包含,哪些实体属于外部。
- 识别利益相关者: 明确谁将审查该图表。开发人员需要的细节与业务分析师不同。
- 建立命名规范: 在开始之前,就处理过程、数据流和存储的命名标准达成一致。一致性可避免后续混淆。
- 确定分解范围: 决定需要多少层级的详细程度。单一图表无法展示所有内容;需规划好层级结构。
全面验证检查清单 ✅
在审查过程中可将此表格作为参考。它涵盖了需要仔细检查的关键领域,以确保图表具备功能性与准确性。
| 类别 |
检查项目 |
验证标准 |
| 结构 |
边界定义 |
系统边界应使用明显的线条或方框清晰标出。 |
| 结构 |
过程数量 |
过程按顺序编号(例如,1.0、2.0、3.0)。 |
| 数据流 |
箭头方向 |
所有数据流都有明确的起点和终点;不得出现孤立的箭头。 |
| 数据流 |
数据标注 |
每个箭头都应使用描述性的名词短语,而非动词。 |
| 逻辑 |
过程输入/输出 |
每个过程必须至少有一个输入和一个输出。 |
| 逻辑 |
数据存储访问 |
数据存储必须同时具有读取(输入)和写入(输出)的数据流。 |
| 完整性 |
外部实体可达性 |
每个外部实体都至少连接一个过程。 |
| 完整性 |
数据存储隔离 |
数据流不得直接连接到其他数据存储。 |
1. 结构完整性 🔨
图表的物理布局必须支持逻辑流程。杂乱无章的图表往往导致对系统的理解也杂乱无章。
- 顺序编号:确保所有过程按逻辑编号。第0层应从0.0或1.0开始。分解后的过程应遵循父-子层级关系(例如,1.1、1.2)。
- 形状一致性:如果使用矩形表示过程,请确保其不会与数据存储混淆。如果使用圆形或圆角矩形,请在整个文档中保持一致。
- 无孤立组件: 检查每个形状是否至少连接到另一个元素。孤立的过程或实体表明工作流已中断。
2. 数据流准确性 🔄
数据流是图表的血管。如果它们不正确,整个系统逻辑就会出错。
- 仅使用名词短语:数据流上的标签应为名词(例如“订单详情”),而非动词(例如“处理订单”)。动词应放在过程本身上。
- 双向流: 如果一个箭头连接两个组件,请确保数据确实双向流动。如果数据在每个方向上的流动方式不同,则应将其拆分为两个独立的箭头,并使用不同的标签。
- 幽灵流: 删除任何不传递实际信息的数据流。连接两个过程但不传递任何数据的线条是噪声。
- 控制与数据: 区分控制信号和数据。控制信号(如“开始”或“停止”)不是数据。如果它们表示状态变化,应以不同方式建模或单独记录。
3. 过程逻辑验证 ⚙️
过程会转换数据。如果转换逻辑有误,输出将毫无用处。
- 黑洞检查: 确保没有过程在不产生任何输出的情况下消耗数据。一个接收数据但对其不做任何处理的过程是黑洞,不应存在。
- 灰洞检查: 确保没有过程在不消耗任何数据的情况下产生数据。一个从无到有生成输出的过程是灰洞(魔法)。
- 转换清晰性: 输入数据和输出数据应有所不同。如果输出与输入完全相同,该过程可能是冗余的,除非它增加了元数据或时间戳。
- 决策点: 数据流图通常不显示“if/else”等内部逻辑。如果一个过程涉及分支逻辑,应在单独的规范文档中描述,而不是画成菱形(菱形属于流程图)。
确保数据平衡 ⚖️
数据流图中最关键的技术要求之一是平衡。平衡确保父过程进入和离开的数据,与低层图中其子过程进入和离开的数据相匹配。
为什么平衡很重要
如果没有平衡,分解过程中信息会丢失或被创造。这会导致高层概览与详细实施计划之间出现差异。
如何验证平衡
- 输入匹配: 进入子图的数据流总和必须等于进入父过程的数据流。
- 输出匹配: 离开子图的数据流总和必须等于离开父过程的数据流。
- 数据存储一致性: 如果父进程访问一个数据存储,那么访问同一存储的子进程必须保持相同的输入/输出关系。
- 重新验证: 每次分解一个过程时,都必须重新检查平衡性。在放大过程中,很容易丢失数据流。
命名规范与清晰性 🏷️
图表是一种沟通工具。如果名称模糊不清,沟通就会失败。清晰的命名规范可以减少评审过程中口头解释的需求。
过程命名
- 动词-名词结构: 使用动词加名词的结构来命名过程(例如:“计算税款”、“更新库存”)。
- 唯一名称: 避免使用“过程1”或“做某事”之类的通用名称。每个过程都应具有唯一且描述性的名称。
- 一致性: 如果在一个图中将其称为“验证用户”,在另一个图中就不应称为“检查登录”。所有层级都应使用相同的术语。
数据存储命名
- 名词短语: 数据存储应使用复数名词命名(例如:“客户记录”、“订单日志”)。
- 逻辑与物理: 不要根据物理实现来命名数据存储(例如:“SQL_Table_1”)。应使用描述内容的逻辑名称(例如:“客户数据库”)。
- 唯一性: 确保没有两个数据存储具有完全相同的名称,即使它们位于不同的图表中。
数据流命名
- 具体数据: 不要将数据流标记为“数据”。应具体说明(例如:“收货地址”、“付款确认”)。
- 状态变更: 如果数据状态发生变化(例如,“草稿订单”变为“最终订单”),数据流标签应反映这一区别,或者过程名称应体现该转换。
应避免的常见陷阱 ⚠️
即使是经验丰富的分析师也会陷入陷阱。以下是损害DFD质量的最常见错误。
- 实体到实体的直接数据流: 数据不能在不经过系统边界内某个过程的情况下,直接从一个外部实体流向另一个外部实体。这会绕过系统逻辑。
- 数据存储到数据存储的流: 数据无法直接从一个数据存储移动到另一个数据存储。它必须被一个进程读取、转换,然后写入新的存储位置。
- 混淆控制与数据: 如“点击按钮”或“超时”之类的信号是事件,而不是数据。除非它们携带信息负载,否则不应将其绘制为数据流。
- 过度复杂: 避免在一个图中包含过多细节。如果一个图包含超过7到9个处理过程,很可能过于复杂,不适合单一视图。应使用分解方法将其拆分。
- 缺少上下文: 切勿在未提供上下文图(第0层)作为参考点的情况下展示第1层或第2层图。
利益相关者验证 🤝
技术准确性只是成功的一半。该图必须被将要构建和使用系统的人员所理解。验证需要与利益相关者进行积极互动。
- 走查: 安排会议,与利益相关者口头追踪数据流。请他们从头到尾追踪一个特定的交易流程。
- 提问提示: 提出诸如“如果缺少这些数据会发生什么?”或“这些信息存储在哪里?”等问题,以检验图表的健壮性。
- 差距分析: 将图表与需求文档进行对比。确保所有涉及数据移动的需求都以可视化方式呈现。
- 开发人员反馈: 让技术团队审查图表的可行性。他们可能会发现业务分析师忽略的数据存储瓶颈或逻辑上的不可能性。
维护与版本控制 🔄
系统会不断演进,需求也会变化。DFD 是一份活文档,而非静态产物。适当的维护可确保图表在长时间内仍具可操作性。
- 版本管理: 为你的图表分配版本号(例如 v1.0、v1.1)。记录变更日期和更新原因。
- 变更日志: 维护一份独立的变更日志。记录哪些过程被添加、删除或重命名。这有助于后续的审计和调试。
- 与需求保持同步: 每当需求发生变化时,立即更新图表。不要让图表脱离需求。
- 归档旧版本: 保持旧版本的可访问性。如果新功能破坏了旧的工作流程,旧图表可作为遗留行为的参考。
最终审查步骤 🔍
在最终确定文档之前,使用此快速检查清单进行最后的审查。
- 所有过程是否都正确编号?
- 每个数据流是否都用名词短语进行了标注?
- 所有数据存储是否都能从至少一个过程访问?
- 该图在所有层级上是否保持平衡?
- 外部实体是否仅与过程相连?
- 系统边界是否明确界定?
- 是否存在浮动元素或孤立组件?
- 文档中的符号使用是否保持一致?
遵循这些指南,可以确保您的数据流图不仅仅是示意图,更是系统架构的可靠蓝图。经过充分验证的数据流图能够减少开发返工,明确沟通,确保最终产品满足预期的数据需求。
 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online