 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Проекты программного обеспечения часто сталкиваются с трудностями не из-за качества кода, а из-за неправильно понятых требований. Когда команды сразу приступают к проектированию или разработке, не имея четкого представления о перемещении данных, результатом становится технический долг и расширение сферы применения. Именно здесь проявляется ценность диаграммы потоков данных (DFD). Она выступает в качестве визуального языка, который устраняет разрыв между бизнес-заинтересованными сторонами и техническими архитекторами.
Диаграмма потоков данных — это графическое представление перемещения данных через информационную систему. В отличие от блок-схем, которые фокусируются на логике управления и точках принятия решений, DFD фокусируются на потоке информации. Они показывают, как данные поступают в систему, как они преобразуются, где хранятся и как покидают систему. В контексте сбора требований это различие имеет решающее значение. Оно переводит разговор с «что делает система» на «какие данные обрабатывает система».что делает система на какие данные обрабатывает система.
В этом руководстве рассматриваются механизмы, преимущества и стратегическое применение DFD. Мы проанализируем, как они устраняют неоднозначность, способствуют валидации и обеспечивают соответствие конечного продукта бизнес-потребностям.
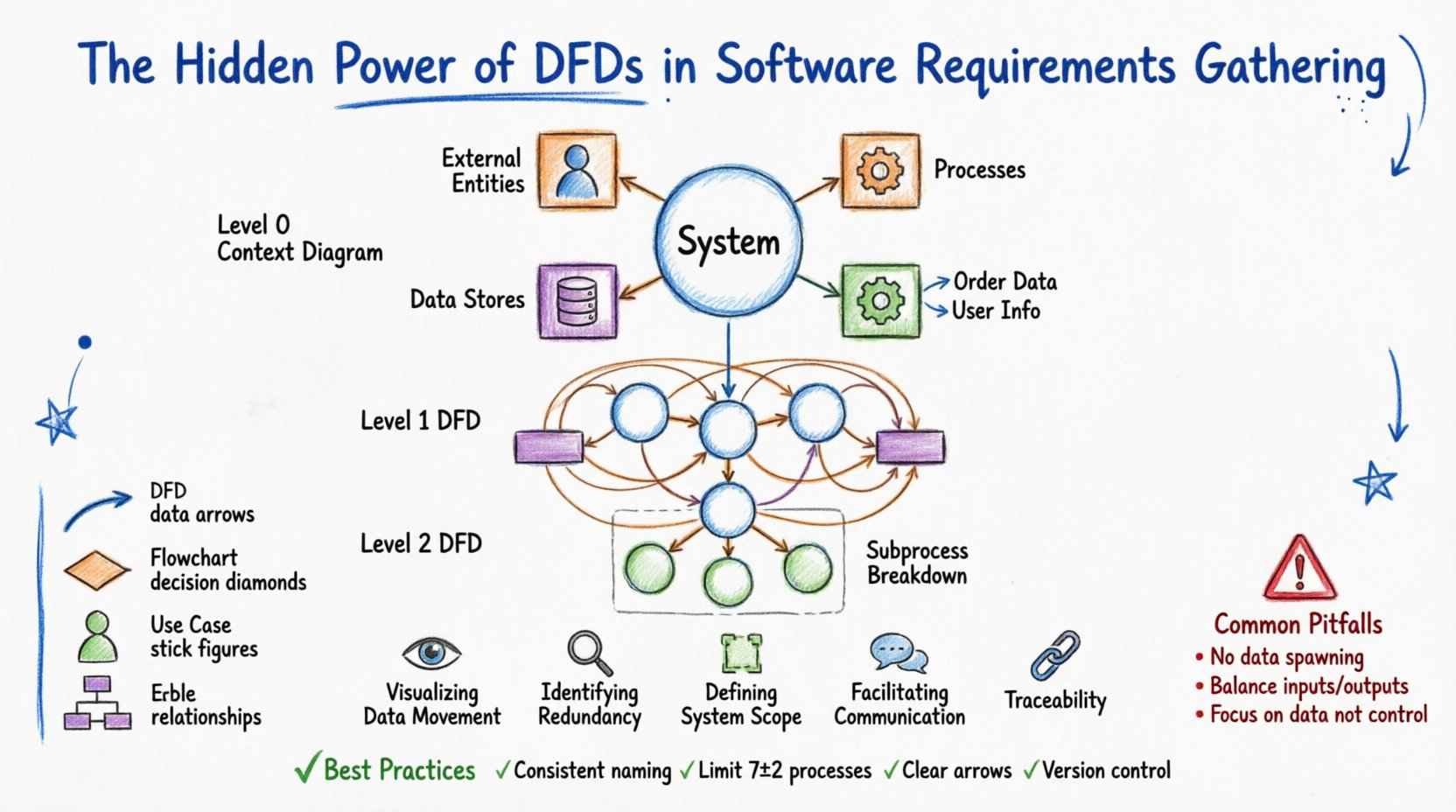
Прежде чем применять DFD к сложным проектам, необходимо понять основные элементы. DFD состоит из четырех фундаментальных компонентов. Каждый из них имеет определенную геометрическую форму и строгое определение функции в системе.
Понимание этих компонентов предотвращает путаницу во время рабочих встреч по сбору требований. Заинтересованные стороны часто путают процесс с хранилищем данных. Четкая диаграмма показывает, что «Клиент» — это сущность, а «Сведения о клиентах» — хранилище. Это различие является основой точного моделирования системы.
Документы требований часто страдают избыточным текстовым описанием, которое допускает разные толкования. DFD предоставляет единый источник истины, который визуален и пространственно организован. Вот почему они незаменимы на этапе анализа.
Диаграммы потоков данных не создаются в одном виде. Они декомпозируются иерархически для управления сложностью. Такой подход позволяет аналитикам начать с общего обзора и постепенно углубляться в конкретные детали, не перегружая читателя.
Это самый высокий уровень. Он представляет всю систему как один процесс. Показывает взаимоотношения системы с внешним миром. Вы увидите единственный процесс в центре, окруженный всеми внешними сущностями, соединенными потоками данных. Эта диаграмма отвечает на вопрос: «Что такое система, и с кем она взаимодействует?»
Здесь единственный процесс из диаграммы контекста раскрывается в основные подпроцессы. На этом уровне обычно содержится от 5 до 9 процессов. Показывает основные функциональные области системы. Включает хранилища данных и внешние сущности, но основное внимание уделяется основным преобразованиям.
Каждый процесс уровня 1 может быть дополнительно разложен на диаграмму уровня 2. Это полезно для сложной логики. Например, процесс «Обработка платежа» может быть разделен на «Проверка карты», «Списание со счета» и «Обновление журнала». Декомпозиция прекращается, когда процессы становятся достаточно простыми, чтобы быть реализованными как единый модуль или функция.
Создание эффективной диаграммы потоков данных требует дисциплины. Это не просто рисование линий; это точное отражение логики. Следуйте этой структурированной методике, чтобы обеспечить качество.
Даже опытные аналитики допускают ошибки. Раннее выявление этих ошибок экономит значительное время на этапе разработки. Ниже перечислены наиболее распространённые проблемы, возникающие при моделировании требований.
| Ошибки | Описание | Исправление |
|---|---|---|
| Появление данных | Данные появляются ниоткуда, без источника входа. | Каждая стрелка должна исходить из сущности, процесса или хранилища. |
| Уничтожение данных | Данные поступают в процесс, но исчезают без вывода или хранения. | Убедитесь, что каждый вход приводит к значимому выходу или сохраняется. |
| Логика управления | Использование DFD для отображения логики принятия решений (если/иначе) вместо потока данных. | Используйте диаграммы последовательности для управления логикой; используйте DFD для перемещения данных. |
| Несбалансированные диаграммы | Дочерние диаграммы имеют другие входы/выходы, чем родительская. | Проверьте декомпозицию, чтобы убедиться, что учтены все потоки данных. |
| Призрачные процессы | Процессы, которые не изменяют данные и не хранят их. | Удалите процессы, которые не выполняют преобразование. |
| Прямой поток между сущностями | Данные перемещаются между двумя внешними сущностями без прохождения через систему. | Это находится вне области системы. Система должна обрабатывать взаимодействие. |
Часто путают DFD с другими методами диаграммирования. Каждый инструмент служит определенной цели в жизненном цикле разработки программного обеспечения. Знание, когда использовать ту или иную диаграмму, предотвращает путаницу.
Чтобы обеспечить, что ваши диаграммы останутся полезными элементами на протяжении всего жизненного цикла проекта, придерживайтесь этих стандартов. Согласованность — ключ к сохранению целостности модели требований.
Одним из самых мощных аспектов хорошо построенной DFD является её способность поддерживать матрицы отслеживаемости. Отслеживаемость гарантирует, что каждое требование выполнено, и ничего не создаётся без цели.
Когда вы создаете DFD, вы можете присвоить уникальный идентификатор каждому процессу и хранилищу данных. Например, процесс P1.0 может соответствовать требованию REQ-001. Если заинтересованная сторона запросит новую функцию, вы можете сопоставить её с конкретным идентификатором процесса. Если вы можете найти этот процесс на диаграмме, вы точно знаете, где нужно изменить логику обработки данных.
Это особенно важно во время регрессионного тестирования. Если процесс «Расчёт процентов» изменён, DFD точно указывает, какие потоки данных затронуты. Команда тестирования знает, что нужно проверить вход (Сумма кредита) и выход (Выплата процентов) в первую очередь. Без DFD тестировщики могут упустить крайние случаи, связанные с преобразованием данных.
Некоторые команды утверждают, что DFD слишком громоздки для Agile-методологий. Они предпочитают пользовательские истории и критерии приёма. Хотя пользовательские истории отлично подходят для функциональности, они часто не дают системного взгляда на потоки данных. DFD хорошо вписываются в Agile, если использовать их как живой артефакт.
DFD часто используется вместе со словарём данных. Словарь данных предоставляет техническое определение каждого элемента данных, отображённого на диаграмме. Он указывает типы данных, длину и форматы.
Например, поток данных с меткой «Дата рождения» на диаграмме может быть определён в словаре как «ГГГГ-ММ-ДД, ISO 8601, допускает null». Такая точность предотвращает догадки разработчиков о том, как хранить данные. Когда сбор требований включает как DFD, так и словарь данных, риск несоответствий типов данных значительно снижается.
Рассмотрите следующие компоненты для вашего словаря данных:
Путь от концепции до кода полон неправильного понимания. Диаграммы потоков данных выступают в роли стабилизирующей силы на этом пути. Они заставляют команду столкнуться с реальностью перемещения данных. Они выявляют пробелы в логике до того, как будет написана первая строка кода.
Вложение времени в создание качественных диаграмм потоков данных окупается сокращением повторной работы. Когда заинтересованные стороны подтверждают диаграмму, они подтверждают логику системы. Это общее понимание снижает напряжённость между командами бизнеса и технологий. Это переводит разговор из сферы мнений в сферу фактов.
Помните, что диаграмма потоков данных — это не статичный результат. Она развивается вместе с требованиями. Относитесь к ней с той же строгостью, что и к кодовой базе. Держите её в актуальном состоянии, обеспечьте доступность и используйте для руководства вашими разработками. Освоив искусство моделирования данных, вы гарантируете, что создаваемое вами программное обеспечение будет не просто функциональным, но и логически обоснованным и соответствующим потребностям бизнеса.
Скрытая сила диаграмм потоков данных заключается в их простоте. Они устраняют шум деталей реализации и фокусируются на главной истине: данные должны правильно перемещаться. Когда данные перемещаются правильно, система работает. Когда данные отсутствуют или направляются неверно, система выходит из строя. Используйте этот инструмент для уверенного и точного сбора требований.