 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Диаграммы потоков данных (DFD) служат основным инструментом в анализе и проектировании систем. Они предоставляют визуальное представление о том, как информация перемещается через систему, выделяя входы, выходы, хранилища и процессы. Для начинающих понимание механики DFD имеет решающее значение перед попыткой отобразить сложные рабочие процессы. В этом руководстве рассматриваются основные принципы, компоненты и правила, необходимые для создания точных диаграмм без использования специфического программного обеспечения.
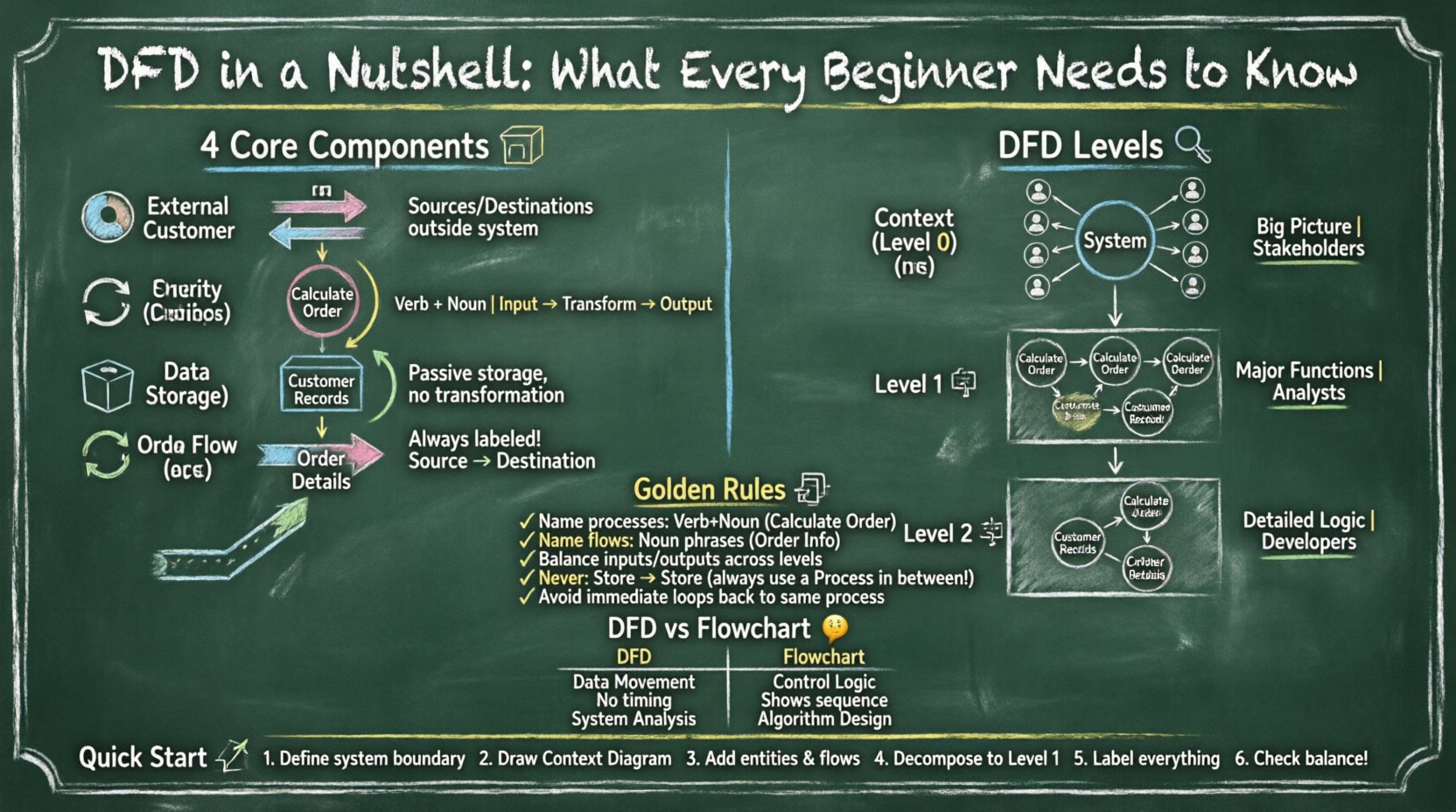
Диаграмма потоков данных — это структурированная техника анализа, используемая для визуализации потока данных в системе. В отличие от блок-схемы, которая фокусируется на логике управления и точках принятия решений, DFD строго ориентирована на перемещение данных. Она отвечает на вопрос:Откуда приходит данные, куда они направляются и что с ними происходит?
Основные цели использования DFD включают:
Когда вы начинаете анализировать систему, цель состоит в создании модели, которую могут понять заинтересованные стороны. Хорошо построенная диаграмма устраняет неоднозначность в обработке данных. Она выступает в качестве чертежа для разработчиков и аналитиков, обеспечивая согласие всех сторон относительно того, как информация перемещается.
Чтобы нарисовать корректную диаграмму, необходимо понимать четыре основных формы и их значение. Эти компоненты составляют лексику моделирования потоков данных. Каждый элемент выполняет определенную роль в архитектуре системы.
Внешние сущности представляют источники или пункты назначения данных за пределами моделируемой системы. Их также называют терминаторами или агентами. Эти сущности взаимодействуют с системой, но не являются частью внутренней логики.
Сущность должна быть внешней. Если сущность является частью внутренней логики системы, она должна быть представлена как процесс. Путаница здесь часто приводит к неверным определениям границ.
Процессы — это действия, которые преобразуют входные данные в выходные. Они представляют выполняемую работу, вычисления или логику принятия решений внутри системы. Процесс изменяет состояние или содержание данных.
Каждый процесс должен иметь хотя бы один вход и один выход. Процесс, который имеет только вход, но нет выхода, или только выход, но нет входа, является недопустимым. Это называетсячёрной дыройиличудомсоответственно.
Хранилища данных — это места, где информация хранится для последующего использования. Они не преобразуют данные; они просто хранят их. Это может быть база данных, файл, физический файловый шкаф или даже временный буфер.
Потоки данных могут входить и выходить из хранилища данных, но само хранилище не изменяет данные. Оно выступает в роли пассивного хранилища. В современных системах это часто соответствует таблице базы данных.
Потоки данных представляют перемещение данных между сущностями, процессами и хранилищами. Они показывают направление передачи информации. Поток данных всегда должен быть помечен, чтобы точно указать, какая информация перемещается.
Поток данных не может существовать без источника и пункта назначения. Он не может «висеть в воздухе». Кроме того, потоки данных не должны пересекаться с другими потоками без специальной точки пересечения, хотя некоторые нотации позволяют это для упрощения.
Сложные системы не могут быть представлены на одной странице. Чтобы управлять сложностью, диаграммы потоков данных (DFD) разбиваются на уровни. Этот метод называетсядекомпозицией. Это позволяет вам приблизить определенные области, сохраняя при этом общую картину.
Схема контекста — это самый высокий уровень представления. Она показывает всю систему как один процесс. Определяет имя системы и все внешние сущности, взаимодействующие с ней. На этом уровне не показаны хранилища данных или внутренние процессы.
Схема уровня 1 раскрывает единственный процесс из схемы контекста на основные подпроцессы. Она раскрывает основные функциональные области системы. Это часто первая детализированная схема, которая создается.
Схемы уровня 2 дополнительно расчленяют конкретные процессы уровня 1. Если процесс на уровне 1 сложный, он расширяется до нескольких подпроцессов на уровне 2. Этот процесс продолжается до тех пор, пока процессы не станут достаточно простыми для прямой реализации.
| Уровень | Фокус | Количество процессов | Основная аудитория |
|---|---|---|---|
| Контекст | Граница системы | 1 | Управление, заинтересованные стороны |
| Уровень 1 | Основные функции | 3–7 | Аналитики, проектировщики |
| Уровень 2 | Подфункции | Переменная | Разработчики, исполнители |
Создание диаграммы потоков данных — это не просто рисование линий; речь идет о соблюдении логических правил. Нарушение этих правил приводит к диаграммам, которые технически неверны и запутаны. Соблюдение стандартных правил обеспечивает единообразие в документации.
Каждый элемент должен быть однозначно назван, чтобы избежать неоднозначности. Плохое имя — самая распространённая ошибка в диаграммах начинающих.
Согласованность в именовании позволяет читателям отслеживать данные на нескольких уровнях диаграммы без путаницы.
Сбалансированность — это критическое правило при переходе от одного уровня к следующему. Входы и выходы родительского процесса должны соответствовать входам и выходам дочерней диаграммы, созданной путем декомпозиции.
Всегда проверяйте стрелки, входящие и выходящие за границу декомпозированного процесса, по сравнению с родительским процессом.
Данные поступают в хранилища данных и выходят из них. Однако поток данных не может напрямую идти от одного хранилища данных к другому без промежуточного процесса. Процесс должен выступать посредником для преобразования или маршрутизации данных.
Это правило гарантирует, что данные не перемещаются просто так, без цели. Каждое перемещение должно означать, что выполняется какая-либо логика или действие.
Циклы while распространены в программировании, но в диаграммах потоков данных они могут указывать на ошибку в проектировании. Поток данных не должен немедленно возвращаться к тому же процессу без прохождения через другие компоненты. Если поток возвращается, это означает задержку или необходимость другого процесса.
Начинающие часто путают диаграммы потоков данных с диаграммами потоков. Хотя оба используют похожие формы, такие как прямоугольники и стрелки, их цели фундаментально различны.
| Функция | Диаграмма потоков данных (DFD) | Диаграмма потоков |
|---|---|---|
| Фокус | Передвижение данных | Логика управления |
| Точки принятия решений | Не показаны явно | Центральный компонент (форма ромба) |
| Процесс | Преобразование данных | Последовательность шагов |
| Время | Не показывает последовательность | Показывает последовательность и временные интервалы |
| Контекст | Анализ системы | Алгоритм или процедура |
Если вам нужно показатьчто происходит с данными, используйте DFD. Если вам нужно показатькак система решает, что делать дальше, используйте диаграмму потоков. Использование DFD для отображения логики управления часто приводит к перегруженным и непонятным диаграммам.
Как только вы поймете теорию, практическое применение следует логической последовательности. Вам не нужно дорогое программное обеспечение, чтобы начать; бумага и карандаш работают так же хорошо, как и на ранних черновиках.
Даже опытные аналитики допускают ошибки. Знание распространенных ошибок может сэкономить значительное время на этапе проверки.
Диаграммы потоков данных не подходят для каждой ситуации. Понимание соответствующего контекста их использования — ключ к эффективной документации.
DFD — это не разовая доставка. Системы меняются, и ваши диаграммы тоже должны меняться. Обслуживание включает в себя поддержание документации в согласованности с фактическим программным обеспечением.
Поддерживая точные диаграммы, вы снижаете риск ошибок при будущих обновлениях. Устаревшая диаграмма часто хуже, чем отсутствие диаграммы, поскольку вводит команду разработчиков в заблуждение.
Диаграммы потоков данных — мощный инструмент для визуализации поведения системы. Они фокусируются на перемещении данных, а не на логике управления. Освоив четыре основных компонента — внешние сущности, процессы, хранилища данных и потоки данных — вы сможете создавать четкие и эффективные модели. Помните, что нужно разбивать сложные системы на уровни, соблюдать строгие правила именования и придерживаться правила балансировки. Избегайте распространённых ошибок, таких как «призрачные» потоки и логика управления. С практикой вы сможете с уверенностью и ясностью моделировать сложные информационные системы.