 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Интеграция систем является основой современной цифровой инфраструктуры. Она соединяет разрозненные приложения, базы данных и службы, чтобы они функционировали как единое целое. Однако сложность перемещения данных между этими системами может быстро стать непрозрачной. Именно здесь становится необходимым диаграмма потоков данных (DFD). DFD предоставляет визуальное представление о том, как данные перемещаются по системе, выделяя входы, процессы, хранилища и выходы. При применении к интеграции систем DFD служит чертежом для понимания происхождения данных и зависимостей.
Без четкого плана проекты интеграции подвергаются риску несогласованности данных, уязвимостей безопасности и узких мест. Визуализируя данные через несколько компонентов, архитекторы и инженеры могут выявить пробелы до того, как они превратятся в критические сбои. Данное руководство рассматривает методологию использования DFD в контексте интеграции сложных систем.
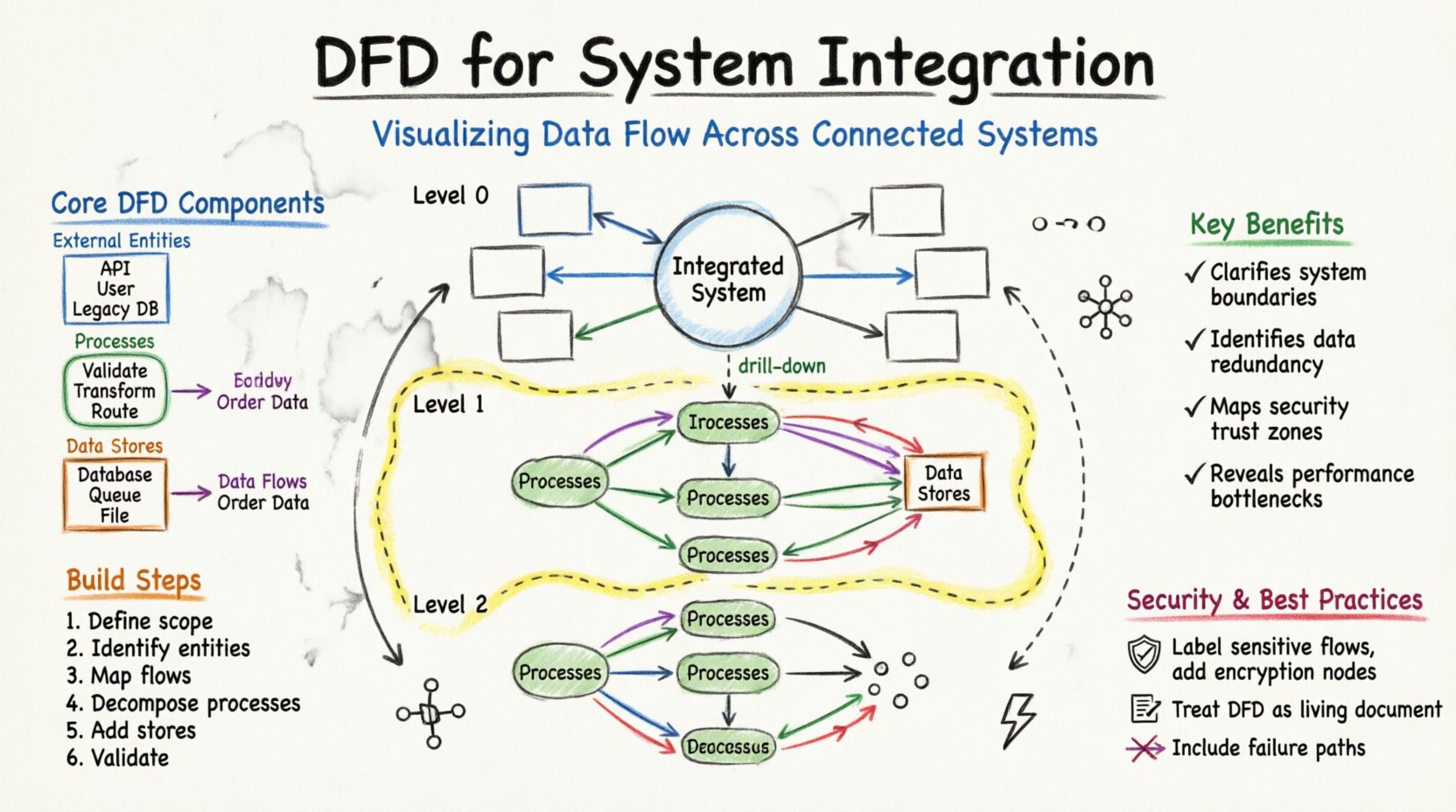
Прежде чем углубляться в особенности интеграции, необходимо понять основные элементы DFD. Эти элементы остаются неизменными независимо от сложности системы.
Важно различать DFD и блок-схемы. Блок-схемы фокусируются на потоке управления и логике принятия решений (ветвления if/else). DFD фокусируется исключительно на перемещении данных. При интеграции систем целостность данных часто важнее, чем конкретный путь принятия решения. Поэтому DFD является предпочтительным инструментом для построения диаграмм преобразования данных.
Когда несколько систем должны взаимодействовать, архитектура часто напоминает сеть. Без централизованного визуального представления соединения могут превратиться в запутанную сеть. DFD помогает разъяснить эту сложность, структурируя информацию на уровнях.
Для управления сложностью DFD обычно создаются на разных уровнях абстракции. Эта иерархия позволяет заинтересованным сторонам рассматривать систему от общего обзора до конкретных технических деталей.
Диаграмма контекста — это самый высокий уровень абстракции. Она рассматривает всю интегрированную систему как один процесс. Она показывает взаимодействие системы с внешними сущностями.
Этот диаграмма разбивает основной процесс на основные подпроцессы. Это основная карта для архитекторов интеграции.
Диаграммы уровня 2 детализируют конкретные подпроцессы уровня 1. Их используют разработчики и инженеры, реализующие конкретную логику.
Создание надежной ДФП требует структурированного подхода. Это не просто рисование, а модельный процесс, требующий понимания бизнес-логики.
Начните с перечисления всех систем, которые будут участвовать в интеграции. Различайте системы, которые генерируют данные, и системы, которые их потребляют. Определите организационные границы. Какие потоки данных являются внутренними, а какие выходят за пределы организации?
Перечислите каждый источник и пункт назначения. Это включает:
Нарисуйте стрелки, соединяющие сущности с центральной системой. Обозначьте эти потоки типом передаваемых данных (например, «Сведения о заказе», «Статус запасов»). Заботиться о внутренней логике пока не нужно. Сосредоточьтесь на перемещении данных.
Разбейте центральную систему на логические процессы. Например, вместо одного процесса с названием «Обработка заказа» разбейте его на «Проверка заказа», «Проверка наличия товаров» и «Обработка оплаты». Такое разбиение показывает, где происходит преобразование данных.
Определите, где должны храниться данные. При интеграции это может быть временная зона подготовки или постоянное хранилище. Убедитесь, что каждое хранилище данных связано с процессом, который в него записывает, и с процессом, который из него читает.
Проверьте на наличие распространённых ошибок. Убедитесь, что ни один поток данных не начинается и не заканчивается в ниоткуда. Каждая стрелка должна иметь начало и конец. Убедитесь, что хранилища данных не обходятся, когда данные должны сохраняться.
Создание диаграмм потоков данных для интеграции сопряжено с трудностями. Несогласованность данных и скрытые зависимости — распространённые ошибки. В таблице ниже перечислены типичные проблемы и рекомендуемые подходы к их устранению.
| Проблема | Описание | Решение |
|---|---|---|
| Избыточность данных | Несколько систем независимо хранят одни и те же сведения о клиенте. | Объедините хранилища данных на диаграмме в единый источник достоверной информации, где это возможно. |
| Скрытые зависимости | Потоки данных зависят от фоновых задач, которые не отображены на диаграмме. | Включите асинхронные процессы и фоновые задания как явные процессы на диаграмме потоков данных. |
| Опасные пробелы в безопасности | Незашифрованные данные передаются по публичным сетям. | Обозначьте защищённые потоки и примените процессы шифрования на границах сети. |
| Интерфейсы устаревших систем | Старые системы не имеют стандартных интерфейсов API. | Моделируйте оболочку или промежуточное программное обеспечение, необходимое для преобразования форматов данных. |
| Всплески объёма данных | Поток данных неожиданно возрастает в пиковые периоды. | Добавьте буферные хранилища данных, чтобы поглотить пиковые нагрузки до обработки. |
Чтобы обеспечить, чтобы DFD оставался полезным в течение длительного времени, придерживайтесь этих принципов проектирования. Диаграмма, которая слишком сложна, становится непонятной; слишком простая — неточной.
Интеграция систем редко предполагает передачу данных в точном виде. Форматы изменяются, добавляются поля, вычисляются значения. DFD должен отражать эти преобразования.
Когда данные поступают в систему, им часто требуется стандартизация. Например, формат даты может быть «ДД/ММ/ГГГГ» в одной системе и «ГГГГ-ММ-ДД» в другой. DFD должен показывать узел процесса, специально предназначенный для «стандартизации формата».
Иногда данные комбинируются с другими источниками для повышения ценности. Например, заказ может быть обогащен текущими курсами обмена. Это требует процесса, который извлекает данные из вторичного источника (например, хранилища валют) и объединяет их с основным потоком.
Требования к безопасности часто предписывают скрывать конфиденциальные данные. Если процесс отправляет данные в систему логирования, DFD должен показывать этап преобразования, при котором маскируются номера кредитных карт или социальные номера до выхода данных из защищенной зоны.
Разные архитектурные паттерны по-разному используют потоки данных. Понимание этих паттернов помогает правильно составить DFD.
DFD — это не разовый продукт. Системы развиваются, вводятся новые API, а старые устаревают. Устаревшая диаграмма может привести к ошибкам и уязвимостям безопасности. Поддержка — критический этап жизненного цикла DFD.
Обновления DFD должны запускаться по следующим причинам:
Держите диаграмму связанной с кодовой базой или файлами конфигурации. Когда разработчик изменяет скрипт сопоставления данных, он должен одновременно обновить DFD. Это гарантирует, что документация остается источником истины.
Безопасность — это не дополнение; это фундаментальный аспект потоков данных. При визуализации данных необходимо учитывать, где находятся границы доверия.
Чтобы проиллюстрировать практическое применение, рассмотрим ситуацию, при которой компания продаёт товары через веб-сайт, мобильное приложение и физический магазин.
Сущности включают веб-сайт, мобильное приложение, систему POS и клиента.
Ключевые процессы включают «Приём заказов», «Списание запасов» и «Обработка платежей».
Когда клиент покупает товар:
Эта визуализация ясно показывает, что если хранилище инвентаря вышло из строя, прием заказов может быть успешным, но выполнение заказа не удастся. Эта зависимость видна только на диаграмме.
Диаграммы потоков данных предлагают структурированный способ понимания перемещения информации в сложных интеграциях систем. Они преобразуют абстрактный код и вызовы API в визуальный язык, понятный заинтересованным сторонам. Следуя шагам, описанным здесь, команды могут создать точные карты своей архитектуры данных.
Эффективные диаграммы потоков данных приводят к лучшему проектированию системы, меньшему количеству ошибок интеграции и более четким границам безопасности. Они служат живым документом, который руководит разработкой и сопровождением. В среде, где данные являются наиболее ценным активом, визуализация их пути не является добровольным выбором — это необходимость для достижения операционного превосходства.