 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Анализ систем на протяжении долгого времени полагался на визуальные представления для передачи сложной логики. Диаграмма потоков данных (DFD) по-прежнему является основой этого подхода. Однако ландшафт архитектуры программного обеспечения кардинально изменился. Мы перешли от монолитных приложений к распределенным микросервисам, от локальных баз данных к облачным хранилищам, от синхронных запросов к асинхронным потокам событий. Традиционная DFD, разработанная для более простых линейных процессов, сталкивается с новыми вызовами в этих средах. В этом руководстве рассматривается, как методология развивается, чтобы оставаться актуальной, обеспечивая точное моделирование без устаревания. 🛠️
Прежде чем рассматривать эволюцию, необходимо установить базовый уровень. Стандартная DFD визуализирует поток информации через систему. Она фокусируется на что система делает, а не как это делает. Это различие разделяет моделирование процессов и структурного проектирования. Основные компоненты остаются неизменными на протяжении поколений:
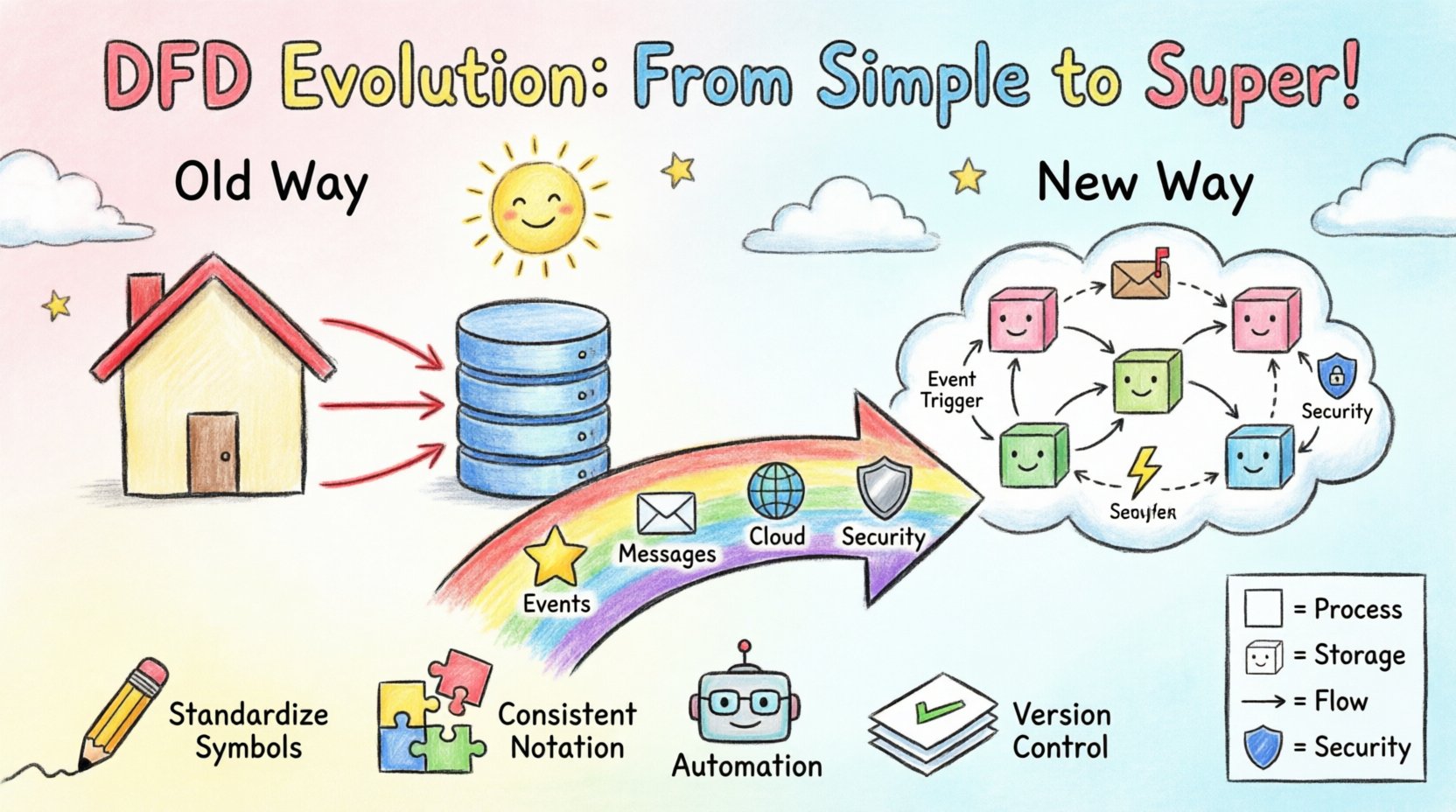
В традиционном контексте эти диаграммы были иерархическими. Диаграмма контекста предоставляла обзор высокого уровня (уровень 0), которая затем разбивалась на детальные диаграммы уровня 1 и уровня 2. Это хорошо работало, когда система имела четкое начало и конец, а данные предсказуемо перемещались от входа к выходу. Однако современные системы часто не имеют единого входного пункта или определенного выхода. Данные постоянно поступают и покидают систему, часто в реальном времени. 🔄
Переход от монолитов к распределенным системам создает трудности для статического моделирования. В монолитном приложении транзакция базы данных может запустить серию вызовов функций, которые завершаются мгновенно. DFD могла бы нарисовать прямую линию от базы данных к процессу и к выходу. В среде микросервисов ситуация намного сложнее.
Современные системы часто полагаются на брокеры сообщений и очереди. Запрос поступает, сохраняется в очереди и позже обрабатывается рабочим процессом. Традиционные DFD плохо отображают время. Они предполагают мгновенный поток. Статическая стрелка не легко передает, что данные могут находиться в буфере несколько часов, прежде чем следующий процесс начнет работу. Это приводит к неоднозначности при анализе поведения системы.
Облачные архитектуры часто используют безсостоятельные контейнеры, которые запускаются и останавливаются. DFD обычно предполагает постоянный процесс. Когда процесс временный, диаграмма должна четко указывать, где хранится состояние (хранилище данных), а где находится логика (вычислительные ресурсы). Если диаграмма не различает эти два аспекта, разработчики могут ошибочно полагать, что состояние сохраняется внутри самого процесса, что приводит к ошибкам.
Старые модели часто рассматривали хранилища данных как универсальные коробки. Современное соответствие требует понимания географического местоположения данных и способа их шифрования. DFD теперь должна указывать на суверенитет данных и уровни безопасности. Если поток данных пересекает зону безопасности, диаграмма должна отражать эту границу, а не только логическое соединение.
Чтобы устранить эти пробелы, практикующие адаптируют стандартную нотацию для поддержки событийно-ориентированной архитектуры (EDA). Основная концепция остается — поток данных, но изменяются триггеры.
Эта адаптация требует смены перспективы. Диаграмма больше не является просто картой системы; это карта инцидентов которые движут системой. Она помогает заинтересованным сторонам понять жизненный цикл данных от создания до окончательного потребления, включая паузы между ними. 🕒
По мере перехода приложений в облако DFD должен соответствовать контрактам API и границам сервисов. Диаграмма служит мостом между бизнес-требованиями и технической реализацией.
Большинство современных систем используют шлюз API. В DFD он заменяет общее «внешнее существо». Шлюз становится конкретным процессом, ответственным за маршрутизацию, аутентификацию и ограничение скорости. Диаграмма должна показывать преобразование входящего запроса в внутреннюю команду. Это уточняет разделение ответственности.
В распределенных базах данных данные часто дробятся. Традиционный символ хранилища данных недостаточен. Диаграмма должна показывать, что процесс может запрашивать несколько фрагментов для сборки ответа. Это визуализирует сложность операций чтения по сравнению с операциями записи. Например, запись может идти в один раздел, а чтение объединяет данные из трех.
Сервисы часто не знают сетевой адрес других сервисов на этапе проектирования. Они обнаруживают их во время выполнения. DFD может отобразить это с помощью узла «Реестр сервисов». Процессы подключаются к реестру, чтобы найти текущий конечный пункт зависимого сервиса. Это добавляет уровень видимости инфраструктуры в логический поток.
Понимание различий помогает командам выбрать правильный уровень абстракции. В следующей таблице перечислены ключевые различия в том, как DFD строятся и интерпретируются сегодня по сравнению с прошлым.
| Функция | Традиционный DFD | Современный DFD |
|---|---|---|
| Направление потока | Синхронный, немедленный | Асинхронный, с задержкой или пакетный |
| Характер процесса | Монолитный, длительный | Микросервис, временный, без состояния |
| Хранение | Централизованная база данных | Фрагментированное, распределенное или объектное хранение |
| Триггеры | Приход входных данных | События, сообщения или запланированные задачи |
| Границы | Периметр системы | Зоны безопасности и шлюзы API |
| Параллелизм | Часто игнорируется | Явно моделируется (очереди, блокировки) |
По мере усложнения диаграмм читаемость становится угрозой. Следующие практики обеспечивают, чтобы DFD оставался полезным инструментом, а не запутанным артефактом.
Безопасность больше не является после мыслью. Она должна быть встроена на этапе проектирования. DFD — отличный инструмент для выявления рисков безопасности, визуализируя, где данные подвергаются утечке.
Каждый раз, когда данные переходят из одного процесса в другой, пересекается граница доверия. В современной системе это может быть переход от публичного API к внутреннему микросервису. DFD должен выделять эти границы. Если поток пересекает границу без шифрования или аутентификации, диаграмма немедленно выявляет уязвимость.
Не все потоки данных имеют одинаковую значимость. Чувствительная информация, такая как ПИИ (персональные данные), требует более строгого обращения. Диаграмма может использовать цветовую кодировку или специальные значки для обозначения чувствительных потоков. Это гарантирует, что при реализации логики разработчики будут уделять приоритетное внимание шифрованию и контролю доступа для этих конкретных путей.
Нормативные акты, такие как GDPR или HIPAA, определяют, как данные должны храниться и перемещаться. Современная DFD может сопоставлять потоки данных с требованиями соответствия. Например, хранилище данных может быть помечено как «Только Европейский регион». Если процесс извлекает данные из этого хранилища в другой регион, диаграмма выявляет потенальное нарушение соответствия. Это позволяет архитекторам устранить проблемы до написания кода.
Одной из главных проблем с DFD является поддержка. По мере изменения кода диаграмма часто устаревает. Современные рабочие процессы стремятся устранить этот разрыв с помощью автоматизации.
Хотя полностью автоматизированные диаграммы еще не идеальны, они создают базовый уровень, который гораздо ближе к реальности, чем статический документ, созданный несколько месяцев назад. Это поддерживает актуальность документации по мере итераций системы. 🔄
Эволюция DFD продолжается. По мере развития технологий совершенствуются и методы моделирования.
Модели машинного обучения вводят неопределённые потоки. Процесс может выдавать разные результаты на основе вероятности, а не фиксированной логики. Будущие DFD могут потребовать отдельного представления интервалов достоверности или потоков обучающих данных по сравнению с потоками вывода. Это добавляет новый измерение узлам хранилища данных и процессов.
Статические диаграммы хороши для проектирования, но что насчёт эксплуатации? Будущие версии могут связывать диаграммы с живыми панелями мониторинга. Если поток данных заблокирован в продакшене, соответствующая стрелка на диаграмме может загореться красным. Это создаёт живой документ, отражающий текущее состояние системы.
В настоящее время нет универсального стандарта для представления событий в DFD. По мере того как отрасль сходится вокруг конкретных шаблонов событий (например, CQRS или Event Sourcing), вероятно, появится стандартизированный набор символов. Это сделает диаграммы взаимодействующими между различными командами и организациями.
Чтобы начать адаптацию ваших текущих практик моделирования, следуйте этой общей последовательности.
Диаграмма потоков данных выжила десятилетия технологических изменений, потому что её основная цель остаётся актуальной: ясность. Хотя нотация должна адаптироваться к микросервисам, облачной инфраструктуре и асинхронным событиям, основная цель визуализации перемещения данных остаётся неизменной. Обновляя символы и лежащую в основе концепцию, команды могут продолжать использовать DFD как основной инструмент анализа системы. Эволюция не заключается в замене метода, а в его совершенствовании для соответствия сложности современной цифровой среды. 🌐