 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Вступление в мир программной инженерии часто предполагает расшифровку сложных чертежей до написания первой строки кода. Среди различных диаграмм, используемых для отображения поведения системы, диаграмма потока данных (DFD) выделяется как критически важный инструмент для понимания того, как информация перемещается через систему. В отличие от кода, который определяеткак выполняется задача, DFD иллюстрируетчто данные обрабатываются и куда они перемещаются. Для нового инженера способность интерпретировать эти диаграммы напрямую приводит к более быстрой адаптации, лучшему пониманию архитектуры системы и улучшению коммуникации с заинтересованными сторонами.
Это руководство разработано для того, чтобы вывести вас от базового понимания символов до тонкой способности анализировать сложные потоки процессов. Мы изучим анатомию DFD, иерархию её уровней и распространённые ловушки, указывающие на ошибки моделирования. В конце вы получите практическую основу для уверенного и точного чтения этих диаграмм.
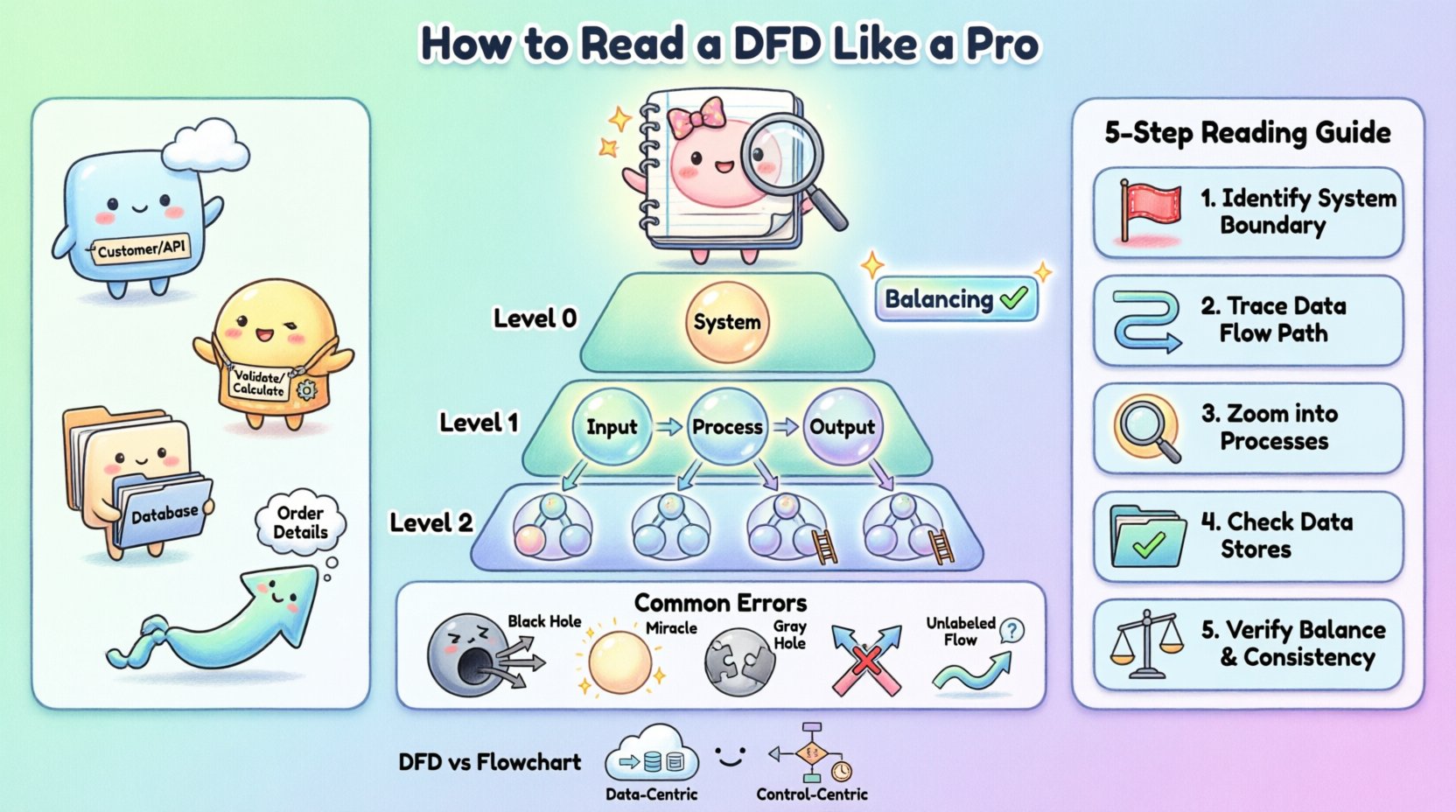
Диаграмма потока данных — это графическое представление потока данных через информационную систему. Она моделирует систему с функциональной точки зрения, фокусируясь на перемещении данных, а не на логике управления или временных интервалах. Это различие имеет решающее значение. В то время как диаграмма последовательности показывает порядок событий, DFD показывает преобразование данных от входа к выходу.
Когда вы смотрите на DFD, вы фактически смотрите на карту логики вашей системы. Вы можете определить:
Откуда берётся данные: Внешние источники или сущности.
Как данные изменяются: Процессы, которые преобразуют входные данные в выходные.
Где данные хранятся: Хранилища данных, где хранится информация.
Куда данные приходят: Конечные пункты или получатели обработанной информации.
Понимание этой цели помогает избежать распространённой ошибки — попытки читать DFD как блок-схему. В стандартной DFD нет циклов, нет ромбов с решениями и нет временной последовательности. Это статический снимок динамического перемещения данных. Такая абстракция мощна, потому что позволяет инженерам обсуждать требования к системе, не застревая в деталях реализации.
Чтобы уверенно читать DFD, сначала необходимо распознать её четыре основных компонента. Хотя стили нотации немного различаются между методологиями, основные концепции остаются неизменными. В следующей таблице перечислены эти элементы и их стандартные визуальные представления.
|
Компонент |
Визуальная форма |
Функция |
Пример |
|---|---|---|---|
|
Внешняя сущность |
Прямоугольник |
Источник или пункт назначения данных вне системы |
Клиент, Администратор, API сторонней компании |
|
Процесс |
Круг или закруглённый прямоугольник |
Преобразует входные данные в выходные данные |
Рассчитать налог, проверить пользователя |
|
Хранилище данных |
Открытый прямоугольник или параллельные линии |
Хранилище, где данные хранятся для последующего использования |
База данных клиентов, файл журнала |
|
Поток данных |
Стрелка |
Направление и название данных, перемещающихся между компонентами |
Сведения об заказе, подтверждение оплаты |
Обратите внимание, что метки на этих компонентах не произвольны. Соглашение об именовании имеет решающее значение для ясности. Процесс должен называться глаголом и существительным (например, «Обновить инвентаризацию»), что указывает на действие, выполняемое с данными. Хранилище данных должно представлять существительное (например, «Журнал инвентаризации»), что означает совокупность записей. Потоки данных должны быть названы так, чтобы описать конкретный содержимое, перемещающееся по стрелке.
Сложные системы нельзя представить в одном диаграмме без того, чтобы она стала непонятной. Чтобы управлять сложностью, DFD структурируются иерархически. Такой подход позволяет приближаться и отдаляться от системы, фокусируясь на высоком уровне логики или деталях по мере необходимости.
Диаграмма контекста предоставляет самый высокий уровень абстракции. Она показывает систему как единый блок процесса и иллюстрирует, как она взаимодействует с внешними сущностями. Здесь не показаны внутренние хранилища данных или подпроцессы. Цель — определить границы системы. Вы увидите систему в центре, окруженную сущностями, которые поставляют ей данные и получают данные от нее. Это первая диаграмма, которую следует изучить, чтобы понять масштаб проекта.
Также известна как диаграмма верхнего уровня, она разбивает единственный блок системы из диаграммы контекста на основные подсистемы или основные процессы. Она раскрывает основные хранилища данных и высокий уровень потока данных между этими основными функциями. Этот уровень необходим для понимания основных модулей программного обеспечения и их взаимосвязей.
Эти диаграммы представляют дальнейшую декомпозицию. Диаграмма уровня 1 детализирует процессы, показанные на диаграмме уровня 0. Диаграмма уровня 2 углубляется в конкретный процесс уровня 1. По мере спуска по иерархии количество процессов и хранилищ данных увеличивается. Однако каждый отдельный процесс на диаграмме нижнего уровня должен соответствовать входам и выходам родительского процесса на более высоком уровне.
Этот концепт известен как сбалансированность. Если процесс уровня 0 имеет вход «Данные заказа» и выход «Квитанция», каждый дочерний процесс в декомпозиции должен в совокупности обеспечивать получение «Данных заказа» и производство «Квитанции». Такая согласованность является ключевым признаком хорошо построенной модели.
Когда вам дают DFD для новой функции или унаследованной системы, не пытайтесь запомнить всю картинку сразу. Вместо этого используйте систематический метод отслеживания. Это гарантирует, что вы не пропустите соединения или не ошибётесь в логике.
Шаг 1: Определите границы.Ищите внешние сущности. Это точки начала и окончания. Задайте себе вопрос: «Кто взаимодействует с этой системой?» Если процесс не имеет соединения с внешней сущностью или хранилищем данных, он может быть изолированным компонентом, требующим дополнительного объяснения.
Шаг 2: Отслеживайте поток данных.Выберите конкретный вход, например, «Запрос на вход». Следуйте стрелке от сущности к процессу. Затем следуйте выходной стрелке к следующему процессу или хранилищу данных. Не прыгайте по диаграмме; следуйте одному пути за раз.
Шаг 3: Анализируйте процессы. Для каждого процесса задайте вопрос: «Какое преобразование происходит?» Соответствуют ли входные данные выходным логически? Например, если процесс называется «Рассчитать скидку», убедитесь, что входные данные включают «Цену» и «Статус членства». Если входные данные отсутствуют, диаграмма неполная.
Шаг 4: Проверьте хранилища данных. Убедитесь, что каждое хранилище данных имеет хотя бы одну операцию чтения (входной поток) и одну операцию записи (выходной поток), если только это не постоянная запись, которая обновляется только изредка. Хранилище данных, которое получает данные, но никогда их не возвращает, может быть ошибкой «стока», а хранилище, которое только возвращает данные, — ошибкой «источника».
Шаг 5: Проверьте балансировку. Если вы смотрите на диаграмму уровня 1, проверьте её по отношению к родительской диаграмме уровня 0. Соответствуют ли входы и выходы? Если родительский процесс говорит «Получить заказ», дочерний процесс также должен получать данные «Заказ». Если дочерний процесс получает «Оплату» вместо этого, диаграмма несбалансирована.
Следуя этой последовательности, вы переходите от макроперспективы к микроперспективе, обеспечивая всестороннее понимание архитектуры системы.
Даже опытные инженеры допускают ошибки при создании диаграмм потоков данных. Как читатель, выявление этих аномалий может сэкономить вам значительное время при разработке. Распознавание этих ошибок помогает задавать правильные вопросы архитекторам системы.
Чёрная дыра возникает, когда процесс имеет входы, но не имеет выходов. Данные входят в процесс и исчезают. В реальной системе это означает потерю данных. Например, если процесс «Обработать пользователя» получает форму входа, но не выдаёт никакого выхода в базу данных или экран подтверждения, данные не имеют места назначения. Это указывает на отсутствующее требование или нарушенный путь логики.
Чудо — это противоположность чёрной дыре. Это процесс, который выдаёт выходные данные, не получая никаких входных данных. Как система может сгенерировать «Отчёт о продажах», не читая «Данные о продажах»? Это означает, что данные создаются из ниоткуда, что невозможно в детерминированной системе. Необходимо определить отсутствующий вход и подключить его к хранилищу данных или внешнему сущности.
Эта ошибка возникает, когда входные и выходные данные процесса не соответствуют друг другу логически, даже если оба существуют. Например, если процесс называется «Рассчитать налог», но вход — «Адрес пользователя», а выход — «Общая цена», преобразование неполное. Отсутствует ставка налога. Это часто указывает на отсутствующее хранилище данных или несвязанный поток.
На чистых диаграммах потоков данных стрелки не должны пересекаться без соединения. Если два потока данных пересекаются, неясно, взаимодействуют ли они или просто проходят мимо. Хотя в сложных диаграммах некоторое пересечение неизбежно, это признак плохой компоновки. В хорошо спроектированной диаграмме потоки должны быть чётко проложены, чтобы избежать путаницы.
Каждая стрелка должна иметь метку. Стрелка без названия означает, что конкретный контент данных неизвестен. Если вы видите стрелку, соединяющую хранилище данных с процессом, вы должны знать, какие данные извлекаются. Метка «Данные» недостаточно конкретна. Должна быть «Список клиентов» или «Активные токены сессии». Неоднозначные метки — основная причина ошибок при реализации.
Одной из наиболее распространённых причин путаницы для начинающих инженеров является различие между диаграммой потоков данных и блок-схемой. Хотя оба используют фигуры и стрелки, их смыслы фундаментально различны.
Фокус: Блок-схема фокусируется на управлению потоком. Она показывает последовательность операций, точки принятия решений (если/иначе) и циклы. Она отвечает на вопрос «Что произойдёт дальше?» Диаграмма потоков данных фокусируется на потоку данных. Она показывает перемещение информации. Она отвечает на вопрос «Куда идут данные?»
Логика против данных: В блок-схеме вы увидите ромбы с решениями. В стандартной диаграмме потоков данных их не будет. Диаграмма потоков данных предполагает, что процесс происходит; она не моделирует логику ветвления этого процесса.
Время: Блок-схемы часто подразумевают временной порядок. Диаграммы потоков данных, как правило, не имеют временной привязки. Диаграмма потоков данных не показывает, какой процесс происходит первым, если только это не подразумевается зависимостями данных.
Хранение: Диаграммы потоков обычно не показывают хранение данных явно. DFD явно моделируют хранилища данных как основной компонент.
Понимание этой разницы предотвращает попытки найти логику управления там, где ее нет. Если вы ищете логику «если это, то то», обратитесь к диаграмме потоков или псевдокоду. Если вы ищете, где обновляется база данных, смотрите на DFD.
Чтение DFD — это не просто академическое упражнение; это ежедневная необходимость для программистов. Вот как эта навык применяется в реальных сценариях.
1. Ввод в работу и проверка кода: Когда вы присоединяетесь к новой команде, документация по архитектуре часто включает DFD. Их чтение позволяет понять зависимости данных до того, как вы коснетесь кода. Во время проверки кода вы можете проверить, соответствует ли реализация диаграмме. Если диаграмма показывает, что данные идут в кэш, а код записывает только в базу данных, вы обнаружили расхождение.
2. Отладка и устранение неполадок: Когда функция не работает, DFD помогает отследить путь данных. Если пользователь сообщает, что его профиль не обновляется, вы можете следовать потоку «Обновление профиля» на DFD. Вы можете проверить, какие процессы задействованы, и какие хранилища данных используются. Это значительно сужает пространство поиска по сравнению с поиском в коде наугад.
3. Сбор требований: При работе с менеджерами продуктов вам часто нужно визуализировать требования. Если вы понимаете DFD, вы можете помочь уточнить требования. Вы можете выявить отсутствующие потоки данных или невозможные преобразования до начала разработки. Такой проактивный подход снижает технический долг.
4. Интеграция систем: В архитектурах микросервисов DFD необходимы для определения контрактов API. Вы можете отобразить потоки данных между сервисами, чтобы убедиться, что выходные данные сервиса A совместимы с входными данными сервиса B. Это предотвращает сбои интеграции, вызванные несоответствием форматов данных.
Чтобы убедиться, что диаграммы, которые вы читаете, остаются полезными с течением времени, рассмотрите следующие практики. Диаграмма, которая устарела, хуже, чем отсутствие диаграммы вообще.
Держите на высоком уровне: Не загромождайте DFD каждым именем переменной. Остаётесь на уровне логических сущностей данных. «Ввод пользователя» лучше, чем «Значение поля имени».
Используйте единый стиль именования: Убедитесь, что «Клиент» на одной диаграмме называется «Клиент» на всех связанных диаграммах. Избегайте синонимов, таких как «Клиент» или «Пользователь», если они не относятся к разным сущностям.
Обновляйте во время изменений: Если код существенно изменяется, DFD должен быть обновлён. Диаграмма с системой контроля версий может служить историей эволюции системы.
Ограничьте сложность: Если одна диаграмма становится слишком перегруженной, пришло время разбить её на диаграммы более низкого уровня. Хорошее правило — на диаграмме уровня 0 должно быть не более 7–10 основных процессов.
Освоение интерпретации диаграмм потоков данных требует терпения и практики. Это включает в себя выход за рамки символов, чтобы понять логические связи между ними. Сосредоточившись на перемещении данных, выявляя аномалии и понимая иерархию, вы оснащаете себя мощным инструментом для анализа систем.
По мере продвижения в своей инженерной карьере вы столкнетесь с различными методами моделирования. DFD остаётся фундаментальным навыком. Он учит мыслить системами через входы, преобразования и выходы. Такой подход применим при проектировании баз данных, архитектуре API и планировании облачной инфраструктуры. Продолжайте практиковаться в чтении этих диаграмм в открытых проектах или внутренней документации. Чем больше вы будете отслеживать потоки, тем интуитивнее станет архитектура системы.