 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Диаграмма потока данных (DFD) — это визуальное представление того, как информация перемещается через систему. Речь идет не о внешнем виде системы, а о том, как данные обрабатываются, хранятся и передаются. Для аналитиков и архитекторов овладение этой нотацией является фундаментальным условием для понимания сложных рабочих процессов без погружения в технические детали реализации.
В этом руководстве мы разберем анатомию DFD. Мы изучим пять основных элементов, из которых состоят эти диаграммы, исследуем, как они взаимодействуют, и приведем практические примеры. В конце вы поймете, какую структурную целостность необходимо обеспечить для создания четкого и действенного картографического представления системы.
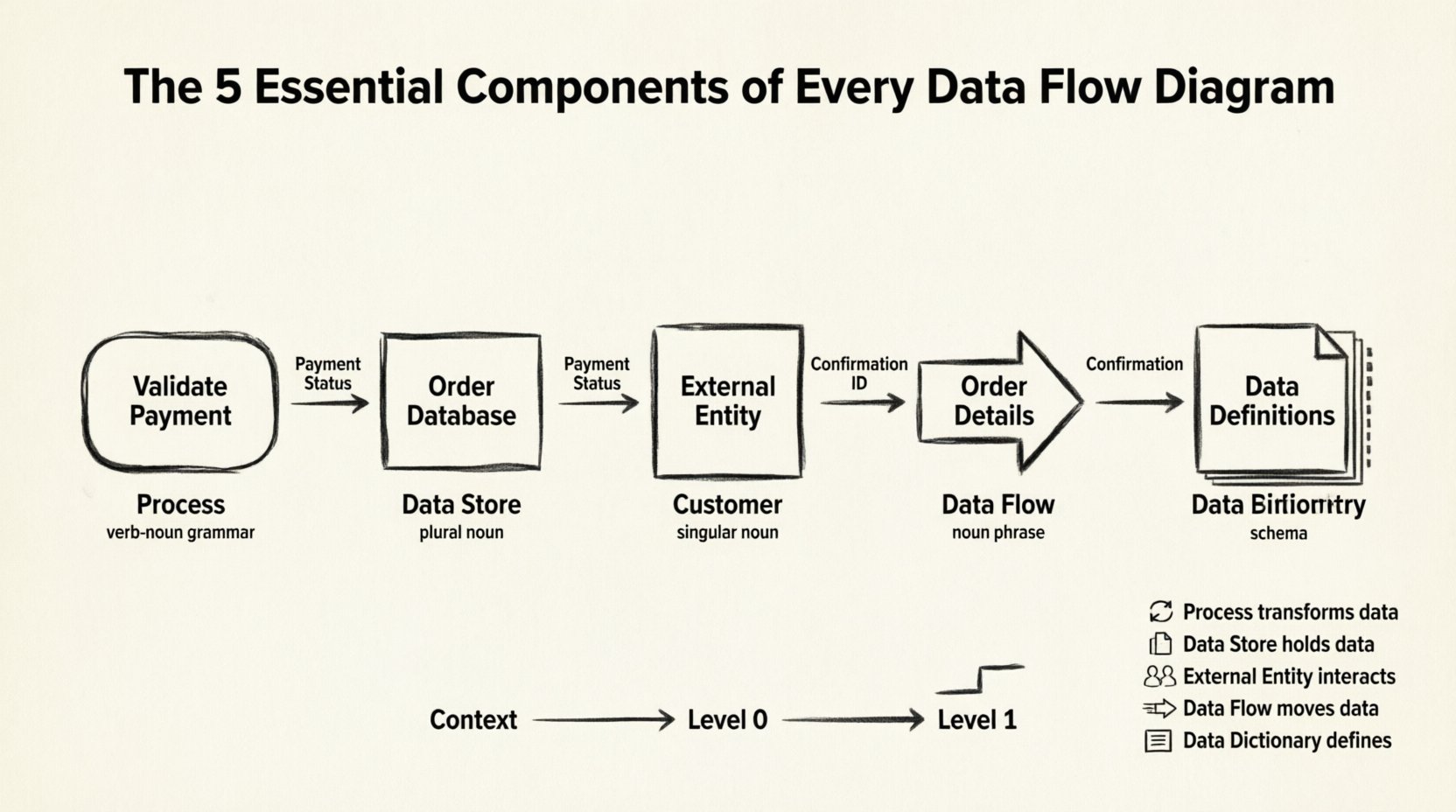
Диаграмма потока данных — это графическое представление движения данных через информационную систему. В отличие от блок-схемы, которая фокусируется на логике управления и точках принятия решений, DFD ориентирована на перемещение данных. Она абстрагируется от физической реализации, чтобы показать логический поток информации.
DFD являются иерархическими. Они начинаются с обзора высокого уровня и постепенно углубляются в конкретные детали. Такой многослойный подход позволяет заинтересованным сторонам быстро понять систему, одновременно давая разработчикам возможность увидеть конкретные требования к данным.
Чтобы построить корректную DFD, необходимо включить пять конкретных элементов. Хотя первые четыре являются графическими символами, пятый — это концептуальное требование, необходимое для точности.
Процесс представляет собой функцию, преобразующую входные данные в выходные. Это движущая сила системы. В DFD процесс часто изображается в виде закругленного прямоугольника или круга в зависимости от стиля нотации (Yourdon/DeMarco против Gane/Sarson).
Ключевые характеристики:
Пример:Рассмотрим систему электронной коммерции. Процесс может быть«Проверить оплату». Он получает данные кредитной карты (вход) и возвращает код одобрения или отказа (выход).
Хранилище данных — это место, где информация хранится для последующего использования. Оно представляет базу данных, файл, бумажный файловый шкаф или любой механизм постоянного хранения. Критически важно, что хранилище данных не обрабатывает данные, оно лишь их хранит.
Ключевые характеристики:
Пример:В системе библиотеки «Инвентаризация книг»хранилище данных хранит сведения о доступных книгах. Оно обновляется при выдаче или возврате книги.
Внешние сущности — это источники или пункты назначения данных за пределами моделируемой системы. Они представляют людей, организации или другие системы, взаимодействующие с основной системой, но не входящие в её внутреннюю логику.
Ключевые характеристики:
Пример:В системе расчёта зарплаты «Сотрудник»является внешней сущностью, предоставляющей отработанные часы и получающей заработную плату.
Потоки данных — это стрелки, соединяющие процессы, хранилища данных и внешние сущности. Они представляют движение данных. Поток данных должен иметь имя, описывающее содержимое передаваемых данных.
Ключевые характеристики:
Пример: Стрелка, соединяющая «Вход» процесс с «База данных пользователей» хранилище данных будет помечено как «Запрос аутентификации».
Хотя на диаграмме не отображается, словарь данных является пятым важным компонентом полного описания DFD. Это централизованный репозиторий, определяющий структуру, тип и формат каждого элемента данных, используемого на диаграмме. Без него диаграмма будет неоднозначной.
Ключевые характеристики:
Пример: Словарь может определить «Дата рождения» как ГГГГ-ММ-ДД без пустых значений. Это предотвращает логические ошибки в процессах.
Используйте эту таблицу для быстрого обращения к свойствам каждого компонента на этапе проектирования.
| Компонент | Форма символа | Функция | Пример метки | Правило грамматики |
|---|---|---|---|---|
| Процесс | Округлённый прямоугольник / Круг | Преобразует данные | Рассчитать налог | Глагол + Существительное |
| Хранилище данных | Открытый прямоугольник / Параллельные линии | Хранит данные | История заказов | Существительное (множественное число) |
| Внешняя сущность | Квадрат / Прямоугольник | Источник/Поток | Банковская система | Существительное (единственное число) |
| Поток данных | Стрелка | Передвигает данные | Сведения об оплате | Существительная фраза |
| Словарь данных | Документ / Список | Определяет данные | Определения данных | Техническая схема |
DFD редко рисуют изолированно. Они существуют в иерархии, которая позволяет использовать разные уровни абстракции. Понимание этих уровней гарантирует правильное применение пяти компонентов на каждом этапе.
Это самый высокий уровень представления. Он показывает всю систему как единый процесс. Определяются внешние сущности и основные потоки данных, входящие в систему или покидающие ее.
Эта схема раскрывает единственный процесс из диаграммы контекста на основные подпроцессы. Вводится первый уровень внутренних хранилищ данных и процессов.
На этом уровне процессы уровня 0 разбиваются на составляющие функции. Используется для детального проектирования и разработки.
Создание диаграммы потоков данных — это итеративный процесс. Чтобы обеспечить полезность и точность диаграммы, соблюдайте эти структурные правила.
Когда вы разбиваете процесс на более низкие уровни, входы и выходы должны оставаться согласованными. Если родительский процесс получает «данные заказа», дочерние процессы должны совместно обрабатывать те же самые «данные заказа». Вы не можете создавать данные из ничего или уничтожать их.
Согласованность — ключевое условие. Используйте единый стандарт именования для всех компонентов. Избегайте сокращений, если они не являются общепринятыми в вашей организации. Убедитесь, что поток данных, обозначенный как «Счет» на одной диаграмме, не обозначен как «Счет-фактура» на другой.
Частая ошибка — смешение логики управления (if/else) с диаграммой потока данных. Диаграммы потока данных показывают перемещение данных, а не логику принятия решений. Для логики управления используйте таблицу решений или блок-схему. На диаграмме потока данных точка принятия решения представляется процессом, который выводит различные потоки данных в зависимости от входных данных.
Хранилища данных должны иметь как входы, так и выходы, за исключением случаев, когда это новое создание или архив. Хранилище, которое принимает данные, но не выдает их, — это черная дыра. Хранилище, которое только выдает данные, — это чудо (создание из ничего). Оба случая нарушают логику системы.
Даже опытные моделисты допускают ошибки. Просмотр этих распространённых ошибок может сэкономить время на этапе анализа.
Применим пять компонентов к реальной ситуации. Представим упрощённую систему онлайн-заказов.
DFD не существуют в вакууме. Они часто дополняют другие методы моделирования.
Чтобы убедиться, что ваши диаграммы потоков данных приносят пользу, помните о следующих принципах.
Соблюдая строго эти пять компонентов и следуя структурным правилам, вы создаете надежный чертеж для разработки системы. Эта ясность уменьшает неопределенность, минимизирует повторную работу и обеспечивает соответствие окончательной реализации запланированной архитектуре данных.
Помните, что DFD — это живой документ. По мере изменения требований диаграмма должна развиваться, отражая новую реальность системы. Регулярное обслуживание диаграммы и сопутствующего словаря данных — признак зрелого процесса анализа.