 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











A metodologia Ágil promete flexibilidade, agilidade e melhoria contínua. No entanto, a realidade frequentemente inclui contratempos. Um sprint falhado não é uma anomalia; é um ponto de dados. Compreender como uma equipe lidará com o fracasso determina o sucesso de longo prazo mais do que comemorar ciclos perfeitos.
Este artigo analisa um cenário específico em que uma equipe de desenvolvimento falhou completamente em atingir seus objetivos de sprint. Exploraremos os fatores técnicos e humanos envolvidos, o processo de retrospectiva usado para diagnosticar o problema e as ações concretas tomadas para restaurar velocidade e qualidade.
Para entender o fracasso, primeiro precisamos compreender a estrutura. A organização opera com um modelo de equipe multifuncional. O grupo é composto por cinco desenvolvedores, um proprietário do produto e um testador dedicado. O trabalho é organizado em ciclos de duas semanas.
A equipe utilizou uma placa de acompanhamento física e digital para gerenciar o fluxo. As histórias foram movidas de Backlog para Em Andamento e finalmente para Concluído. O objetivo era a entrega consistente de valor sem comprometer a qualidade do código.
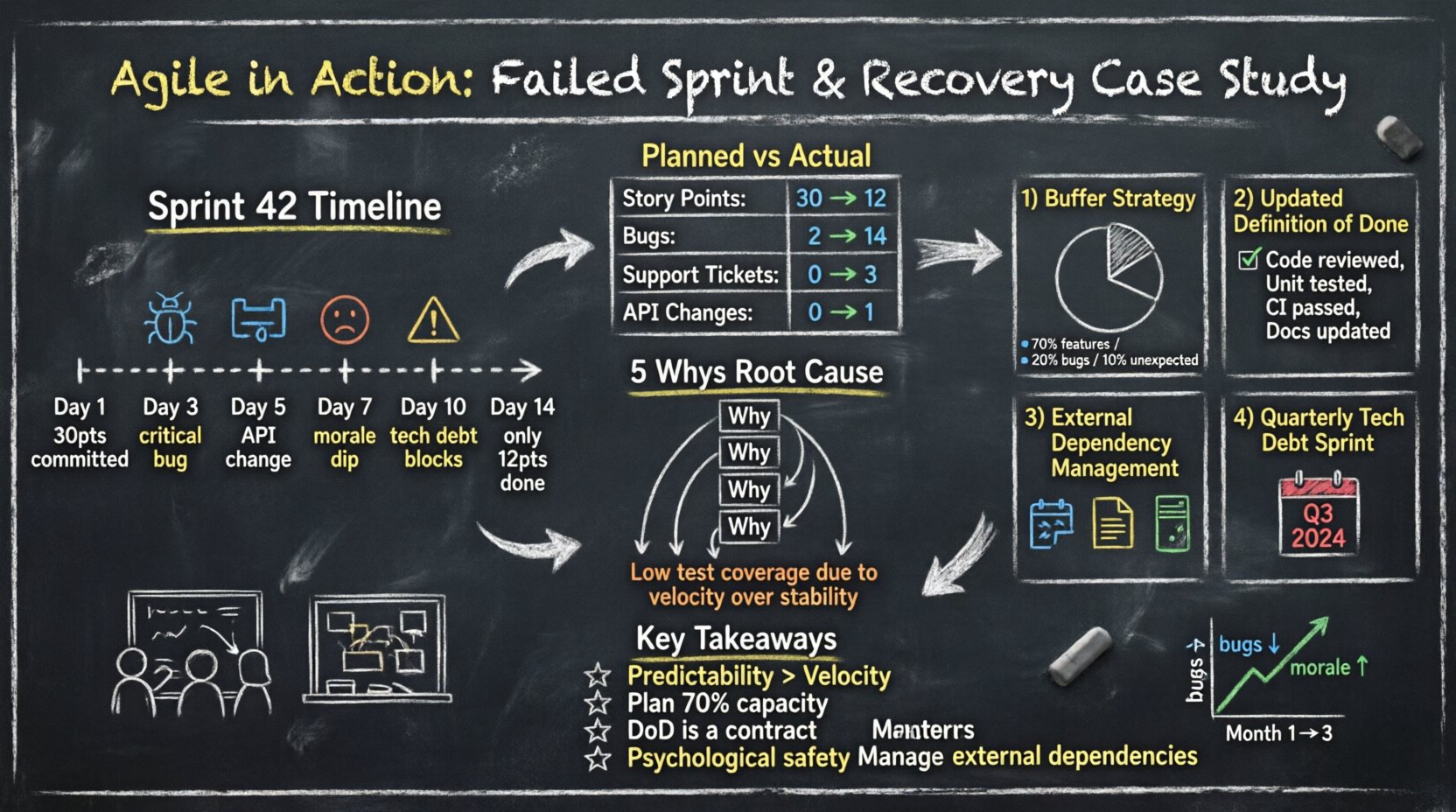
O Sprint 42 começou com grande impulso. A equipe retirou 30 pontos de história do backlog. No terceiro dia, o ritmo parecia estável. No quinto dia, atritos surgiram. No décimo dia, a equipe percebeu que não completaria o trabalho comprometido.
O fracasso não foi causado por um único evento catastrófico. Foi uma série acumulativa de problemas que reduziram a capacidade.
Números contam uma história mais clara do que sentimentos. A tabela a seguir ilustra a diferença entre o esforço planejado e a entrega real.
| Categoria | Planejado | Real | Diferença |
|---|---|---|---|
| Pontos de História Concluídos | 30 | 12 | -18 |
| Falhas Encontradas (Durante o Sprint) | 2 | 14 | +12 |
| Tickets de Suporte Atendidos | 0 | 3 | +3 |
| Mudanças em Dependências Externas | 0 | 1 | +1 |
Esses dados revelam uma grande desvios de recursos. O que começou como trabalho de desenvolvimento transformou-se em manutenção e gestão de crise.
Atribuir culpa a indivíduos não resolve problemas sistêmicos. A equipe realizou uma análise da causa raiz isenta de culpa para identificar os problemas subjacentes.
Para aprofundar, a equipe aplicou a 5 Porquês método à questão dos prazos perdidos.
O problema central não era a precisão do planejamento; era a prática sustentável de engenharia.
Uma retrospectiva é o motor da melhoria ágil. No entanto, um sprint falhado exige um tipo específico de retrospectiva. Formatos padrão muitas vezes parecem uma tarefa de verificação. Esta sessão exigiu segurança psicológica e investigação profunda.
Antes da reunião, o proprietário do produto coletou dados. A equipe foi convidada a refletir individualmente sobre o que deu certo e o que não deu. Isso garantiu que membros mais reservados tivessem tempo para formular suas ideias.
A equipe discutiu o conceito de planejamento de capacidade. Eles perceberam que haviam comprometido 100% do seu tempo com novos recursos. Não havia espaço para as interrupções inevitáveis que ocorrem em ambientes de produção.
Eles também abordaram o Definição de Concluído. Atualmente, ‘Concluído’ significava ‘Código Escrito’. Não incluía ‘Código Revisado’ ou ‘Testes Escritos’. Essa discrepância causou um gargalo no final do sprint.
Conhecer o problema é apenas metade da batalha. O plano de recuperação exigiu mudanças no fluxo de trabalho, nas expectativas e nos padrões técnicos.
A equipe parou de comprometer 100% das suas horas disponíveis. Eles adotaram uma estratégia de buffer.
Essa mudança reduziu a pressão para entregar números perfeitos e permitiu uma gestão realista das interrupções.
A equipe atualizou sua checklist de DoD. Uma história não poderia avançar para Concluído sem atender a esses critérios:
Isso impediu que a dívida técnica se acumulasse silenciosamente. Garantiu que o que foi entregue fosse verdadeiramente utilizável.
Canais de comunicação com fornecedores externos foram formalizados. A equipe agora exige:
A equipe concordou em dedicar um sprint a cada trimestre especificamente à redução da dívida técnica. Isso evita o efeito de juros compostos do código ruim. Sinaliza para os interessados que a estabilidade é uma característica, e não algo posterior.
As mudanças foram implementadas imediatamente na Sprint 43. A recuperação não foi instantânea, mas a trajetória mudou.
A equipe não buscou retornar à antiga velocidade de 30 pontos. Ela buscou previsibilidade. É melhor comprometer-se com menos e entregar de forma consistente do que se comprometer excessivamente e falhar.
Para garantir que a recuperação permanecesse, a equipe acompanhou métricas específicas nos próximos três meses.
| Semana | Objetivo do Sprint Atendido | Quantidade de Bugs | Morale da Equipe (1-5) |
|---|---|---|---|
| Mês 1 | Sim | 12 | 3 |
| Mês 2 | Sim | 8 | 4 |
| Mês 3 | Sim | 5 | 5 |
Os dados mostram uma correlação clara entre as mudanças no processo e a saúde da equipe. Menos bugs levaram a menos estresse, o que melhorou o moral.
Falhar é um professor. Aqui estão as lições aprendidas com este estudo de caso que se aplicam a qualquer ambiente ágil.
Velocidade sem estabilidade é uma ilusão. As equipes devem priorizar a entrega consistente em vez da produção bruta. Os stakeholders confiam nas equipes que cumprem suas promessas, mesmo que essas promessas sejam menores.
Sempre planeje para o imprevisto. Se você tem 100 horas disponíveis, planeje 70 horas de trabalho. O tempo restante absorve a fricção inevitável do desenvolvimento de software.
A DoD não é uma sugestão. É um contrato entre a equipe e o proprietário do produto. Se uma história não atender à DoD, ela não está pronta para lançamento.
Quando as coisas dão errado, a equipe deve se sentir segura para falar. Se os membros temem punição, esconderão problemas até que se tornem crises.
O software não existe em um vácuo. As dependências de serviços de terceiros devem ser gerenciadas com o mesmo rigor do código interno.
Muitas equipes tentam corrigir falhas trabalhando mais. Esse é um erro comum. As seguintes ações devem ser evitadas durante um período de recuperação.
O objetivo do ágil não é apenas entregar código, mas construir um sistema capaz de entregar código indefinidamente. A velocidade sustentável é a base desse sistema.
Após a recuperação, a equipe estabeleceu um ritmo contínuo de melhoria. A cada duas semanas, eles revisam não apenas o sprint, mas a saúde do fluxo de trabalho. Eles fazem perguntas como:
Essa análise contínua evita que pequenos problemas se tornem grandes falhas novamente.
A transparência com os stakeholders é crucial. Quando um sprint falha, comunique cedo. Explique o impacto, a causa e o plano. Isso constrói confiança.
Os stakeholders frequentemente veem um sprint falho como incompetência. Quando explicado como um ponto de dados para melhoria, torna-se uma demonstração de maturidade profissional. Eles preferem uma equipe que reconhece um problema e o corrige a uma equipe que esconde o problema.
Falhas são normais. Uma taxa de erro de 10% é frequentemente aceitável, dependendo do domínio. Taxas altas e constantes de erro indicam um problema sistêmico de planejamento.
Normalmente, não. Parar um sprint desperdiça o tempo já gasto. É melhor concluir o que puder ser concluído e reiniciar para o próximo ciclo.
Sim, se sua velocidade for artificialmente inflada por compromissos excessivos. Reduzi-la para corresponder à realidade melhora a precisão e a previsibilidade.
Soluções de curto prazo são possíveis, mas a recuperação de longo prazo exige mudança de processo. Caso contrário, o fracasso se repetirá.
O Agile é uma jornada de adaptação. Um sprint falhado não é o fim do caminho; é um sinal indicando o caminho para práticas melhores. Ao analisar profundamente o fracasso e implementar mudanças estruturais, as equipes podem surgir mais fortes e resilientes.