 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Nos estágios iniciais da construção de uma empresa de tecnologia, clareza é moeda. Fundadores muitas vezes mergulham diretamente na codificação sem visualizar plenamente o movimento subjacente dos dados. Esse abordagem frequentemente leva a dívida técnica e sessões complexas de depuração posteriormente. Um Diagrama de Fluxo de Dados (DFD) oferece um método estruturado para visualizar como as informações se movem através de um sistema. Este guia explora um cenário do mundo real em que uma startup utilizou essa metodologia para esclarecer sua arquitetura antes de escrever uma única linha de código.
Considere uma startup hipotética chamada “FlowState”, que tem como objetivo construir uma plataforma de gerenciamento de projetos para equipes remotas. A proposta central de valor envolve a atribuição de tarefas, atualizações de status em tempo real e relatórios automatizados. A equipe fundadora enfrentou um problema comum: tinham uma compreensão vaga de como os dados dos usuários deveriam viajar da interface até o banco de dados e de volta.
Sem um mapa claro, a equipe de desenvolvimento corria o risco de:
A solução não foi mais reuniões, mas uma modelagem melhor. Eles adotaram o método de Diagrama de Fluxo de Dados para documentar a lógica do sistema. Essa abordagem permitiu que vissem o sistema como uma série de transformações, e não como um banco de dados estático.
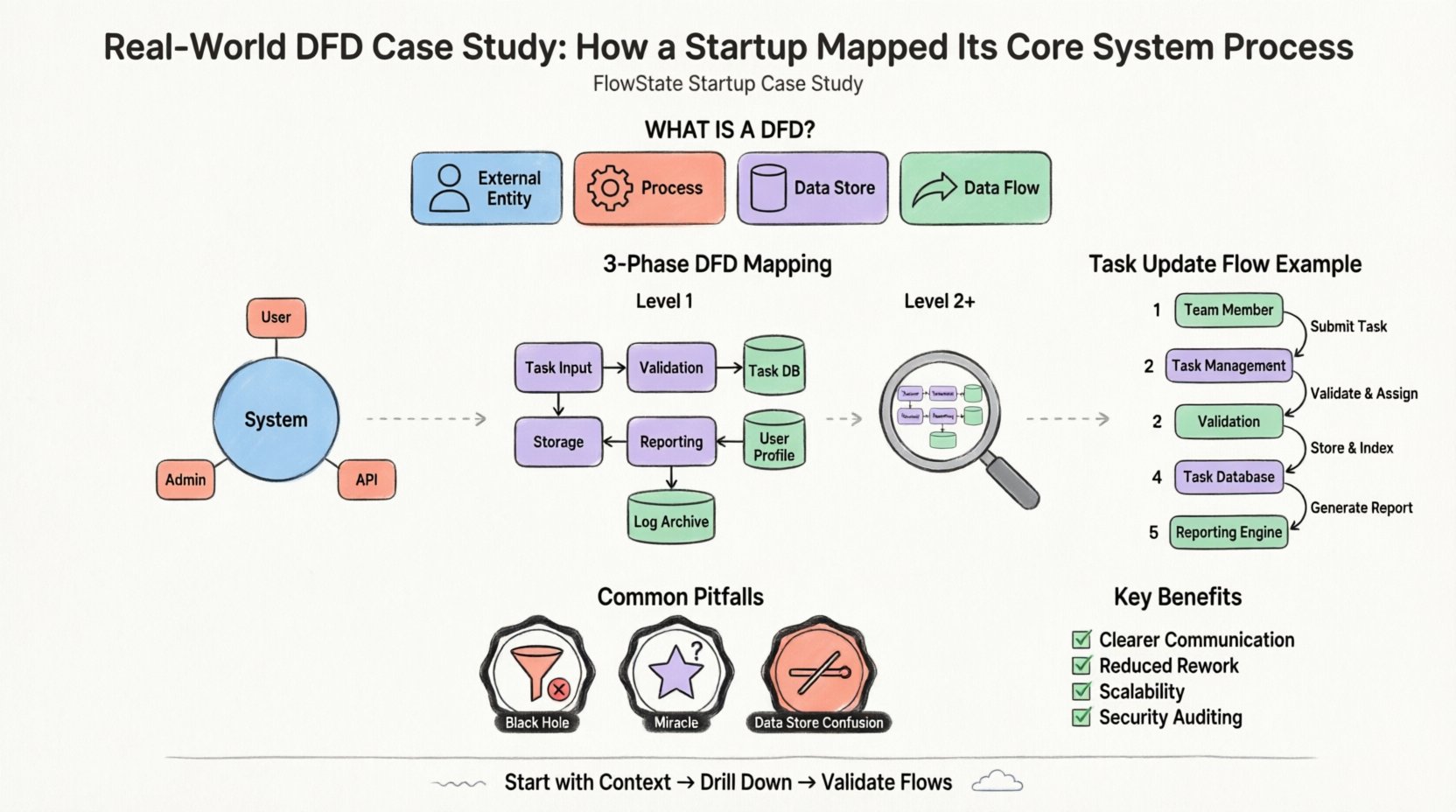
Um Diagrama de Fluxo de Dados é uma representação gráfica do fluxo de dados através de um sistema de informação. Ele não mostra o tempo de execução dos processos nem a lógica de tomada de decisões (como um algoritmo), mas sim o movimento de dados desde uma origem até um destino. Ele se concentra no o que, e não no como.
Os componentes padrão usados nesta técnica de modelagem incluem:
Ao dividir o projeto FlowState em estes componentes, a equipe pôde identificar gargalos e garantir a integridade dos dados antes da implementação.
O primeiro passo no mapeamento do sistema é o Diagrama de Contexto. Trata-se de uma visão de alto nível que define a fronteira do sistema. Ele mostra o sistema como um único processo e como ele interage com entidades externas.
Para o FlowState, o limite é a própria aplicação de gerenciamento de projetos. Tudo o que está dentro faz parte do sistema; tudo o que está fora é uma entidade. A equipe identificou três entidades externas principais:
A equipe desenhou setas para representar os fluxos de entrada e saída. Por exemplo:
Este único diagrama esclareceu o escopo. Evitou que a equipe incluísse acidentalmente recursos como “Processamento de Faturamento” caso esse não fizesse parte do sistema principal naquele momento. Estabeleceu um contrato claro entre o sistema e seus usuários.
Assim que o contexto de alto nível foi estabelecido, a equipe precisou entender o funcionamento interno. Isso é alcançado por meio da Decomposição de Nível 1. O único processo do Diagrama de Contexto é expandido em sub-processos.
O “Sistema FlowState” foi dividido em grupos funcionais lógicos. A equipe identificou os seguintes processos principais:
Crucialmente, o diagrama de Nível 1 introduziu armazenamentos de dados. Isso mostra onde as informações são persistidas. A equipe identificou três armazenamentos principais:
Ao nomear explicitamente esses armazenamentos, os desenvolvedores puderam imediatamente identificar quais dados precisavam ser gravados no banco de dados em vez de serem mantidos na memória temporária.
Com a estrutura de Nível 1 em vigor, a equipe revisou os dados específicos que fluíam entre processos e armazenamentos. Esta etapa é frequentemente onde erros são detectados cedo.
Vamos rastrear o movimento de um único ponto de dados: uma “Mudança de Status de Tarefa.”
Este rastreamento revelou um problema potencial. A equipe percebeu que o “Motor de Relatórios” estava sendo acionado manualmente toda vez que uma tarefa era alterada. Eles decidiram otimizar isso, acionando o processo de relatório apenas quando uma bandeira específica “Status = Concluído” fosse definida, reduzindo a carga do sistema.
Compreender a diferença entre os níveis de diagramas é vital para manter a clareza conforme o projeto cresce. A tabela abaixo descreve as diferenças.
| Nível | Foco | Melhor Usado Para |
|---|---|---|
| Contexto (Nível 0) | Fronteira do Sistema | Comunicação de alto nível com partes interessadas |
| Nível 1 | Processos Principais | Planejamento arquitetônico e definição de escopo |
| Nível 2+ | Detalhes do Subprocesso | Lógica específica de implementação e depuração |
Mesmo com uma metodologia clara, as equipes frequentemente cometem erros ao criar esses diagramas. A equipe do FlowState enfrentou várias dificuldades e aprendeu a evitá-las.
Um processo que tem entrada mas nenhuma saída é um buraco negro. Os dados entram e desaparecem. No rascunho inicial, o “Gerenciador de Notificações” recebia dados, mas não tinha nenhuma seta saindo dele em direção à entidade externa. A equipe percebeu que havia esquecido de definir o mecanismo real de envio. Todo processo deve ter uma saída.
Um processo que tem saída mas nenhuma entrada é um milagre. Isso implica que os dados são criados do nada. A equipe inicialmente tinha um processo “Gerar Relatório” que produzia dados sem ler da “Banco de Dados de Tarefas”. Corrigiram isso adicionando um fluxo de dados da loja para o processo.
Processos interagem com armazenamentos de dados, mas entidades não. No início, a equipe desenhou uma linha diretamente do “Membro da Equipe” para o “Banco de Dados de Tarefas”. Isso viola a regra de que os dados devem passar por um processo para serem transformados ou validados. Todos os dados que tocam um armazenamento devem passar por um processo primeiro.
Uma das regras mais críticas na metodologia DFD é o equilíbrio. As entradas e saídas de um processo pai devem corresponder às entradas e saídas de seu diagrama filho (a decomposição).
Para o FlowState, o processo “Gestão de Tarefas” no diagrama de Nível 1 tinha entradas específicas (Dados da Tarefa) e saídas (Atualização de Status). Quando o dividiram em diagramas de Nível 2 (por exemplo, “Criar Tarefa”, “Excluir Tarefa”), garantiram que os fluxos combinados ainda corresponderiam ao processo pai. Isso garante que nenhum dado seja perdido ou criado durante a decomposição.
Por que investir tempo nesta fase de documentação? Os benefícios vão além do mapeamento inicial.
Antes de passar para o desenvolvimento, a equipe do FlowState usou a seguinte checklist para validar seu trabalho.
A transição de um conceito para um produto funcional exige mais do que apenas habilidades de programação. Exige uma compreensão profunda do ecossistema de informações que você está construindo. Ao mapear os fluxos de dados, a FlowState garantiu que sua arquitetura fosse sólida antes da implantação.
Este estudo de caso destaca que um Diagrama de Fluxo de Dados não é apenas um exercício de desenho. É uma ferramenta de pensamento crítico. Força a equipe a fazer perguntas difíceis sobre de onde os dados vêm, para onde vão e como mudam. Para qualquer startup que deseja construir um sistema robusto, investir tempo nesta fase de modelagem é uma vantagem estratégica.
Lembre-se, o objetivo não é a perfeição na primeira versão. O objetivo é a clareza. Comece com o contexto, desça até os processos e valide os fluxos. Essa abordagem disciplinada leva a sistemas mais fáceis de manter, seguros e escaláveis.
Ao iniciar o mapeamento do seu próprio projeto, mantenha esses princípios em mente. Foque no movimento dos dados, respeite os limites e valide cada conexão. O seu futuro eu agradecerá pela clareza estabelecida hoje.