 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Wchodzi w świat inżynierii oprogramowania często wiąże się z rozszyfrowywaniem skomplikowanych projektów przed napisaniem jednej linii kodu. Wśród różnych diagramów używanych do mapowania zachowania systemu, diagram przepływu danych (DFD) wyróżnia się jako kluczowy narząd do zrozumienia, jak informacje poruszają się przez system. W przeciwieństwie do kodu, który określajak jak zadanie jest wykonywane, DFD ilustrujeco dane są przetwarzane i gdzie się poruszają. Dla nowego inżyniera umiejętność interpretowania tych diagramów bezpośrednio przekłada się na szybsze wdrożenie, lepsze zrozumienie architektury systemu oraz poprawioną komunikację z zaangażowanymi stronami.
Ten przewodnik został stworzony, aby przejść Cię od podstawowego zrozumienia symboli do subtelnej umiejętności analizy złożonych przepływów procesów. Przeanalizujemy anatomię DFD, hierarchię jego poziomów oraz typowe pułapki wskazujące na błędy modelowania. Na końcu będziesz miał praktyczny szablon do czytania tych diagramów z pewnością i precyzją.
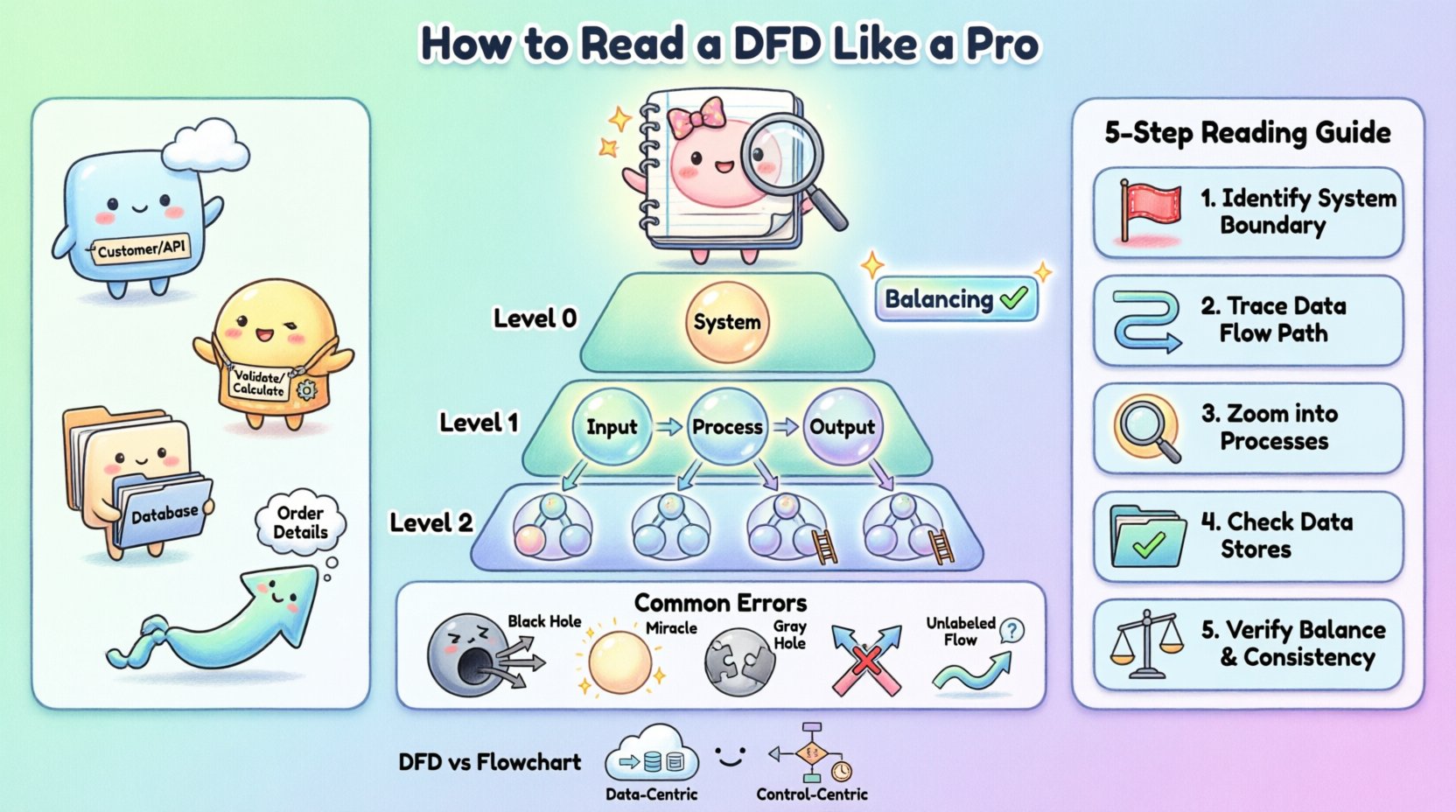
Diagram przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. Modeluje system z perspektywy funkcjonalnej, skupiając się na ruchu danych, a nie na logice sterowania ani czasie. Ta różnica jest kluczowa. Podczas gdy diagram sekwencji pokazuje kolejność zdarzeń, DFD pokazuje przekształcenie danych od wejścia do wyjścia.
Gdy patrzysz na DFD, właściwie patrzysz na mapę logiki swojego systemu. Możesz zidentyfikować:
Skąd pochodzi dane: Zewnętrzne źródła lub jednostki.
Jak dane się zmieniają: Procesy, które przekształcają dane wejściowe w wyjściowe.
Gdzie dane się przechowują: Magazyny danych, gdzie przechowywane są informacje.
Dokąd dane trafiają: Miejsca docelowe lub odbiorcy przetworzonych informacji.
Zrozumienie tego celu pomaga uniknąć częstego błędu polegającego na próbie odczytania DFD jak schemat blokowy. W standardowym DFD nie ma pętli, nie ma diamentu decyzyjnego, ani sekwencji opartej na czasie. Jest to statyczny obraz dynamicznego przepływu danych. Ta abstrakcja jest potężna, ponieważ pozwala inżynierom dyskutować o wymaganiach systemu, nie wchodząc w szczegóły implementacji.
Aby czytać DFD z biegłością, najpierw musisz rozpoznać jego cztery podstawowe komponenty. Choć style notacji nieco się różnią między metodologiami, podstawowe koncepcje pozostają spójne. Poniższa tabela przedstawia te elementy oraz ich standardowe reprezentacje wizualne.
|
Komponent |
Kształt wizualny |
Funkcja |
Przykład |
|---|---|---|---|
|
Zewnętrzna jednostka |
Prostokąt |
Źródło lub miejsce docelowe danych poza systemem |
Klient, Administrator, API strony trzeciej |
|
Proces |
Koło lub prostokąt z zaokrąglonymi rogami |
Przekształca dane wejściowe w dane wyjściowe |
Oblicz podatek, zwaliduj użytkownika |
|
Magazyn danych |
Otwarty prostokąt lub równoległe linie |
Repozytorium, w którym dane są przechowywane do późniejszego użytku |
Baza danych klientów, plik dziennika |
|
Przepływ danych |
Strzałka |
Kierunek i nazwa danych przemieszczających się między składnikami |
Szczegóły zamówienia, potwierdzenie płatności |
Zwróć uwagę, że etykiety na tych składnikach nie są dowolne. Zasady nazywania są kluczowe dla jasności. Proces powinien być nazwany za pomocą czasownika i rzeczownika (np. „Aktualizuj magazyn”), co wskazuje na działanie wykonywane na danych. Magazyn danych powinien reprezentować rzeczownik (np. „Dziennik magazynu”), czyli zbiór rekordów. Przepływy danych muszą być nazwane w taki sposób, aby opisać konkretne dane przemieszczające się wzdłuż strzałki.
Złożone systemy nie mogą być przedstawione na jednym diagramie bez utraty czytelności. Aby zarządzać złożonością, DFD są strukturalnie ułożone hierarchicznie. Ten podejście pozwala na przybliżanie i oddalanie się od systemu, skupiając się na logice najwyższego poziomu lub szczegółach szczegółowych, w zależności od potrzeb.
Diagram kontekstowy zapewnia najwyższy poziom abstrakcji. Pokazuje system jako pojedynczą bąbelkową operację i ilustruje sposób jego interakcji z zewnętrznymi jednostkami. Tutaj nie są pokazywane żadne wewnętrzne magazyny danych ani podprocesy. Celem jest zdefiniowanie granic systemu. Uwidzisz system w centrum, otoczony jednostkami, które dostarczają mu danych i otrzymują dane od niego. Jest to pierwszy diagram, który powinieneś przejrzeć, aby zrozumieć zakres projektu.
Znany również jako diagram najwyższego poziomu, dzieli pojedynczy bąbel systemu z diagramu kontekstowego na główne podsystemy lub główne procesy. Ujawnia główne magazyny danych oraz ogólny przepływ danych między tymi głównymi funkcjami. Ten poziom jest kluczowy do zrozumienia głównych modułów oprogramowania oraz ich wzajemnych relacji.
Te diagramy przedstawiają dalszą dekompozycję. Diagram poziomu 1 szczegółowo opisuje procesy pokazane na diagramie poziomu 0. Diagram poziomu 2 głębiej analizuje konkretny proces z poziomu 1. Im głębiej wchodzisz w hierarchię, tym więcej procesów i magazynów danych pojawia się. Jednak każdy pojedynczy proces na diagramie niższego poziomu musi być spójny z danymi wejściowymi i wyjściowymi procesu nadrzędnego na wyższym poziomie.
Ten koncept nazywa sięzrównoważeniem. Jeśli proces poziomu 0 ma dane wejściowe „Dane zamówienia” i dane wyjściowe „Paragon”, każdy proces potomny w dekompozycji musi wspólnie uwzględniać odbiór „Danych zamówienia” i produkcję „Paragonu”. Ta spójność jest kluczowym wskaźnikiem dobrze skonstruowanego modelu.
Gdy otrzymasz DFD dla nowej funkcji lub starszego systemu, nie próbuj zapamiętać całego obrazu naraz. Zamiast tego użyj systematycznej metody śledzenia. Zapewnia to, że nie przegapisz połączeń ani nie zrozumiesz niepoprawnie logiki.
Krok 1: Zidentyfikuj granice.Szukaj jednostek zewnętrznych. Są to punkty początkowe i końcowe. Zadaj sobie pytanie: „Kto interakcjonuje z tym systemem?” Jeśli proces nie ma połączenia z jednostką zewnętrzną ani magazynem danych, może to być izolowany składnik wymagający dalszego wyjaśnienia.
Krok 2: Śledź przepływ danych.Wybierz konkretny wejście, np. „Prośba o logowanie”. Śledź strzałkę od jednostki do procesu. Następnie śledź strzałkę wyjściową do następnego procesu lub magazynu danych. Nie skakaj po diagramie; śledź jedną drogę naraz.
Krok 3: Analizuj procesy. Dla każdego procesu zapytaj: „Jaka jest przemiana?”. Czy dane wejściowe logicznie pasują do danych wyjściowych? Na przykład, jeśli proces nazywa się „Oblicz zniżkę”, upewnij się, że dane wejściowe zawierają „Cenę” i „Status członkostwa”. Jeśli brakuje danych wejściowych, diagram jest niekompletny.
Krok 4: Sprawdź magazyny danych. Upewnij się, że każdy magazyn danych ma co najmniej jedną operację odczytu (przepływ wejściowy) i jedną operację zapisu (przepływ wyjściowy), chyba że jest to stała rejestracja aktualizowana rzadko. Magazyn danych, który tylko odbiera dane, ale nigdy ich nie wydaje, może wskazywać na błąd „zatoki”, podczas gdy magazyn, który tylko wydaje dane, może wskazywać na błąd „źródła”.
Krok 5: Sprawdź zrównoważenie. Jeśli przeglądasz diagram poziomu 1, sprawdź go w stosunku do rodzica – diagramu poziomu 0. Czy dane wejściowe i wyjściowe się zgadzają? Jeśli proces rodzica mówi „Odbierz zamówienie”, proces potomny również musi odbierać dane „Zamówienie”. Jeśli proces potomny odbiera „Płatność”, diagram jest nierealny.
Śledząc tę sekwencję, przechodzisz od widoku makro do mikro, zapewniając kompleksowe zrozumienie architektury systemu.
Nawet doświadczeni inżynierowie popełniają błędy przy tworzeniu diagramów przepływu danych. Jako czytelnik, rozpoznawanie tych anomalii może zaoszczędzić Ci znacznie więcej czasu podczas rozwoju. Rozpoznawanie tych błędów pomaga zadawać odpowiednie pytania architektom systemu.
Czarna dziura występuje, gdy proces ma dane wejściowe, ale nie ma danych wyjściowych. Dane wchodzą do procesu i znikają. W rzeczywistym systemie oznacza to utratę danych. Na przykład, jeśli „Przetwarzanie użytkownika” odbiera „Formularz logowania”, ale nie generuje żadnych danych wyjściowych do bazy danych ani do ekranu potwierdzenia, dane nie mają gdzie iść. Oznacza to brakujące wymaganie lub uszkodzony przepływ logiczny.
Cud to przeciwieństwo czarnej dziury. Jest to proces, który generuje dane wyjściowe bez odbierania żadnych danych wejściowych. Jak system może wygenerować „Raport sprzedaży” bez odczytania „Danych sprzedaży”? Oznacza to, że dane są generowane z niczego, co jest niemożliwe w deterministycznym systemie. Brakujące dane wejściowe muszą zostać zidentyfikowane i połączone z magazynem danych lub zewnętrznym źródłem.
Ten błąd występuje, gdy dane wejściowe i wyjściowe procesu nie pasują logicznie, nawet jeśli oba istnieją. Na przykład, jeśli proces nazywa się „Oblicz podatek”, ale dane wejściowe to „Adres użytkownika”, a dane wyjściowe to „Całkowita cena”, przemiana jest niepełna. Brakuje stawki podatku. Często wskazuje to na brakujący magazyn danych lub niepołączony przepływ.
W czystych diagramach przepływu danych strzałki nie powinny się przecinać bez połączenia. Jeśli dwa przepływy danych się przecinają, może być niejasne, czy oddziałują na siebie, czy po prostu mijają się. Choć w złożonych diagramach część przecięć jest nieunikniona, to jest objawem złego układu. W dobrze zaprojektowanym diagramie przepływy powinny być poprawnie skierowane, aby uniknąć nieporozumień.
Każda strzałka musi mieć etykietę. Strzałka bez nazwy oznacza, że konkretna zawartość danych jest nieznana. Jeśli widzisz strzałkę łączącą magazyn danych z procesem, musisz wiedzieć, jakie dane są pobierane. „Dane” to nie wystarczająco dokładna etykieta. Powinna to być np. „Lista klientów” lub „Aktywne tokeny sesji”. Niejasne etykiety są głównym źródłem błędów implementacji.
Jednym z najczęściej powodujących zamieszanie punktów dla nowych inżynierów jest różnica między diagramem przepływu danych a schematem blokowym. Choć oba wykorzystują kształty i strzałki, ich znaczenie jest fundamentalnie różne.
Skupienie: Schemat blokowy skupia się na przepływie sterowania. Pokazuje kolejność operacji, punkty decyzyjne (jeśli/else) oraz pętle. Odpowiada na pytanie „Co się stanie dalej?” Diagram przepływu danych skupia się na przepływie danych. Pokazuje ruch informacji. Odpowiada na pytanie „Dokąd idą dane?”
Logika vs. Dane: W schemacie blokowym widzisz diamenty decyzyjne. W standardowym diagramie przepływu danych nie ma ich. Diagram przepływu danych zakłada, że proces się odbywa; nie modeluje logiki rozgałęzienia tego procesu.
Czas: Schematy blokowe często sugerują sekwencję czasową. Diagramy przepływu danych są zazwyczaj bezczasowe. Diagram przepływu danych nie pokazuje, który proces dzieje się pierwszy, chyba że wynika to z zależności danych.
Przechowywanie: Diagramy przepływu zwykle nie pokazują jawnie przechowywania danych. Diagramy przepływu danych (DFD) jawnie modelują magazyny danych jako główny element.
Zrozumienie tej różnicy zapobiega próbom znalezienia logiki sterowania tam, gdzie jej nie ma. Jeśli szukasz logiki „jeśli to, to tam”, zajrzyj do diagramu przepływu lub pseudokodu. Jeśli szukasz, gdzie aktualizowany jest bazę danych, zajrzyj do DFD.
Czytanie DFD nie jest tylko ćwiczeniem akademickim; jest codziennym wymaganiem dla inżynierów oprogramowania. Oto jak ta umiejętność przekłada się na rzeczywiste scenariusze.
1. Wprowadzanie do zespołu i przegląd kodu: Gdy dołączasz do nowego zespołu, dokumentacja architektury często zawiera DFD. Przeczytanie ich pozwala zrozumieć zależności danych przed dotknięciem kodu. Podczas przeglądania kodu możesz sprawdzić, czy implementacja odpowiada diagramowi. Jeśli diagram pokazuje dane idące do pamięci podręcznej, a kod zapisuje tylko do bazy danych, zidentyfikowałeś rozbieżność.
2. Debugowanie i rozwiązywanie problemów: Gdy funkcja nie działa, DFD pomaga śledzić ścieżkę danych. Jeśli użytkownik zgłasza, że jego profil nie jest aktualizowany, możesz śledzić przepływ „Aktualizacja profilu” na DFD. Możesz sprawdzić, które procesy są zaangażowane i do jakich magazynów danych ma się dostęp. To znacznie ogranicza przestrzeń poszukiwań w porównaniu do poszukiwania w kodzie bez kierunku.
3. Zbieranie wymagań: Pracując z menedżerami produktu, często musisz wizualizować wymagania. Jeśli rozumiesz DFD, możesz pomóc w dopracowaniu wymagań. Możesz zauważyć brakujące przepływy danych lub niemożliwe przekształcenia jeszcze przed rozpoczęciem rozwoju. Ta podejście proaktywne zmniejsza dług techniczny.
4. Integracja systemów: W architekturach mikroserwisów DFD są niezbędne do definiowania kontraktów interfejsów API. Możesz zmapować przepływy danych między usługami, aby upewnić się, że dane wyjściowe usługi A są zgodne z danymi wejściowymi usługi B. To zapobiega awariom integracji spowodowanym niezgodnymi formatami danych.
Aby zapewnić, że diagramy, które czytasz, pozostają użyteczne przez dłuższy czas, rozważ następujące praktyki. Diagram, który jest przestarzały, jest gorszy niż żaden diagram.
Zachowaj poziom abstrakcji:Nie zatruwaj DFD każdym nazwą zmiennej. Przytrzymaj się logicznych jednostek danych. „Wejście użytkownika” jest lepsze niż „Wartość pola Nazwisko”.
Używaj spójnej nomenklatury: Upewnij się, że „Klient” w jednym diagramie nazywa się „Klient” we wszystkich powiązanych diagramach. Unikaj synonimów takich jak „Klient” lub „Użytkownik”, chyba że odnoszą się do różnych jednostek.
Aktualizuj podczas zmian: Jeśli kod znacznie się zmienia, DFD powinien zostać zaktualizowany. Diagram zarządzany w systemie kontroli wersji może służyć jako historia ewolucji systemu.
Ogranicz złożoność: Jeśli pojedynczy diagram staje się zbyt zatłoczony, nadszedł czas, aby go rozłożyć na diagramy o niższym poziomie szczegółowości. Dobrym punktem odniesienia jest to, że diagram poziomu 0 powinien mieć nie więcej niż 7 do 10 głównych procesów.
Opanowanie interpretacji diagramów przepływu danych wymaga cierpliwości i praktyki. Obejmuje to przekroczenie symboli, aby zrozumieć relacje logiczne między nimi. Skupiając się na przepływie danych, identyfikując anomalie i rozumiejąc hierarchię, wyposażasz się w potężne narzędzie do analizy systemu.
W miarę postępu w karierze inżynierskiej zetknie się z różnymi technikami modelowania. DFD pozostaje podstawową umiejętnością. Naucza Cię myśleć o systemach pod kątem danych wejściowych, przekształceń i danych wyjściowych. Ta mentalność jest przenoszona na projektowanie baz danych, architekturę interfejsów API i planowanie infrastruktury chmurowej. Kontynuuj ćwiczenie czytania tych diagramów w projektach open-source lub dokumentacji wewnętrznej. Im więcej śledzisz przepływy, tym bardziej intuicyjna stanie się architektura systemu.