 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Diagramy przepływu danych (DFD) pełnią rolę wizualnego projektu systemów informacyjnych. W przeciwieństwie do kodu, który opisuje logikę poprzez składnię, DFD opisuje logikę poprzez ruch. Mapuje sposób, w jaki dane wchodzą do systemu, przekształcają się w różnych procesach i wychodzą jako dane wyjściowe lub są przechowywane. Niniejszy przewodnik zapewnia kompleksowy przegląd tworzenia tych diagramów bez użycia narzędzi własnościowych, skupiając się na podstawowych zasadach analizy systemów.
Niezależnie od tego, czy definiujesz wymagania dla nowej aplikacji, czy audytujesz istniejący system dziedziczny, zrozumienie przepływu danych jest kluczowe. Dobrze zbudowany DFD eliminuje niejasności. Zmusza zaangażowane strony do zgody na źródła informacji oraz miejsca ich zakończenia. Niniejszy dokument bada anatomię DFD, zasady ich tworzenia oraz metodyki rozkładania skomplikowanych systemów na zarządzalne widoki.
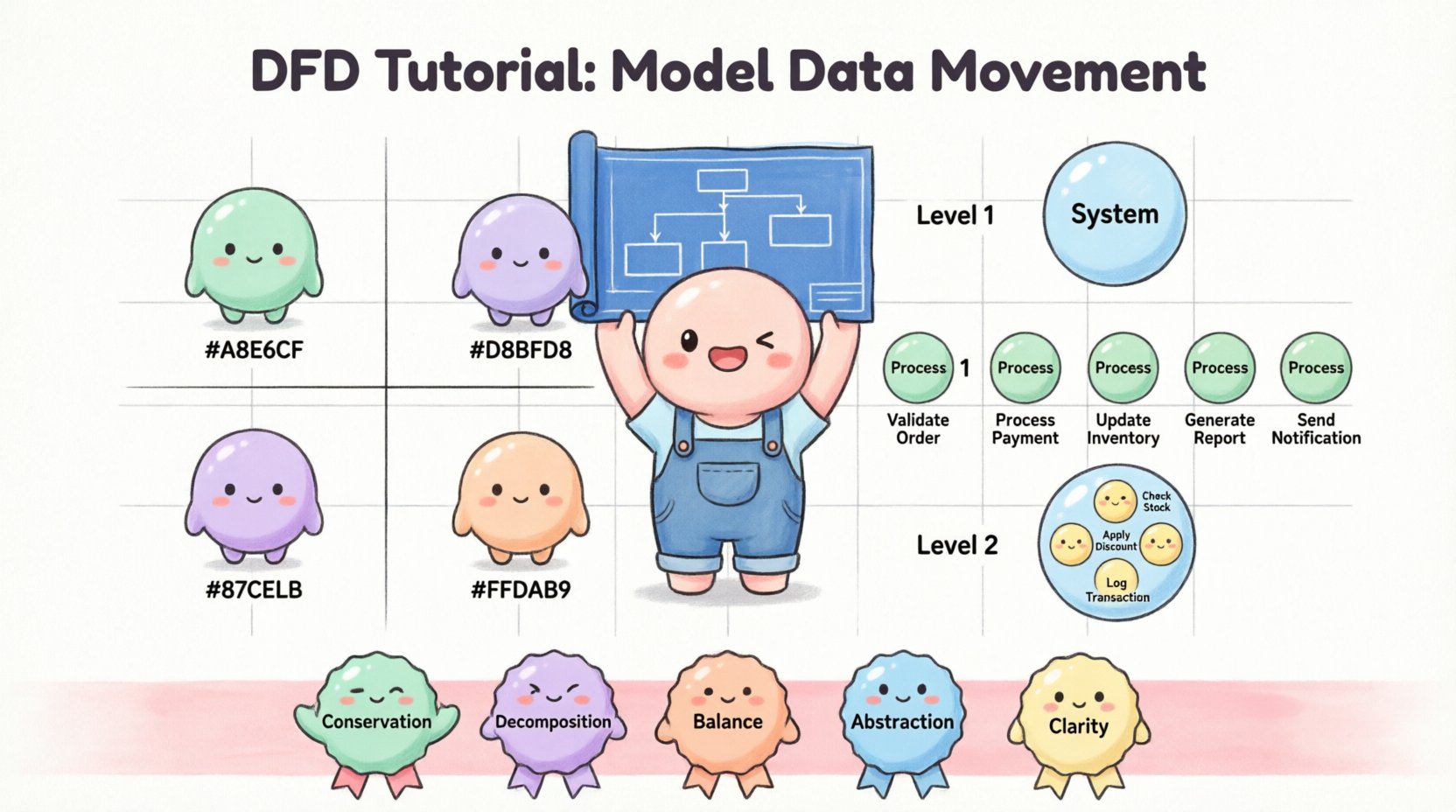
Diagram przepływu danych nie jest diagramem przepływu sterowania. Nie pokazuje czasu ani kolejności zdarzeń. Zamiast tego skupia się na samej dane. Wyobraź sobie go jako mapę systemu rzecznych. Nie interesuje Cię prędkość wody ani pogoda, ale dopływy, zbiorniki i ujścia rzek.
Podczas modelowania systemu biznesowego DFD odpowiada na trzy podstawowe pytania:
Odpowiadając na te pytania, tworzysz reprezentację logiczną biznesu. Ta reprezentacja pozostaje ważna niezależnie od stosowanej technologii do budowy systemu. Jest to język abstrakcji, który łączy luki między potrzebami biznesowymi a implementacją techniczną.
Każdy diagram przepływu danych budowany jest przy użyciu czterech określonych symboli. Choć notacje nieco się różnią między metodologiami, podstawowe koncepcje pozostają spójne. Opanowanie tych elementów jest podstawą dokładnego modelowania.
Jednostki zewnętrzne reprezentują źródła lub miejsca docelowe danych znajdujące się poza granicami modelowanego systemu. Często są to osoby, dział, lub inne systemy, które współdziałają z głównym systemem.
W diagramach są one zwykle przedstawiane jako kwadraty lub prostokąty. Zawsze muszą być połączone z procesem; dane nie mogą po prostu pojawiać się znikąd ani zniknąć bez powodu.
Proces przekształca dane wejściowe w dane wyjściowe. Jest silnikiem systemu. W DFD procesy są zwykle przedstawiane jako okręgi lub prostokąty z zaokrąglonymi rogami. Nazwa procesu powinna zawsze być frazą rzeczownikowo-przysłówkową, aby wyrażać działanie.
Każdy proces musi mieć co najmniej jedno wejście i jedno wyjście. Jeśli proces ma wejścia, ale brak wyjść, to jest „czarna dziura”. Jeśli ma wyjścia, ale brak wejść, to jest „czarodziejstwo”. Oba przypadki oznaczają błędy modelowania.
Magazyny danych reprezentują miejsca, gdzie informacje są przechowywane do późniejszego pobrania. Mogą to być baza danych, system plików, fizyczna szafka archiwalna lub tymczasowy bufor. W przeciwieństwie do procesów, magazyny danych nie zmieniają danych – tylko je przechowują.
Zazwyczaj rysuje się je jako otwarte prostokąty lub dwie równoległe linie. Łączą się z procesami za pomocą przepływów danych, co wskazuje na operacje odczytu lub zapisu.
Przepływy danych to strzałki łączące komponenty. Odpowiadają za przemieszczanie się danych między jednostkami, procesami i magazynami. Wskaźnik strzałki wskazuje kierunek przemieszczania.
Złożone systemy nie mogą być narysowane na jednej stronie. Aby zarządzać złożonością, DFD są rozkładane na różne poziomy szczegółowości. Ten podejście hierarchiczne pozwala analitykom przybliżać i oddalać się od architektury systemu.
Diagram kontekstowy to najwyższy poziom widoku. Pokazuje cały system jako pojedynczą kulkę procesu. Ilustruje sposób, w jaki system oddziałuje z jednostkami zewnętrznymi.
Poziom 1 rozszerza pojedynczy proces z diagramu kontekstowego na główne podprocesy. Ten poziom identyfikuje główne obszary funkcjonalne systemu.
Poziom 2 skupia się na określonych procesach z poziomu 1. Rozbija złożone funkcje na mniejsze, wykonywalne kroki. Ten poziom to często miejsce, gdzie deweloperzy poszukują określonych wymagań logicznych.
W analizie systemów stosuje się dwa dominujące style notacji. Choć logika pozostaje ta sama, różni się ich wizualna reprezentacja. Wybór odpowiedniego stylu zależy od znajomości zespołu oraz standardów organizacji.
| Cecha | Yourdon & DeMarco | Gane & Sarson |
|---|---|---|
| Kształt procesu | Okrągły prostokąt | Okrągły prostokąt |
| Kształt encji | Kwadrat | Kwadrat |
| Kształt magazynu danych | Otwarty prostokąt | Otwarty prostokąt z grubszym górnym/dolnym bokiem |
| Kształt przepływu danych | Zagięty strzałka | Prosta strzałka |
| Pozycja etykiety przepływu | Poniżej linii | Powyżej lub poniżej |
Wybór między notacją Gane & Sarson a Yourdon & DeMarco jest przede wszystkim kwestią estetyczną. Jednak spójność jest kluczowa. Mieszanie notacji w jednym dokumencie powoduje zamieszanie i zmniejsza przejrzystość dokumentacji.
Tworzenie DFD to proces systematyczny. Wymaga on iteracji i weryfikacji. Postępuj zgodnie z tymi krokami, aby zapewnić dokładność i kompletność.
Zanim narysujesz jedną linię, zidentyfikuj, co znajduje się wewnątrz systemu, a co poza nim. Często jest to określone zakresem projektu. Wszystko, co dostarcza dane wejściowe lub odbiera dane wyjściowe, stanowi warunek graniczny.
Wypisz wszystkie źródła i miejsca docelowe. Przeprowadź rozmowy z zaangażowanymi stronami, aby ustalić, kto współdziała z systemem. Nie zapomnij o systemach automatycznych – są one jednostkami tak samo jak ludzie.
Zacznij od dużego obrazu. Narysuj system jako jedną kropkę. Połącz jednostki zewnętrzne strzałkami. Oznacz strzałki danymi wymienianymi między nimi. Służy to jako punkt odniesienia dla wszystkich kolejnych diagramów.
Rozszerz pojedynczą kropkę do poziomu 1. Zidentyfikuj główne funkcje. Podziel system na logiczne fragmenty. Upewnij się, że dane wejściowe i wyjściowe diagramu poziomu 0 odpowiadają sumie danych wejściowych i wyjściowych procesów poziomu 1.
Zidentyfikuj, gdzie dane muszą być trwale przechowywane. Jeśli proces musi pamiętać informacje z poprzedniej transakcji, wymagany jest magazyn danych. Połącz te magazyny z odpowiednimi procesami.
To kluczowe zasada. Dane wejściowe i wyjściowe procesu nadrzędnego muszą być równe sumie danych wejściowych i wyjściowych jego dzieci. Jeśli diagram kontekstowy pokazuje „Zamówienie otrzymane”, diagram poziomu 1 również musi pokazywać „Zamówienie otrzymane” wchodzące do systemu w jakimś miejscu.
Przejrzyj diagram krok po kroku. Śledź przepływ danych od początku do końca. Czy przepływ jest logiczny? Czy są jakieś procesy bez rodzica? Czy wszystkie przepływy danych są oznaczone?
Nawet doświadczeni analitycy popełniają błędy podczas tworzenia tych modeli. Znajomość typowych błędów może zaoszczędzić znaczną ilość czasu w fazie przeglądu.
Ważne jest rozróżnienie między widokiem logicznym systemu a widokiem fizycznym. Diagram przepływu danych (DFD) w wersji logicznej opisujecoco system robi. Diagram przepływu danych (DFD) w wersji fizycznej opisujejak jak system to robi.
Zacznij od modelu logicznego. Nie wprowadzaj zbyt wcześnie ograniczeń technicznych. Wprowadzanie technologii zbyt wcześnie może ograniczyć opcje projektowania i wywołać uprzedzenie w analizie. Po zatwierdzeniu modelu logicznego można wyprowadzić model fizyczny, aby kierować rozwojem.
Aby zapewnić, że schematy przepływu danych pozostają użyteczne przez cały cykl projektu, przestrzegaj tych standardów.
Dlaczego inwestować czas w rysowanie tych schematów? Wymagania tekstowe są podatne na nieporozumienia. Zdanie opisujące proces może być rozumiane na wiele sposobów. Schemat jest wizualny i przestrzenny.
Gdy stakeholder zobaczy schemat, może natychmiast zauważyć brakujące przepływy. Może zobaczyć, gdzie dane są powielone. Może zrozumieć złożoność systemu na pierwszy rzut oka. Ta wizualna potwierdzenie zmniejsza ryzyko budowania nieprawidłowego systemu.
Dodatkowo, schematy przepływu danych działają jako narzędzie komunikacji między zespołami biznesowymi i technicznymi. Analitycy biznesowi używają ich do zrozumienia wymagań. Deweloperzy używają ich do zrozumienia architektury. Przez utrzymywanie wspólnej artefaktu organizacja zmniejsza izolację i poprawia zgodność.
Wprowadzenie metodyki schematów przepływu danych wymaga dyscypliny. Narysowanie linii nie wystarczy; musisz zrozumieć zasady zachowania danych i ich dekompozycji. W miarę ćwiczeń odkryjesz, że schematy stają się naturalnym rozszerzeniem Twojego procesu myślowego.
Zacznij od małego. Zamodeluj prostą transakcję. Następnie rozszerz do działu. Na końcu zamodeluj całą firmę. Z każdym poziomem Twoje zrozumienie systemu się pogłębia. Celem nie jest stworzenie idealnego rysunku, ale stworzenie jasnego mapowania przepływu informacji, które kieruje budową solidnych rozwiązań oprogramowania.
Pamiętaj, że schemat to narzędzie myślenia, a nie tylko dokument do archiwizacji. Używaj go do wyzwania założeń, identyfikacji luk i weryfikacji logiki. W świecie projektowania systemów jasność pozostaje najwyższą formą precyzji.
Przestrzegając tych zasad, zapewnicasz, że przepływ danych w dowolnym systemie biznesowym jest dokładnie zapisany i zrozumiały dla wszystkich zaangażowanych w cykl życia projektu.