 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Rozwój agilny często kojarzy się z szybkością, elastycznością i minimalną dokumentacją. Schematy przepływu danych (DFD), z drugiej strony, to klasyczna technika modelowania systemów, która historycznie rozkwitała w strukturalnych, planowanych środowiskach. Na pierwszy rzut oka te dwa podejścia mogą się wydawać sprzeczne. Jednak poprawnie zaimplementowane DFD działają jako kluczowy most między abstrakcyjnymi wymaganiami a konkretną architekturą systemu w ramach podejścia agilnego. Ten przewodnik bada, jak wizualizacja przepływu danych wspiera rozwój iteracyjny bez poświęcania przejrzystości czy kontroli.
Zrozumienie, skąd pochodzi dana część informacji, jak się przekształca i gdzie się ustala, jest kluczowe do budowania odpornego oprogramowania. Niezależnie od tego, czy projektujesz architekturę mikroserwisów, czy przekształcasz aplikację monolityczną, zasady przepływu danych pozostają niezmienne. Przeanalizujemy praktyczne zastosowania, strategie integracji oraz konkretną wartość, jaką DFD przynoszą w cyklu sprintu.
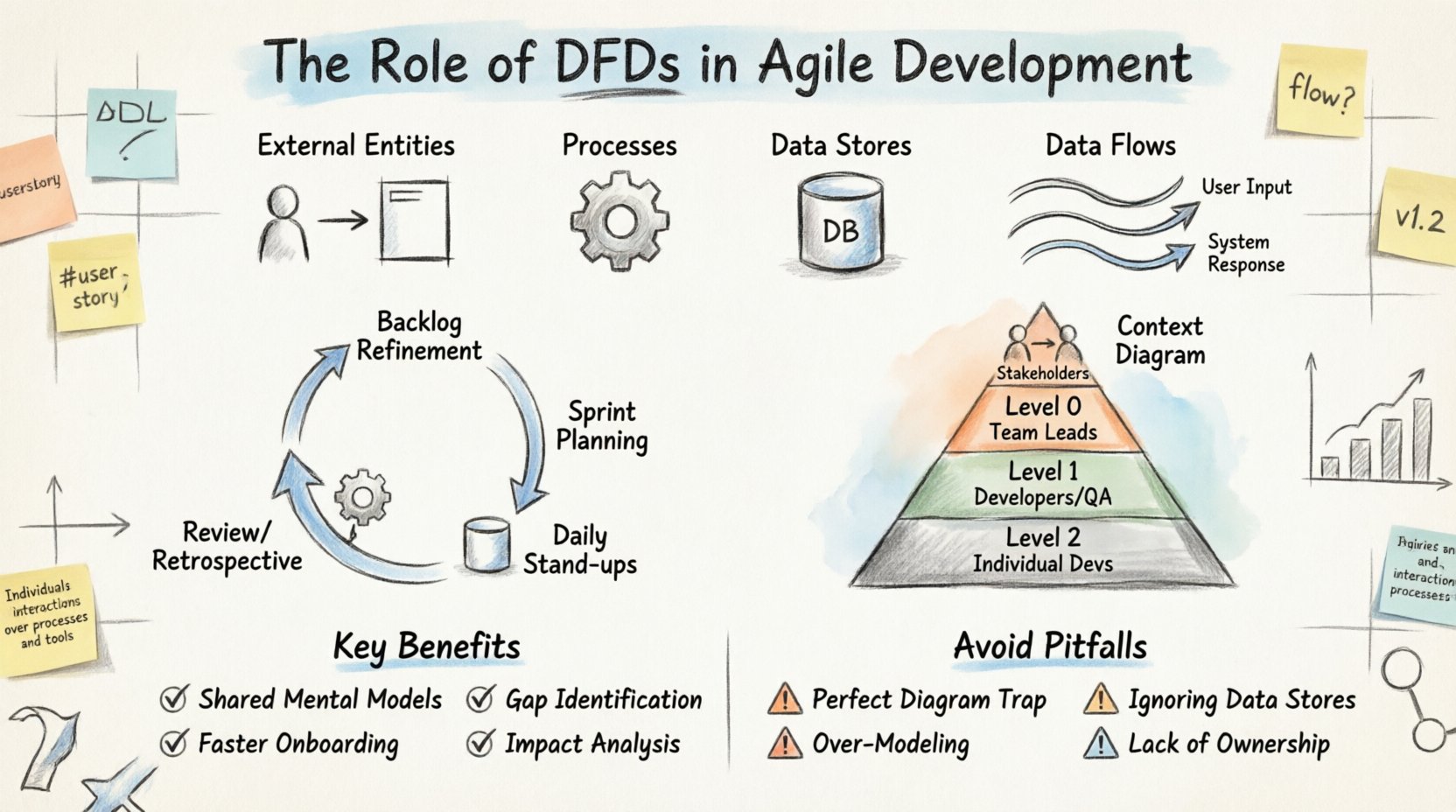
Schemat przepływu danych to graficzne przedstawienie przepływu danych przez system informacyjny. W przeciwieństwie do schematu blokowego, który przedstawia logikę sterowania i punkty decyzyjne, DFD skupia się na danych. Ilustruje ruch danych od źródła zewnętrznego, przez procesy, do magazynów danych, a na końcu do zewnętrznego punktu docelowego.
W środowisku agilnym te schematy nie są statycznymi projektami. Są żyjącymi artefaktami, które ewoluują razem z produktem. Podstawowe elementy DFD to:
Gdy programiści i właściciele produktu patrzą na DFD, widzą „co” systemu, a nie „jak”. Ta różnica jest kluczowa. Pozwala zespołowi zweryfikować, czy wszystkie niezbędne dane zostały uwzględnione, zanim napiszą pierwszy wiersz kodu.
Powszechną niechęcią wśród zespołów agilnych jest postrzegana obciążenie związane z tworzeniem schematów. Manifest Agilny ceni działające oprogramowanie nad kompleksową dokumentacją. Jednak oznacza to nie to, że dokumentacja jest bezwartościowa. Oznacza to, że dokumentacja powinna być użyteczna i nie tworzyć niepotrzebnych barier.
DFD mogą stać się węzłem zatorowym, jeśli traktowane są jako mechanizm kontroli dostępu. Zamiast tego powinny być traktowane jako narzędzie komunikacji. Oto główne argumenty na rzecz utrzymywania DFD w procesie agilnym:
Cel nie polega na tworzeniu doskonałych schematów, które zajmują tygodnie rysowania. Cel polega na zapewnieniu wystarczającej przejrzystości, by zmniejszyć ponowne prace. Szybki szkic na tablicy, który później zostanie dopracowany, często ma większą wartość niż wykończony dokument, który nigdy nie zostanie uaktualniony.
Integracja modelowania systemu w sprintie agilnym wymaga dyscypliny. Schematy muszą być tworzone w odpowiednim czasie i z odpowiednim poziomem szczegółowości. Poniżej znajduje się rozkład, jak DFD pasują do standardowych ceremonii agilnych.
W trakcie dopracowywania zespół dzieli epiki na historie. To idealny moment na stworzenie diagramu przepływu danych na wysokim poziomie szczegółowości. Pomaga zespołowi zrozumieć zakres epiki pod kątem przepływu danych. Jeśli epika obejmuje przemieszczanie danych klientów z systemu dziedziczonego do nowego pulpitu, diagram wyróżnia kroki przekształcenia wymagane.
Gdy backlog sprintu zostanie ustalony, zespół może przejść do szczegółów. Dla złożonych historii może zostać stworzony diagram przepływu danych poziomu 1 lub 2. Zapewnia to, że programiści przypisani do historii rozumieją zależności danych. Zapobiega sytuacji, w której programista stworzy punkt końcowy oczekujący na dane w formacie, którego proces poniżej nie może obsłużyć.
Choć nie każdego dnia wymagane jest rysowanie diagramów, blokady często są związane z integralnością danych. Jeśli programista jest zatrzymany, ponieważ magazyn danych nie ma indeksu lub przepływ jest zablokowany z powodu problemów z uprawnieniami, odwoływanie się do diagramu przepływu danych pomaga wyjaśnić stan oczekiwany w stosunku do rzeczywistego stanu.
Po sprintie zespół powinien sprawdzić, czy diagramy przepływu danych nadal odpowiadają zaimplementowanemu kodowi. Jeśli architektura się zmieniła, diagram powinien zostać uaktualniony. Ta praktyka utrzymuje dokumentację aktualną i wiarygodną dla przyszłych sprintów.
Nie każda funkcja wymaga szczegółowego analizowania każdej transakcji danych. Różne poziomy diagramów przepływu danych spełniają różne role w cyklu rozwoju oprogramowania. Używanie odpowiedniego poziomu zapobiega zarówno niedostatecznej specyfikacji, jak i nadmiernemu projektowaniu.
| Poziom | Skupienie | Kiedy używać | Typowa grupa docelowa |
|---|---|---|---|
| Diagram kontekstowy | Granica systemu i interakcje zewnętrzne. | Wprowadzenie projektu lub planowanie na wysokim poziomie. | Zainteresowane strony, architekci |
| Poziom 0 (wysoki poziom szczegółowości) | Główne procesy wewnątrz systemu. | Faza projektowania systemu lub planowanie głównych funkcji. | Kierownicy zespołów, starsi programiści |
| Poziom 1 (średni poziom szczegółowości) | Rozbicie głównych procesów. | Planowanie sprintu dla złożonych funkcji. | Programiści, QA |
| Poziom 2 (szczegółowy) | Konkretne przekształcenia danych. | Faza kodowania dla złożonej logiki lub punktów integracji. | Poszczególni programiści |
Dla zespołów Agile jest typowe rozpoczęcie od diagramu kontekstowego, a dopiero wtedy przejście do poziomu 1 lub 2, gdy konkretna funkcja tego wymaga. Taki podejście modelowania w odpowiednim momencie zapewnia, że nie tracona jest energia na szczegóły, które mogą się zmienić w kolejnej iteracji.
Jednym z najbardziej praktycznych zastosowań DFD w Agile jest ich bezpośrednie mapowanie na historie użytkownika. Historie użytkownika opisują funkcjonalność z perspektywy użytkownika (np. „Jako użytkownik chcę zaktualizować mój profil”). DFD opisują mechanizmy danych stojące za tą funkcjonalnością.
Rozważ historię dotyczącą „Przetwarzania płatności”. Historia użytkownika skupia się na stanie sukcesu. DFD skupia się na trasie danych pieniężnych. Łącząc je, zespół zapewnia, że wymagania funkcjonalne są wspierane rzeczywistością techniczną.
Oto jak działa mapowanie:
To mapowanie pomaga w tworzeniu kryteriów akceptacji. Jeśli DFD pokazuje przepływ do magazynu „Dziennik transakcji”, kryteria akceptacji muszą zawierać weryfikację pomyślnego utworzenia wpisu w dzienniku. Tworzy to łącze śledzenia między diagramem a przypadkami testowymi.
Nowoczesne aplikacje często mają do czynienia ze złożonymi strukturami danych, zagnieżdżonymi obiektami i przetwarzaniem asynchronicznym. Tradycyjne DFD mają trudności z wizualizacją kolejek asynchronicznych lub architektur opartych na zdarzeniach bez modyfikacji. W kontekście Agile ważne jest dostosowanie notacji do rzeczywistości systemu.
W systemach opartych na zdarzeniach przepływy danych mogą być traktowane jako zdarzenia uruchamiające procesy. Przy użyciu kolejek magazyn danych reprezentuje broker komunikatów. Przy użyciu interfejsów API przepływ danych reprezentuje cykl żądanie/odpowiedź. Zasadniczy zasadę pozostaje ta sama: śledź informacje.
Przy pracy z mikroserwisami DFD można rozszerzyć, aby pokazać komunikację między serwisami. Jest to kluczowe do zrozumienia opóźnień i punktów awarii. Jeśli Serwis A wysyła dane do Serwisu B, DFD jasno pokazuje tę zależność. W architekturze monolitycznej ta zależność może być niewidoczna, dopóki nie spowoduje problemu wydajności.
DFD wyróżniają się w ułatwianiu rozmów. Są wystarczająco niezależne od języka, aby analitycy biznesowi i programiści mogli dyskutować o tym samym elemencie bez nieporozumień. Jednak wymaga to, aby diagram był dostępny i czytelny.
Najlepsze praktyki wspólnej pracy nad diagramami obejmują:
Gdy diagram jest przechowywany w repozytorium, staje się częścią potoku ciągłej integracji. Sprawdzenia automatyczne mogą potwierdzić, że diagram odpowiada skonfigurowanej wersji wdrożonej w niektórych kontekstach, choć jest to zaawansowane użycie.
Nawet mając najlepsze intencje, zespoły mogą niepoprawnie stosować schematy DFD. Wczesne rozpoznanie tych pułapek oszczędza czas i wysiłek.
Czasem zespoły poświęcają zbyt dużo czasu na to, by schemat wyglądał estetycznie. W podejściu Agile szkic poglądowy jest lepszy niż doskonały dokument. Skup się na przejrzystości, a nie estetyce. Jeśli programista potrafi zrozumieć przebieg na podstawie szkicu, to wystarczy.
Łatwo skupić się na procesach i zapomnieć, gdzie znajdują się dane. Jeśli proces zapisuje dane do magazynu, który nie jest czytany przez żaden inny proces, jest to bezużyteczna ciężarówka. Jeśli proces odczytuje dane z magazynu, który nigdy nie jest aktualizowany, dane są przestarzałe. Regularne przeglądy magazynów danych zapewniają, że schemat pozostaje dokładny.
Nie każda zmienna potrzebuje linii na schemacie. Skup się na przepływach danych o wysokiej wartości. Jeśli system ma ustawienie, które rzadko się zmienia, może nie wymagać szczegółowej linii przepływu. Nadmierna modelowanie tworzy szum i utrudnia utrzymanie schematu.
Kto jest odpowiedzialny za aktualizację schematu DFD w przypadku zmian kodu? Jeśli nikt nie ponosi odpowiedzialności, schemat szybko się wygrywa. Przydziel odpowiedzialność za schemat liderowi zespołu lub architektowi dla danego obszaru.
Jak możesz wiedzieć, czy stosowanie schematów DFD naprawdę pomaga zespołowi Agile? Szukaj tych wskaźników w czasie:
Jeśli te wskaźniki się poprawią, inwestycja w modelowanie jest uzasadniona. Jeśli nie, zespół powinien ponownie ocenić szczegółowość schematów lub częstotliwość ich aktualizacji.
W wielu branżach przetwarzanie danych jest regulowane. Dane finansowe, rekordy medyczne i informacje osobiste mają ścisłe wymagania dotyczące przechowywania i przemieszczania. Schematy DFD są szczególnie przydatne w tym zakresie podczas audytów zgodności.
Schemat DFD jasno pokazuje, gdzie dane poufne wchodzą do systemu, jak są szyfrowane, gdzie są przechowywane i gdzie opuszczają system. Ta widoczność jest niezbędna do:
Podczas sprintu Agile, który obejmuje poufne dane, schemat DFD powinien zostać przejrzany przez zespół bezpieczeństwa przed scaleniem kodu. Pozwala to zintegrować bezpieczeństwo z cyklem rozwoju bez spowolnienia procesu.
Wiele zespołów Agile pracuje nad modernizacją systemów dziedzicznych. Często polega to na otoczeniu starych funkcjonalności nowymi interfejsami API lub migracji danych na nowe platformy. Schematy DFD są nieocenione w tym kontekście, ponieważ dokumentują „czarną skrzynkę” kodu dziedzicznego.
Tworząc schemat DFD systemu dziedzicznego, zespół może zidentyfikować punkty wejścia i wyjścia dla migracji danych. Pomaga to w projektowaniu mostu między starym a nowym systemem. Zapewnia, że podczas przejścia nie straci się żadnych danych i że nowy system poprawnie obsługuje dane.
Zintegrowanie schematów przepływu danych w rozwój Agile nie oznacza powrotu do obszernych dokumentów. Chodzi o utrzymanie jasnego zrozumienia architektury systemu, jednocześnie przyjmując zmiany iteracyjne. Gdy są używane jako żywy, rozwijający się narządzie, a nie statyczny wymóg, schematy przepływu danych poprawiają komunikację, zmniejszają ryzyko i poprawiają jakość ostatecznie dostarczanego oprogramowania.
Zespoły, które przyjmują tę praktykę, zauważają, że ich zadłużenie techniczne związane z zarządzaniem danymi maleje. Spędzają mniej czasu na debugowaniu problemów z danymi i więcej czasu na budowaniu funkcji. Kluczem jest równowaga. Twórz schematy, gdy przynoszą wartość. Aktualizuj je, gdy system się zmienia. I zawsze pamiętaj o celu końcowym: system, który działa poprawnie i efektywnie.