 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Analiza systemów od dawna opierała się na wizualnych przedstawieniach, aby przekazywać złożoną logikę. Diagram przepływu danych (DFD) nadal jest fundamentem tej praktyki. Jednak krajobraz architektury oprogramowania drastycznie się zmienił. Przeszliśmy od aplikacji monolitycznych do rozproszonych mikroserwisów, od baz danych lokalnych do magazynowania w chmurze, a także od żądań synchronicznych do asynchronicznych strumieni zdarzeń. Tradycyjny DFD, zaprojektowany dla prostszych, liniowych procesów, napotyka nowe wyzwania w tych środowiskach. Ten przewodnik bada, jak metoda ewoluuje, aby pozostać aktualna, zapewniając dokładne modelowanie bez utraty aktualności. 🛠️
Zanim przejdziemy do analizy ewolucji, konieczne jest ustalenie podstawy. Standardowy DFD wizualizuje przepływ informacji przez system. Skupia się na co co system robi, a nie jak to robi. Ta różnica oddziela modelowanie procesów od projektowania strukturalnego. Podstawowe składniki pozostają stałe przez pokolenia:
W tradycyjnym ujęciu te diagramy były hierarchiczne. Diagram kontekstowy zapewniał widok najwyższego poziomu (poziom 0), który następnie był rozkładany na szczegółowe diagramy poziomu 1 i 2. To działało dobrze, gdy system miał jasne początkowe i końcowe punkty, a dane przemieszczały się przewidywalnie od wejścia do wyjścia. Jednak nowoczesne systemy często nie mają jednego punktu wejścia ani jednoznacznego wyjścia. Dane wchodzą i wychodzą ciągle, często w czasie rzeczywistym. 🔄
Przejście od monolitów do systemów rozproszonych wprowadza trudności w modelowaniu statycznym. W aplikacji monolitycznej transakcja bazy danych może wyzwolić serię wywołań funkcji, które kończą się natychmiast. DFD mógł narysować prostą linię od bazy danych do procesu, a następnie do wyjścia. W środowisku mikroserwisów sytuacja jest znacznie bardziej złożona.
Nowoczesne systemy często opierają się na brokerach komunikatów i kolejkach. Żądanie jest odbierane, przechowywane w kolejce i przetwarzane później przez workera. Tradycyjne DFDy mają trudności z przedstawieniem czasu. Wskazują na natychmiastowy przepływ. Statyczna strzałka nie łatwo oddaje, że dane mogą długo czekać w buforze, zanim następny proces się uruchomi. To prowadzi do niepewności w analizie zachowania systemu.
Architektury chmurowe często wykorzystują bezstanowe kontenery, które uruchamiają się i zamykają. DFD zwykle sugeruje stały proces. Gdy proces jest chwilowy, diagram musi wyjaśnić, gdzie przechowywany jest stan (magazyn danych), a gdzie znajduje się logika (obliczenia). Jeśli diagram nie rozróżnia tych dwóch aspektów, programiści mogą błędnie założyć, że stan jest utrzymywany w samym procesie, co prowadzi do błędów.
Starsze modele często traktowały magazyny danych jako ogólne pudełka. Nowoczesna zgodność wymaga zrozumienia, gdzie dane znajdują się geograficznie i jak są szyfrowane. DFD musi teraz wskazywać suwerenność danych i poziomy bezpieczeństwa. Jeśli przepływ danych przekracza strefę bezpieczeństwa, diagram powinien odzwierciedlać tę granicę, a nie tylko połączenie logiczne.
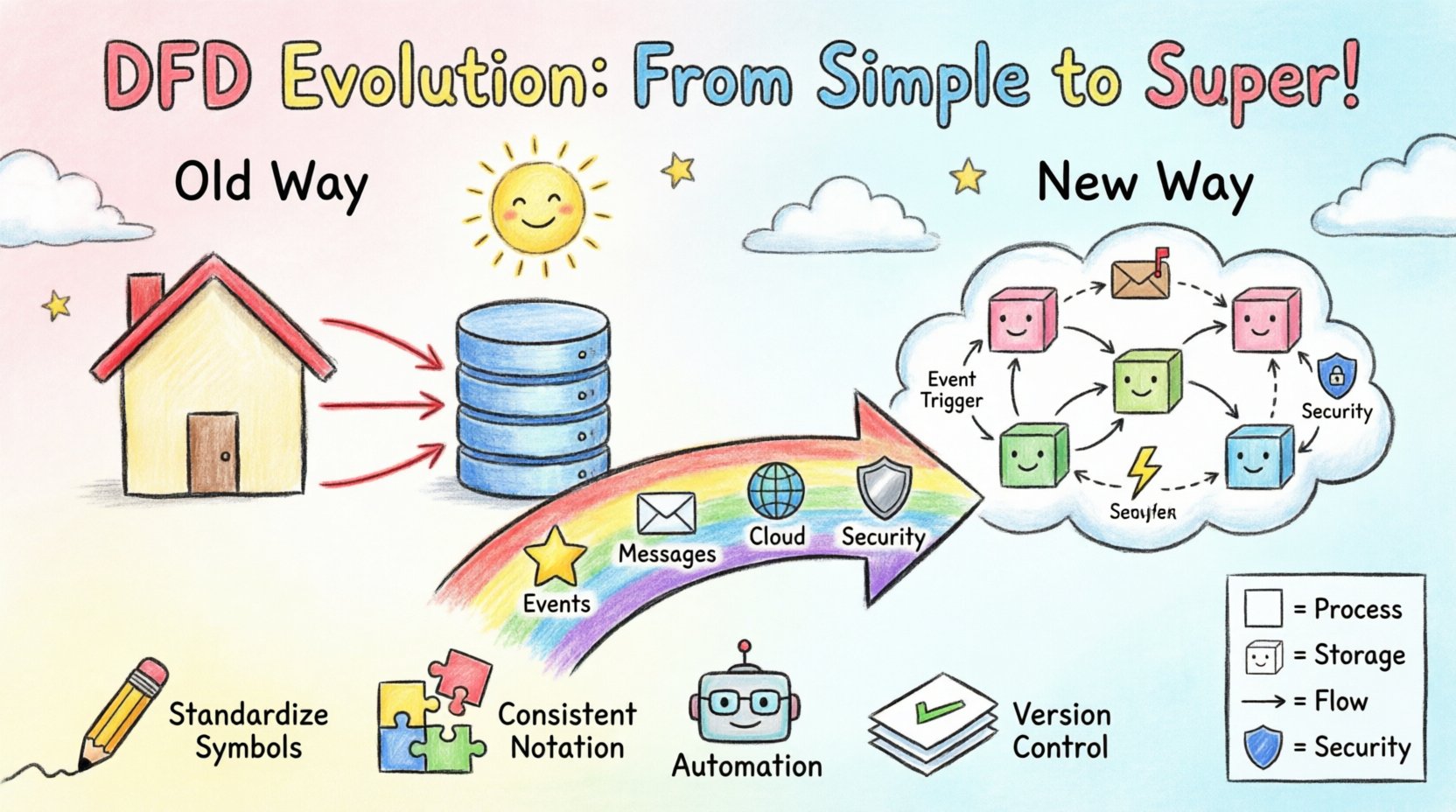
Aby wypełnić te luki, praktycy modyfikują standardową notację, aby dopasować ją do architektury opartej na zdarzeniach (EDA). Podstawowa koncepcja nadal polega na przepływie danych, ale zmieniają się wyzwalacze.
Ta adaptacja wymaga zmiany perspektywy. Diagram nie jest już tylko mapą systemu; jest mapą incydentów które napędzają system. Pomaga stakeholderom zrozumieć cykl życia danych od momentu tworzenia po ostateczne wykorzystanie, w tym przerwy pomiędzy nimi. 🕒
W miarę jak aplikacje przechodzą do chmury, diagram przepływu danych musi być zgodny z kontraktami interfejsów API i granicami usług. Diagram pełni rolę mostu między wymaganiami biznesowymi a realizacją techniczną.
Większość nowoczesnych systemów udostępnia bramę interfejsów API. W diagramie przepływu danych zastępuje ogólny „Zewnętrzny element”. Bramka staje się konkretnym procesem odpowiedzialnym za routowanie, uwierzytelnianie i ograniczanie szybkości. Diagram powinien pokazywać przekształcenie przychodzącego żądania w polecenie wewnętrzne. To jasno wyraża rozdzielenie odpowiedzialności.
W rozproszonych bazach danych dane są często podzielone na fragmenty. Tradycyjny symbol magazynu danych jest niewystarczający. Diagram powinien wskazywać, że proces może zapytać o wiele fragmentów, aby złożyć odpowiedź. To wizualizuje złożoność operacji odczytu w porównaniu do operacji zapisu. Na przykład zapis może trafić do jednego fragmentu, podczas gdy odczyt agreguje dane z trzech.
Usługi często nie znają adresu sieciowego innych usług w czasie projektowania. Odkrywają je w czasie działania. Diagram przepływu danych może to przedstawić za pomocą węzła „Rejestr usług”. Procesy łączą się z rejestrem, aby znaleźć bieżący punkt końcowy zależnej usługi. To dodaje warstwę widoczności infrastruktury do przepływu logicznego.
Zrozumienie różnic pomaga zespołom wybrać odpowiedni poziom abstrakcji. Poniższa tabela przedstawia kluczowe różnice w sposobie budowania i interpretowania DFD w dzisiejszych czasach w porównaniu do przeszłości.
| Cecha | Tradycyjny DFD | Nowoczesny DFD |
|---|---|---|
| Kierunek przepływu | Synchroniczny, natychmiastowy | Asynchroniczny, opóźniony lub partiami |
| Charakter procesu | Monolityczny, długotrwały | Usługa mikroserwisowa, chwilowa, bezstanowa |
| Przechowywanie | Centralna baza danych | Podzielona, rozproszona lub przechowywanie obiektów |
| Wyzwalacze | Nadejście danych wejściowych | Zdarzenia, komunikaty lub zaplanowane zadania |
| Granice | Obwiednia systemu | Strefy bezpieczeństwa i bramy interfejsów API |
| Zrównoleglenie | Często pomijane | Jawne modelowanie (kolejki, blokady) |
W miarę zwiększania się złożoności diagramów, czytelność staje się zagrożeniem. Poniższe praktyki zapewniają, że DFD pozostaje użytecznym narzędziem, a nie mylącym artefaktem.
Bezpieczeństwo nie jest już postrzegane jako dodatkowe. Musi być zintegrowane w fazie projektowania. DFD to doskonałe narzędzie do identyfikowania ryzyk bezpieczeństwa poprzez wizualizację miejsc, w których dane są narażone.
Każde przejście danych z jednego procesu do drugiego oznacza przekroczenie granicy zaufania. W nowoczesnym systemie może to być przejście od publicznego interfejsu API do wewnętrznego mikroserwisu. DFD powinien wyróżniać te granice. Jeśli przepływ danych przekracza granicę bez szyfrowania lub uwierzytelniania, diagram natychmiast ujawnia lukę bezpieczeństwa.
Nie wszystkie przepływy danych mają taką samą wagę. Czułe informacje, takie jak PII (osobiste dane identyfikacyjne), wymagają bardziej rygorystycznego traktowania. Diagram może wykorzystywać kody kolorów lub specjalne ikony do oznaczania wrażliwych przepływów. Zapewnia to, że podczas implementacji logiki programiści będą priorytetowo zabezpieczać szyfrowaniem i kontrolami dostępu te konkretne ścieżki.
Przepisy takie jak GDPR lub HIPAA określają, jak dane muszą być przechowywane i przemieszczane. Nowoczesny DFD może mapować przepływy danych na wymagania zgodności. Na przykład magazyn danych może być oznaczony jako „Tylko strefa UE”. Jeśli proces pobiera dane z tego magazynu do innej strefy, diagram wskazuje potencjalne naruszenie zgodności. Pozwala to architektom rozwiązać problemy jeszcze przed napisaniem kodu.
Jednym z największych wyzwań związanych z DFD jest ich utrzymanie. W miarę zmian kodu diagram często staje się przestarzały. Nowoczesne przepływy pracy dążą do wypełnienia tej luki poprzez automatyzację.
Choć całkowicie automatyczne diagramy jeszcze nie są idealne, zapewniają podstawę, która znacznie bliższa rzeczywistości niż statyczny dokument stworzony miesiące temu. Zachowuje to aktualność dokumentacji w miarę iteracji systemu. 🔄
Ewolucja DFD trwa. Wraz z postępem technologii rozwijają się również techniki modelowania.
Modele uczenia maszynowego wprowadzają nieokreślone przepływy. Proces może generować różne wyniki na podstawie prawdopodobieństwa zamiast ustalonej logiki. Przyszłe DFD mogą wymagać oddzielnego przedstawienia przedziałów ufności lub przepływów danych treningowych w porównaniu do przepływów danych wnioskowania. To dodaje nowy wymiar do węzłów magazynu danych i procesów.
Diagramy statyczne są dobre do projektowania, ale co z operacjami? Przyszłe wersje mogą łączyć diagramy z działającymi pulpitem. Jeśli przepływ danych zostanie zablokowany w środowisku produkcyjnym, odpowiedni strzałka na diagramie może się rozjaśnić na czerwono. Tworzy to żywy dokument odzwierciedlający aktualny stan systemu.
Obecnie nie ma uniwersalnego standardu reprezentowania zdarzeń w DFD. W miarę jak branża zbiega się do określonych wzorców zdarzeń (np. CQRS lub Event Sourcing), prawdopodobnie pojawi się standardowy zestaw symboli. Dzięki temu diagramy będą wzajemnie zgodne między różnymi zespołami i organizacjami.
Aby rozpocząć dostosowanie obecnych praktyk modelowania, postępuj zgodnie z poniższym ogólnym sekwencją.
Diagram przepływu danych przetrwał dekady zmian technologicznych, ponieważ jego podstawowy cel nadal jest ważny: jasność. Choć notacja musi się rozszerzać, aby uwzględnić mikroserwisy, infrastrukturę chmurową i zdarzenia asynchroniczne, podstawowy cel wizualizacji przepływu danych pozostaje niezmieniony. Poprzez aktualizację symboli i modelu poznawczego, zespoły mogą nadal używać DFD jako głównego narzędzia analizy systemu. Ewolucja nie polega na zastępowaniu metody, ale na jej dopasowaniu do złożoności współczesnego cyfrowego środowiska. 🌐