 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











सॉफ्टवेयर प्रणालियों की वास्तुकला में, डेटा प्रवाह आरेख (DFD) के बराबर कोई अन्य उपकरण इतना महत्वपूर्ण नहीं है। तकनीकी विवरण और कोड भंडार जैसे तत्व बहुत महत्वपूर्ण हैं, लेकिन DFD व्यापार तर्क और � ingineering कार्यान्वयन के बीच एक सार्वभौमिक अनुवादक के रूप में कार्य करता है। यह आवश्यकताओं के अंत और कार्यान्वयन के आरंभ के बीच के अंतर को पार करता है। जब एक विश्लेषक एक प्रक्रिया बनाता है, तो वह बस डेटा के आंदोलन का चित्रण नहीं कर रहा है; वह प्रणाली के घटकों के बीच बातचीत के संवाद को परिभाषित कर रहा है। डेवलपर्स के लिए, यह आरेख डेटाबेस स्कीमा, API बिंदु, और प्रसंस्करण तर्क को सूचित करने वाला नक्शा है।
यह मार्गदर्शिका पेशेवर सेटिंग में डेटा प्रवाह आरेखों के व्यावहारिक उपयोग का अध्ययन करती है। हम इन आरेखों के संचार उपकरण के रूप में कार्य करने, स्पष्टता सुनिश्चित करने के लिए उपयोग किए जाने वाले विशिष्ट नोटेशन मानकों, और विश्लेषकों और डेवलपर्स के बीच आमतौर पर उत्पन्न होने वाले तनाव के बारे में जांच करेंगे। DFD के तत्वों को सिर्फ सैद्धांतिक परिभाषाओं से आगे बढ़कर समझने से टीमें अस्पष्टता को कम कर सकती हैं और व्यापार के उद्देश्य के अनुरूप प्रणालियां बना सकती हैं।
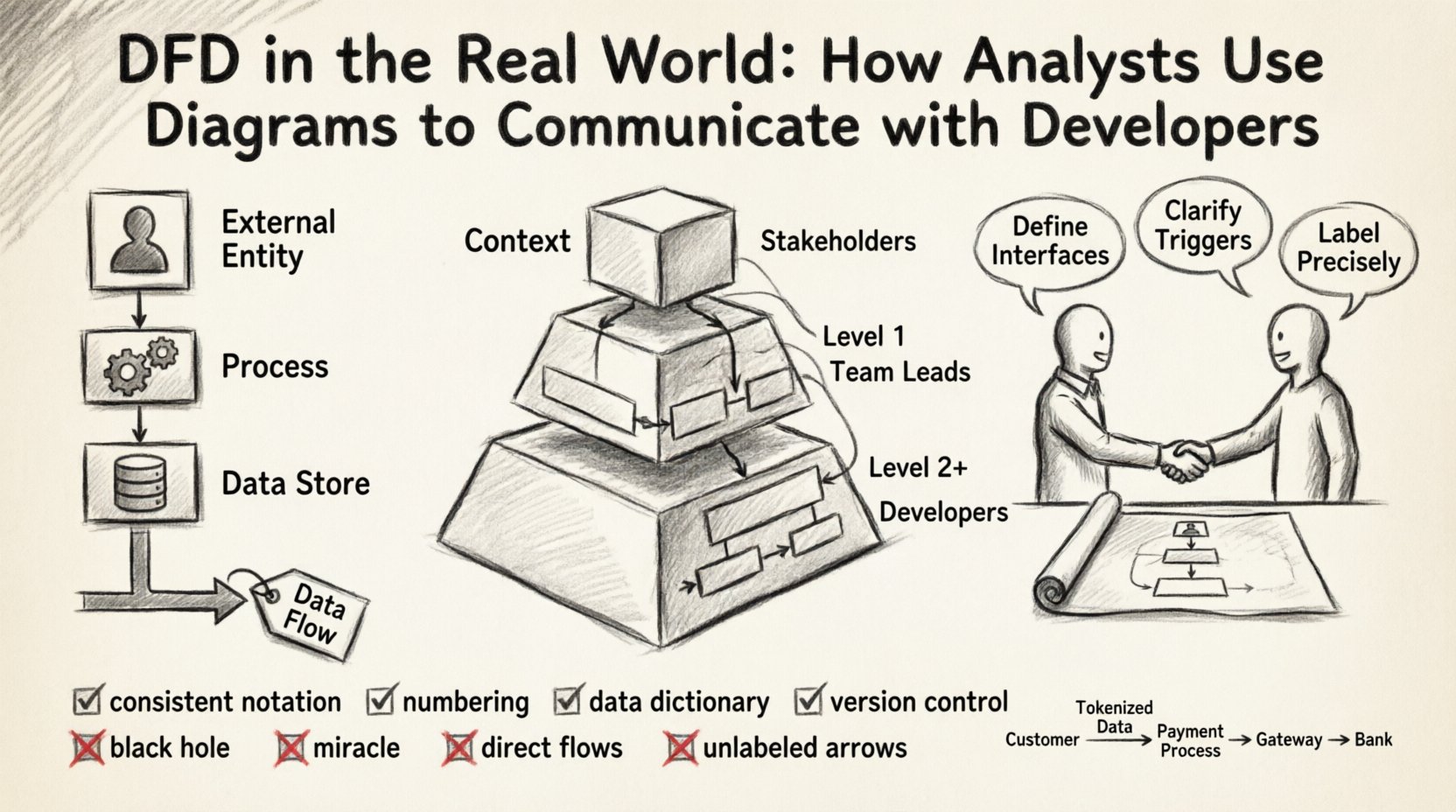
सहयोग रणनीतियों में डूबने से पहले, एक साझा शब्दावली बनाना आवश्यक है। डेटा प्रवाह आरेख एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। नियंत्रण प्रवाह और निर्णय तर्क को दर्शाने वाले फ्लोचार्ट के विपरीत, DFD सख्त रूप से डेटा परिवर्तन और गति पर ध्यान केंद्रित करता है। आरेख में प्रत्येक तत्व का एक विशिष्ट अर्थ होता है।
जब इन तत्वों को एक साथ जोड़ा जाता है, तो वे प्रणाली की सूचना वास्तुकला का नक्शा बनाते हैं। इस नक्शे की सटीकता लेबल की सटीकता और संबंधों की तार्किक सुसंगतता पर निर्भर करती है।
प्रभावी DFD को आमतौर पर एक ही बार में नहीं बनाया जाता है। वे अभिव्यक्ति के स्तरों के माध्यम से विकसित होते हैं, जिससे स्टेकहोल्डर्स को प्रणाली को विभिन्न अंतरालों में समझने में सहायता मिलती है। डेवलपर्स के हस्तांतरण के दौरान जटिलता को प्रबंधित करने के लिए इस पदानुक्रम का बहुत महत्व है।
यह सबसे ऊंचा स्तर का दृश्य है। यह प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और बाहरी एकाधिकारों के साथ इसके बातचीत को दर्शाता है। यह प्रणाली की सीमा को स्पष्ट रूप से परिभाषित करता है। डेवलपर के लिए, यह आरेख प्रश्न का उत्तर देता है: “यह प्रणाली किससे बात करती है?” यह सीमा निर्धारित करता है और दृश्य रूप से यह परिभाषित करके स्कोप क्रीप को रोकता है कि क्या अंदर है और क्या बाहर है।
यहां, मुख्य प्रक्रिया प्रमुख उप-प्रक्रियाओं में फैल जाती है। इस स्तर पर आंतरिक संरचना का पता चलता है, बिना हर एक तर्क गेट में फंसे रहे। यह आमतौर पर सीनियर डेवलपर्स के साथ वार्तालाप के लिए बातचीत के लिए पहला आरेख साझा किया जाता है। यह यह पहचानने में मदद करता है कि कौन से मॉड्यूल स्वतंत्र सेवाओं या अलग डेटाबेस तालिकाओं के रूप में आवश्यक हो सकते हैं।
ये आरेख विशिष्ट उप-प्रक्रियाओं में गहराई से जाते हैं। यहीं विस्तृत तर्क स्थित होता है। डेवलपर्स अक्सर यूनिट टेस्ट लिखते समय या विशिष्ट व्यापार नियमों को लागू करते समय इनका संदर्भ लेते हैं। हालांकि, इस स्तर पर अत्यधिक दस्तावेजीकरण रखरखाव के लिए बोझ बन सकता है।
| आरेख स्तर | प्राथमिक दर्शक | मुख्य उद्देश्य | विवरण का विस्तार |
|---|---|---|---|
| संदर्भ | हितधारक, वास्तुकार | सीमाओं को परिभाषित करें | उच्च (प्रणाली एक ब्लॉक के रूप में) |
| स्तर 1 | टीम लीड्स, आर्किटेक्ट्स | मॉड्यूल पहचानें | मध्यम (मुख्य उप-प्रक्रियाएँ) |
| स्तर 2+ | डेवलपर्स, एक्वालिटी एस्पेक्ट | लॉजिक परिभाषित करें | निम्न (विशिष्ट डेटा रूपांतरण) |
अच्छी तरह से बनाए गए आरेख के बावजूद भी गलत समझ आम है। विश्लेषक व्यापार मूल्य और डेटा अखंडता के संदर्भ में सोचता है। डेवलपर लेटेंसी, समानांतरता और डेटा प्रकार के संदर्भ में सोचता है। DFD मिलने का स्थान है, लेकिन इसके लिए अनुवाद की आवश्यकता होती है।
इन समस्याओं को कम करने के लिए, विश्लेषकों को आरेखों पर सीमाओं के साथ टिप्पणियाँ करनी चाहिए। डेवलपर्स को लागूता के लिए आरेखों की समीक्षा करनी चाहिए। यह सहयोगात्मक समीक्षा कोडिंग शुरू होने से पहले होनी चाहिए।
विकास चक्र के दौरान उपयोगी रहने वाले DFD को बनाए रखने के लिए अनुशासन की आवश्यकता होती है। अद्यतन न किए गए आरेख को एक दोष बन जाता है, जो विकास टीम को भ्रमित करता है और तकनीकी दायित्व उत्पन्न करता है।
DFD नोटेशन के दो प्रमुख स्कूल हैं: यौरडॉन/डेमार्को और गेन/सर्सन। जबकि वे आकृति में थोड़ा अंतर रखते हैं (प्रक्रियाओं के लिए गोल बनावट बनाम तीखे कोने), अर्थ लगभग एक जैसे रहते हैं। पूरी टीम को एक मानक पर सहमत होना चाहिए। एक ही प्रोजेक्ट में नोटेशन को मिलाने से मानसिक भार और भ्रम उत्पन्न होता है।
प्रक्रियाओं के लिए एक पदानुक्रमिक संख्या प्रणाली का उपयोग करें। उदाहरण के लिए, यदि शीर्ष स्तर की प्रक्रिया 0 है, तो पहली उप-प्रक्रिया 1.0 है, और उसकी उप-प्रक्रिया 1.1 है। इससे आसानी से प्रतिसंदर्भ बनाने में मदद मिलती है। यदि कोई डेवलपर “प्रक्रिया 3.2” का उल्लेख करता है, तो विश्लेषक को तुरंत यह पता चल जाता है कि लेवल 1 आरेख के किस हिस्से को देखना है।
एक डीएफडी कभी भी अकेले नहीं रह सकता। इसे डेटा शब्दकोश के साथ जोड़ा जाना चाहिए। इस दस्तावेज़ में तीरों में उपयोग किए जाने वाले प्रत्येक डेटा तत्व को परिभाषित किया जाता है। इसमें डेटा प्रकार, लंबाई और सीमाएँ (उदाहरण के लिए, “ईमेल पता: स्ट्रिंग, अधिकतम 255, अद्वितीय”) निर्दिष्ट की जाती हैं।
कोड की तरह, आरेख बदलते हैं। एक फीचर अपडेट एक नया डेटा प्रवाह जोड़ सकता है या किसी प्रक्रिया को बदल सकता है। इन बदलावों को ट्रैक करना आवश्यक है। टीमों को आरेखों के संस्करणों का इतिहास बनाए रखना चाहिए। जब कोई डेवलपर पूछता है, “हमने पेमेंट प्रवाह कब जोड़ा?”, तो संस्करण इतिहास उत्तर देता है।
यहां तक कि अनुभवी व्यवसायियों को भी गलतियाँ होती हैं। इन पैटर्नों को जल्दी पहचानने से कोडिंग चरण में काफी समय बचता है।
यह तब होता है जब किसी प्रक्रिया के इनपुट होते हैं लेकिन आउटपुट नहीं होते। इसका अर्थ है कि डेटा का निर्माण या उपयोग किया जा रहा है बिना किसी परिणाम के। वास्तविक प्रणाली में, यह अक्सर एक गायब नोटिफिकेशन, लॉगिंग की आवश्यकता या भूल गए डेटाबेस लेखन को इंगित करता है।
यह काले छेद के विपरीत है। एक प्रक्रिया के आउटपुट होते हैं लेकिन इनपुट नहीं होते। इसका अर्थ है कि डेटा बिना किसी कारण के दिखाई देता है। व्यवहार में, इसका अक्सर अर्थ होता है कि डेटा स्रोत आरेख में छोड़ दिया गया है, जैसे कि डिफ़ॉल्ट मान या सिस्टम क्लॉक।
डेटा को एक बाहरी स्रोत से दूसरे बाहरी स्रोत में सीधे बिना प्रणाली के माध्यम से जाने देना चाहिए। यदि एक उपयोगकर्ता डेटा दूसरे उपयोगकर्ता को भेजता है, तो उसे एक प्रक्रिया के माध्यम से जाना चाहिए जो उसकी पुष्टि और निर्देशन करे। सीधे प्रवाह सुरक्षा जांच और व्यावसायिक तर्क को छोड़ देते हैं।
लेबल रहित तीर बेकार हैं। वे डेवलपर को अनुमान लगाने के लिए मजबूर करते हैं कि क्या स्थानांतरित किया जा रहा है। यदि किसी प्रवाह को “डेटा” के रूप में लेबल किया गया है, तो यह बहुत व्यापक है। सामग्री का वर्णन करने वाले विशिष्ट संज्ञाओं का उपयोग करें।
एक डीएफडी एक जीवित दस्तावेज है। इसे सॉफ्टवेयर के साथ विकसित होना चाहिए। प्रारंभिक आरेख यह बताने का एक परिकल्पना है कि प्रणाली कैसे काम करती है। जैसे-जैसे डेवलपर्स निर्माण और परीक्षण करते हैं, वास्तविकता भिन्न हो सकती है। आरेख को वास्तविक कार्यान्वयन को दर्शाने के लिए अद्यतन किया जाना चाहिए।
इस पुनरावृत्तिक प्रक्रिया में शामिल है:
व्यावहारिक अनुप्रयोग को समझाने के लिए, भुगतान प्रक्रिया मॉड्यूल को लें। बाहरी स्रोत ग्राहक, भुगतान गेटवे और बैंक हैं। प्रणाली ग्राहक से एक “भुगतान अनुरोध” प्राप्त करती है।
परिदृश्य A: खराब संचार
विश्लेषक एक प्रक्रिया बनाता है जिसे “भुगतान प्रक्रिया” कहा जाता है। विकासकर्ता मानता है कि यह क्रेडिट कार्ड को सीधे संभालता है। आरेख में बैंक को नहीं दिखाया गया है। विकासकर्ता एक ऐसा समाधान बनाता है जो कार्ड विवरण संग्रहीत करता है, जिससे सुरक्षा संगतता का उल्लंघन होता है क्योंकि DFD में गेटवे को सौंपने के आवश्यकता को नहीं दिखाया गया था।
परिदृश्य B: प्रभावी संचार
विश्लेषक “भुगतान प्रक्रिया” उप-प्रक्रिया बनाता है। यह भुगतान गेटवे (बाहरी एकाधिकार) की ओर एक प्रवाह दिखाता है, जिसे “टोकनीकृत कार्ड डेटा” लेबल किया गया है। यह एक लौटने वाले प्रवाह को दिखाता है जिसे “लेनदेन स्थिति” लेबल किया गया है। डेटा शब्दकोश के अनुसार “टोकनीकृत कार्ड डेटा” एक संदर्भ पहचानकर्ता है, कच्ची संख्याओं के बजाय। विकासकर्ता तुरंत जान जाता है कि भंडारण तर्क बनाने के बजाय API एकीकरण का उपयोग करना चाहिए।
दूसरा परिदृश्य सुरक्षा उल्लंघन को रोकता है। आरेख एक सीमा के रूप में कार्य करता है, जिससे विकासकर्ता सही आर्किटेक्चरल निर्णय की ओर दिशा देता है।
विकासकर्ताओं के लिए, DFD तकनीकी निर्णयों का सीधा पूर्वगामी है। प्रत्येक तीर एक नेटवर्क कॉल, डेटाबेस क्वेरी या मेमोरी पढ़ने/लिखने का प्रतिनिधित्व करता है।
डेटा प्रवाह आरेख का मूल्य इसकी भौतिक सुंदरता में नहीं, बल्कि इसकी अस्पष्टता को कम करने की क्षमता में है। यह विश्लेषक को यह सोचने पर मजबूर करता है कि डेटा कहां से आता है और कहां जाता है। यह विकासकर्ता को कोड लिखने से पहले प्रणाली के उद्देश्य को समझने के लिए मजबूर करता है।
जब सही तरीके से उपयोग किया जाता है, तो DFD विकास में एक चुप्पी साथी होता है। यह ध्यान आकर्षित करने के लिए चिल्लाता नहीं है, लेकिन यह यह सुनिश्चित करता है कि आधार ठोस है। वे टीमें जो सटीक, बनाए रखे गए और सहयोगात्मक DFD में समय निवेश करती हैं, उन्हें विकास चक्र में अधिक सुचारु गति मिलती है, जिसमें कम पुनर्निर्माण और कम गलतफहमियां होती हैं। आरेख में लगाए गए प्रयास का लाभ अंतिम उत्पाद की स्थिरता और रखरखाव में दिखाई देता है।
मानक निरूपणों का पालन करने, डेटा शब्दकोश को बनाए रखने और आरेख को एक जीवंत कृति के रूप में मानने से संगठन यह सुनिश्चित कर सकते हैं कि विश्लेषण और इंजीनियरिंग के बीच संचार स्पष्ट, सटीक और प्रभावी बना रहे। यह समन्वय सफल प्रणाली वास्तुकला की रीढ़ है।