 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











एक विश्वसनीय सूचना प्रणाली का डिज़ाइन करने के लिए कोडिंग से अधिक चाहिए; इसमें प्रक्रिया के माध्यम से डेटा के आवागमन को स्पष्ट रूप से समझने की आवश्यकता होती है। डेटा फ्लो डायग्राम (DFD) इस आवागमन के लिए ब्लूप्रिंट का काम करता है। यह बाहरी एकाधिकार, आंतरिक प्रक्रियाओं और डेटा स्टोर के बीच सूचना के प्रवाह को दृश्याकृत करता है। यह गाइड प्रभावी DFD बनाने के लिए गहन विश्लेषण प्रदान करता है, जिससे आपका प्रणाली विश्लेषण संरचित, तार्किक और स्केलेबल हो।
चाहे आप एक नए एप्लिकेशन का डिज़ाइन कर रहे हों या मौजूदा एक का ऑडिट कर रहे हों, डेटा फ्लो के सिद्धांत स्थिर रहते हैं। इस गाइड में एनाटॉमी, स्तर, निर्माण चरण और विशेष उपकरणों के बिना पेशेवर गुणवत्ता वाले आरेख बनाने के लिए आवश्यक बेस्ट प्रैक्टिस को कवर किया गया है। फोकस विज़ुअलाइज़ेशन के पीछे की विधि और तर्क पर बना रहता है।
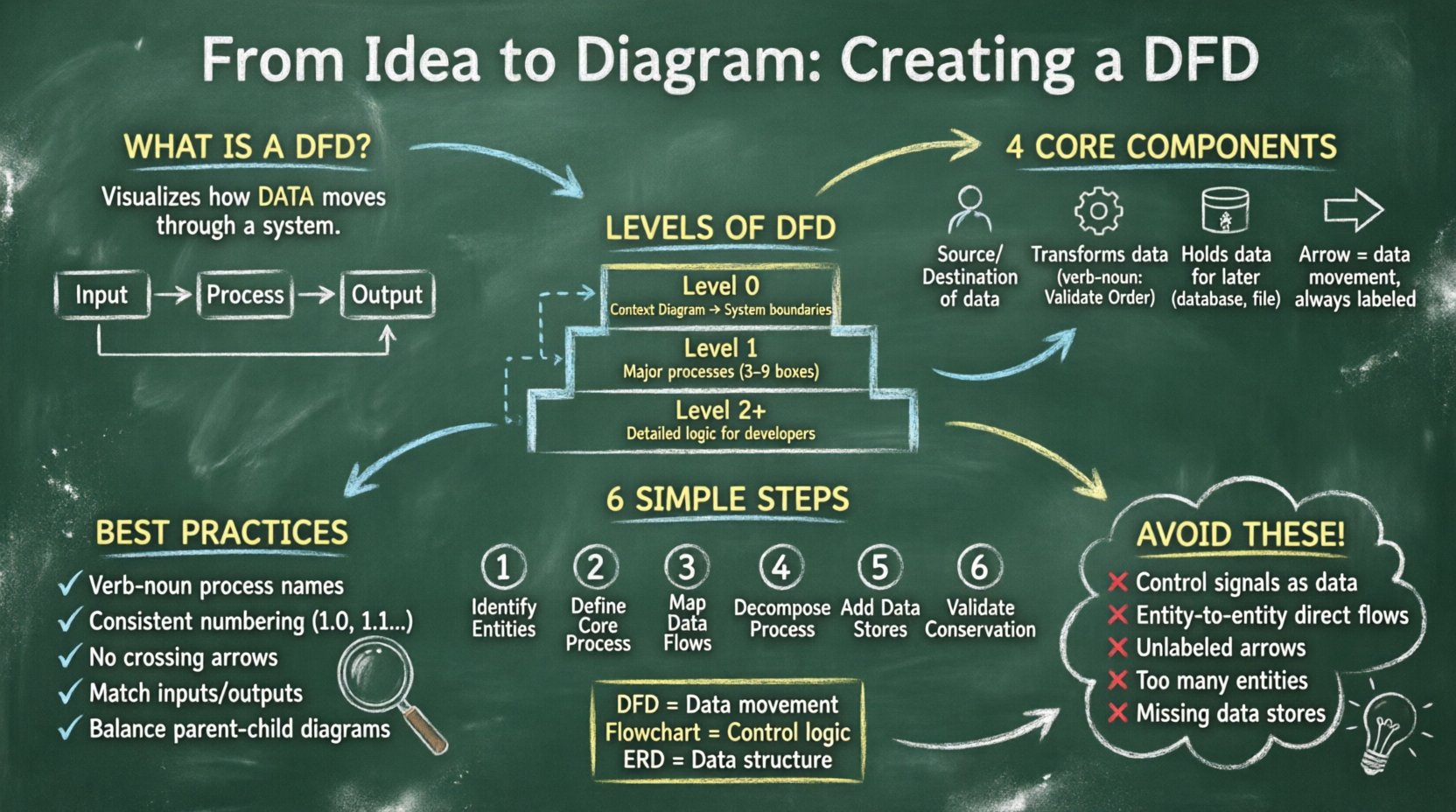
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। फ्लोचार्ट के विपरीत जो नियंत्रण तर्क और निर्णय लेने के चरणों पर ध्यान केंद्रित करता है, DFD डेटा के आपस में ध्यान केंद्रित करता है। यह प्रश्नों के उत्तर देता है: डेटा कहाँ से आता है? इसके साथ क्या होता है? यह कहाँ जाता है? और यह कहाँ संग्रहीत किया जाता है?
DFD संरचित विश्लेषण और डिज़ाइन विधियों के लिए अनिवार्य हैं। ये स्टेकहोल्डर्स को प्रणाली की सीमाओं को देखने में मदद करते हैं और गायब डेटा पथ या अनावश्यक जटिलता की पहचान करते हैं। जटिल प्रणालियों को प्रबंधन योग्य स्तरों में बांटकर, विश्लेषक सुनिश्चित कर सकते हैं कि प्रत्येक डेटा का एक परिभाषित उद्देश्य और गंतव्य हो।
एक वैध DFD बनाने के लिए, आपको आरेख में उपयोग किए जाने वाले चार मूल संकेतों को समझना आवश्यक है। ये संकेत सार्वभौमिक हैं और उपयोग की जाने वाली नोटेशन शैली (जैसे यौरडॉन/डेमार्को या गेने/सर्सन) के आधार पर नहीं बदलते हैं। इन घटकों को समझना सटीक मॉडलिंग के लिए आवश्यक है।
निम्नलिखित तालिका इन घटकों के बीच बातचीत का सारांश प्रस्तुत करती है:
| घटक | कार्य | इनपुट आवश्यक | आउटपुट आवश्यक |
|---|---|---|---|
| बाहरी एकाधिकार | डेटा शुरू करता है या प्राप्त करता है | नहीं | हाँ (या सिंक के लिए नहीं) |
| प्रक्रिया | डेटा को परिवर्तित करता है | हाँ | हाँ |
| डेटा स्टोर | डेटा को बनाए रखता है | हाँ (लेखन) | हाँ (पढ़ना) |
| डेटा प्रवाह | डेटा को परिवहन करता है | उपलब्ध नहीं | उपलब्ध नहीं |
जटिल प्रणालियों को एक ही दृश्य में वर्णित नहीं किया जा सकता है। जटिलता को प्रबंधित करने के लिए DFD को विभिन्न विवरण स्तरों पर बनाया जाता है। इस तकनीक को “विघटन” के रूप में जाना जाता है। आप एक उच्च स्तर के समीक्षा के साथ शुरू करते हैं और प्रक्रियाओं को उप-प्रक्रियाओं में धीरे-धीरे तोड़ते हैं जब तक कि विवरण का स्तर कार्यान्वयन के लिए पर्याप्त नहीं हो जाता।
संदर्भ आरेख सबसे ऊंचे स्तर के अब्राक्शन का प्रतिनिधित्व करता है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एजेंसियों के साथ बातचीत को दर्शाता है। इस आरेख ने प्रणाली की सीमाओं को स्थापित करता है। यह प्रश्न का उत्तर देता है: “प्रणाली के रूप में क्या है?”
स्तर 1 आरेख में, संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में फैलाया जाता है। इससे बाहरी एजेंसियों के साथ मुख्य कार्यात्मक क्षेत्रों को जोड़ने के बिना प्रणाली की आंतरिक संरचना प्रकट होती है।
स्तर 2 आरेख स्तर 1 से विशिष्ट प्रक्रियाओं को और अधिक विभाजित करते हैं। यह तब तक जारी रहता है जब तक कि प्रक्रियाएं डेवलपर्स या ऑपरेटर्स द्वारा समझने योग्य नहीं हो जाती हैं। बहुत जटिल एल्गोरिदम या वित्तीय गणनाओं के लिए स्तर 3 या स्तर 4 आरेख की आवश्यकता हो सकती है।
| स्तर | फोकस | जटिलता | प्राथमिक दर्शक |
|---|---|---|---|
| संदर्भ आरेख | प्रणाली सीमाएं | कम (1 प्रक्रिया) | हितधारक, प्रबंधन |
| स्तर 1 | मुख्य कार्यात्मक क्षेत्र | मध्यम (3-9 प्रक्रियाएं) | विश्लेषक, प्रोजेक्ट प्रबंधक |
| स्तर 2+ | विशिष्ट उप-प्रक्रियाएं | उच्च (विस्तृत तर्क) | विकासकर्ता, प्रोग्रामर |
DFD बनाना एक व्यवस्थित प्रक्रिया है। बस आकृतियाँ बनाने के लिए पर्याप्त नहीं है; आपको तर्कसंगत क्रम का पालन करना होगा ताकि सभी स्तरों पर डेटा की अखंडता और सुसंगतता सुनिश्चित हो सके।
सभी डेटा स्रोतों और गंतव्यों की सूची बनाने से शुरुआत करें। ये उपयोगकर्ता, अन्य प्रणालियाँ या विभाग हैं जो आपकी प्रणाली के साथ बातचीत करते हैं। आंतरिक डेटा स्टोर को यहाँ न रखें; उन्हें अलग रखें। प्रत्येक एकाधिकार का स्पष्ट नाम होना चाहिए, जैसे “ग्राहक,” “प्रशासक,” या “भुगतान गेटवे।” यदि विभिन्न प्रकार के उपयोगकर्ता हैं, तो “उपयोगकर्ता” जैसे अस्पष्ट शब्दों से बचें।
संदर्भ आरेख के लिए, प्रणाली का प्रतिनिधित्व करने वाले एक एकल वृत्त को बनाएं। इसे प्रणाली के नाम से लेबल करें। यह आपका आधार बिंदु है। सुनिश्चित करें कि इस वृत्त में प्रवेश और निकास होने वाले सभी डेटा प्रवाह चरण 1 में पहचाने गए एकाधिकारों से संबंधित हों।
एकाधिकारों को प्रक्रिया से जोड़ने वाली तीर बनाएं। प्रत्येक तीर को स्थानांतरित होने वाले विशिष्ट डेटा के साथ लेबल करें। “डेटा” लिखने के बजाय, “आदेश विवरण” या “बिल” लिखें। इस विशिष्टता को बाद के विकास चरणों के लिए महत्वपूर्ण है। सुनिश्चित करें कि कोई भी तीर दूसरे तीर को बिना स्पष्ट संयोजन बिंदु के पार नहीं करता है।
लेवल 1 बनाने के लिए, एकल प्रणाली वृत्त को बहुत प्रक्रियाओं से बदलें। इन प्रक्रियाओं को मुख्य कार्यों का प्रतिनिधित्व करना चाहिए, जैसे “आदेश की पुष्टि करें,” “भुगतान प्रक्रिया करें,” और “इन्वेंटरी अद्यतन करें।” पिछले चरण में पहचाने गए डेटा प्रवाहों का उपयोग करके इन प्रक्रियाओं को एक दूसरे और बाहरी एकाधिकारों से जोड़ें।
यह पहचानें कि डेटा कहाँ सहेजा जाना चाहिए। यदि डेटा बाद की प्रक्रिया या रिपोर्टिंग के लिए आवश्यक है, तो इसे डेटा स्टोर में जाना चाहिए। डेटा स्टोर को उस प्रक्रिया से जोड़ें जो इसमें लिखती है और उस प्रक्रिया से जो इसे पढ़ती है। याद रखें, एक प्रक्रिया दूसरी प्रक्रिया में सीधे लिख नहीं सकती है; यदि स्थायित्व की आवश्यकता हो, तो इसे स्टोर के माध्यम से जाना होगा।
प्रत्येक प्रक्रिया की जांच करें ताकि इनपुट आउटपुट के बराबर हों। यह डेटा संरक्षण का सिद्धांत है। आप डेटा को निर्वात से नहीं बना सकते हैं, न ही बिना रिकॉर्ड के इसे मिटा सकते हैं। यदि कोई प्रक्रिया इनपुट है लेकिन आउटपुट नहीं है, तो यह एक “काला छेद” है। यदि इसके आउटपुट हैं लेकिन इनपुट नहीं हैं, तो यह एक “चमत्कार” है। दोनों मॉडल में त्रुटियाँ हैं।
DFD एक संचार उपकरण है। यदि इसे पढ़ने में भ्रम होता है, तो यह अपने मुख्य उद्देश्य को पूरा नहीं करता है। सख्त नियमों का पालन करने से टीमों के बीच स्पष्टता बनी रहती है।
यहाँ भी अनुभवी विश्लेषक गलतियाँ कर सकते हैं। इन सामान्य त्रुटियों को जल्दी पहचानने से बाद में बड़े पैमाने पर पुनर्कार्य करने से बचा जा सकता है।
DFD को अन्य डायग्रामिंग विधियों के साथ भ्रमित करना आम है। अंतर को समझने से यह सुनिश्चित होता है कि आप काम के लिए सही उपकरण का उपयोग कर रहे हैं।
| डायग्राम प्रकार | फोकस | सबसे अच्छा उपयोग किसके लिए |
|---|---|---|
| डेटा प्रवाह आरेख | जानकारी का हस्तांतरण | प्रणाली की आवश्यकताएं, प्रक्रिया तर्क |
| फ्लोचार्ट | नियंत्रण तर्क, निर्णय | एल्गोरिदम डिजाइन, चरण-दर-चरण प्रक्रियाएं |
| एंटिटी संबंध आरेख | डेटा संरचना, संबंध | डेटाबेस डिजाइन, स्कीमा परिभाषा |
जबकि एक फ्लोचार्ट संचालन के क्रम (यदि X, तो Y) को दिखाता है, एक DFD डेटा रूपांतरणों के बीच निर्भरता को दिखाता है। DFD को निष्पादन के क्रम की चिंता नहीं होती है, बल्कि केवल जानकारी के प्रवाह की। इसलिए DFD को तर्क के अंतिम रूप देने से पहले प्रणाली की आवश्यकताओं के विश्लेषण के लिए आदर्श माना जाता है।
प्रणालियाँ विकसित होती हैं। आवश्यकताएं बदलती हैं, और विशेषताएं जोड़ी जाती हैं। एक प्रोजेक्ट के शुरू में बनाया गया DFD पुराना हो सकता है। प्रणाली के विकास के साथ आरेख को बनाए रखना बहुत महत्वपूर्ण है।
डेटा प्रवाह आरेख बनाना एक अनुशासन है जिसमें धैर्य और सटीकता की आवश्यकता होती है। यह आपको केवल कार्यों के बजाय डेटा के बारे में सोचने के लिए मजबूर करता है। उपरोक्त वर्णित संरचित दृष्टिकोण का पालन करके, आप सुनिश्चित करते हैं कि परिणामी मॉडल सटीक, रखरखाव योग्य और प्रणाली के पूरे जीवनचक्र के लिए उपयोगी है।
याद रखें कि लक्ष्य तुरंत एक सही चित्र बनाना नहीं है। यह विकास टीम को मार्गदर्शन करने वाला एक नक्शा बनाना है। संदर्भ आरेख से शुरुआत करें, सीमाओं की पुष्टि करें, और फिर विवरण में उतरें। जैसे आप अभ्यास करेंगे, विभाजन प्रक्रिया अधिक स्वाभाविक हो जाएगी, और आपके आरेख आपकी टीम के लिए एक शक्तिशाली संचार उपकरण के रूप में कार्य करेंगे।
डेटा पर ध्यान केंद्रित रखें। सुनिश्चित करें कि प्रत्येक तीर का एक उद्देश्य हो, प्रत्येक प्रक्रिया में एक रूपांतरण हो, और प्रत्येक भंडारण के अस्तित्व का कोई कारण हो। इस अनुशासित दृष्टिकोण से ऐसी प्रणालियाँ बनती हैं जो दृढ़, स्केलेबल और व्यापार की आवश्यकताओं के अनुरूप होती हैं।