 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











एक प्रणाली के माध्यम से जानकारी के आवागमन का दृश्य प्रतिनिधित्व बनाना विश्लेषकों, विकासकर्मियों और व्यावसायिक हितधारकों के लिए एक मूलभूत कौशल है। डेटा फ्लो डायग्राम, जिसे सामान्यतः DFD के रूप में जाना जाता है, इसी उद्देश्य के लिए होता है। यह बाहरी एकाधिकार, आंतरिक प्रक्रियाओं और डेटा भंडार के बीच डेटा के प्रवाह को नक्शा बनाता है, जिसमें विशिष्ट तर्क या समय के विवरण की आवश्यकता नहीं होती है। यह मार्गदर्शिका आपके प्रारंभिक DFD को कुशलतापूर्वक निर्माण करने के लिए एक संरचित दृष्टिकोण प्रदान करती है।
बहुत से लोग आरेखण को डरावना पाते हैं, डरते हैं कि इसके लिए जटिल उपकरण या विस्तृत समय की आवश्यकता होती है। हालांकि, डेटा प्रवाह मॉडलिंग के मूल सिद्धांत सरल हैं। संकेतों की स्पष्ट समझ और व्यवस्थित दृष्टिकोण के साथ, आप एक फलप्रद आरेख को छोटे समय में बना सकते हैं। यह लेख आपको आवश्यक घटकों, चरण-दर-चरण निर्माण प्रक्रिया और सटीकता सुनिश्चित करने के लिए आवश्यक जांच चरणों के माध्यम से चलता है।
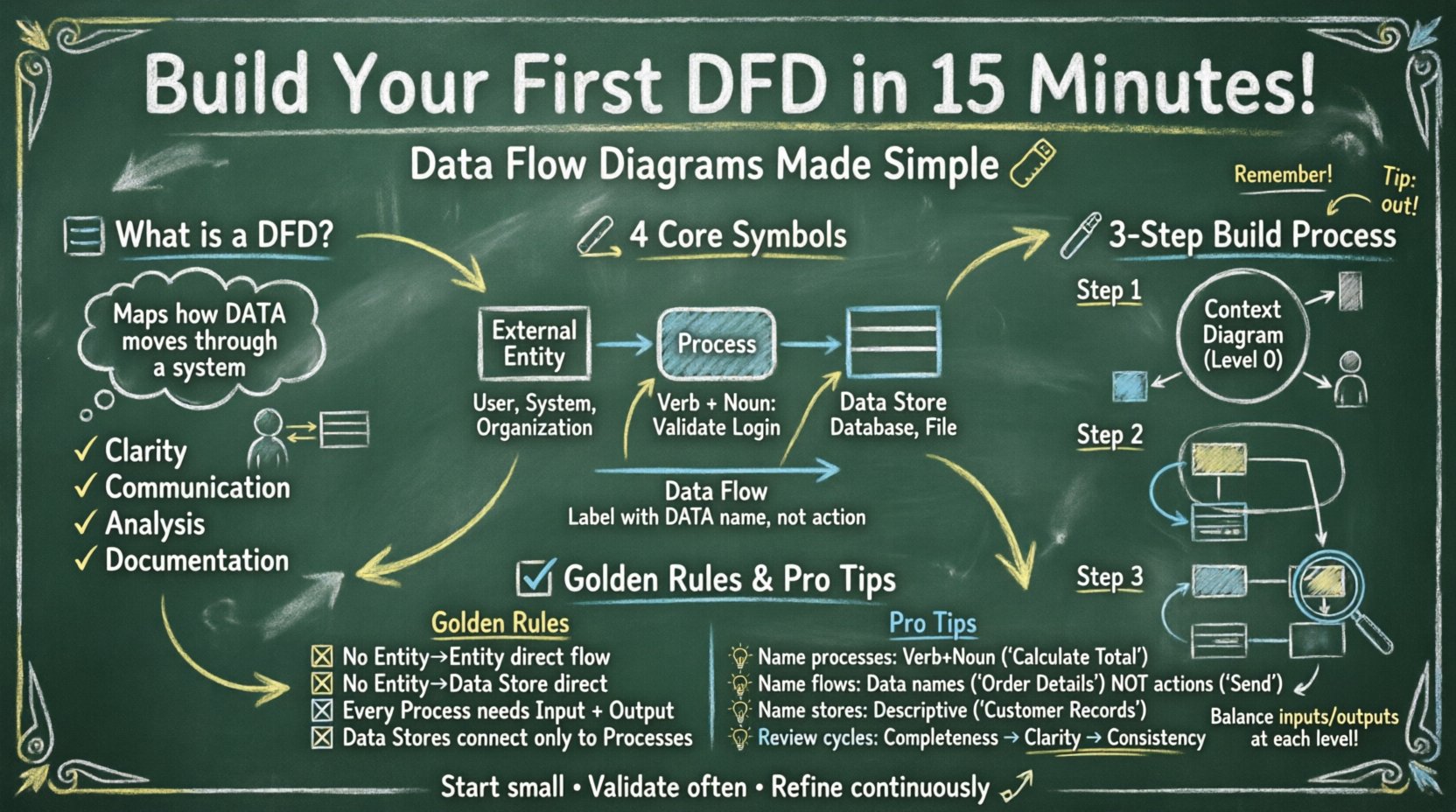
रेखाओं और आकृतियों को बनाने से पहले, यह समझना महत्वपूर्ण है कि DFD का क्या अर्थ है। यह एक क्रियात्मक मॉडल है। यह क्या प्रणाली करती है, बल्कि कैसे यह कैसे करती है। फ्लोचार्ट के विपरीत, जो निर्णय मार्गों और तार्किक क्रम का अनुसरण करता है, DFD डेटा पैकेट के स्रोत से गंतव्य तक गति का अनुसरण करता है।
इस मॉडलिंग तकनीक के उपयोग के मुख्य लाभ निम्नलिखित हैं:
जब आप इस अभ्यास की शुरुआत करें, तो लक्ष्य को ध्यान में रखें: अपनी विशिष्ट प्रणाली की सीमाओं और बातचीत को दृश्य रूप से प्रस्तुत करना। शुरुआत करने के लिए उन्नत सॉफ्टवेयर की आवश्यकता नहीं है। एक सफेद बोर्ड, एक कागज का एक टुकड़ा और एक पेन प्रारंभिक ड्राफ्ट के लिए पर्याप्त उपकरण हैं।
DFD के एक मानकीकृत ग्राफिकल तत्वों के सेट पर निर्भर करते हैं। हालांकि नोटेशन में भिन्नताएं हैं (जैसे यूरडॉन/डेमार्को बनाम गेने/सर्सन), लेकिन मूल अवधारणाएं संगत रहती हैं। नीचे आपको मिलने वाले चार प्राथमिक घटकों का विवरण दिया गया है।
| घटक | आकृति | विवरण |
|---|---|---|
| बाहरी एकाधिकार | आयत या वर्ग | प्रणाली के बाहर डेटा का स्रोत या गंतव्य (उदाहरण के लिए, उपयोगकर्ता, एक अन्य प्रणाली)। |
| प्रक्रिया | गोल आयत या वृत्त | इनपुट डेटा को आउटपुट डेटा में बदलता है। यह रूप या सामग्री को बदलता है। |
| डेटा स्टोर | खुला आयत या समानांतर रेखाएँ | एक भंडारण स्थान जहाँ डेटा रहता है (उदाहरण के लिए, डेटाबेस, फाइल कैबिनेट). |
| डेटा प्रवाह | तीर | घटकों के बीच डेटा के लेन-देन का मार्ग। यह क्रिया के बजाय गति का प्रतिनिधित्व करता है। |
इन अंतरों को समझना बहुत महत्वपूर्ण है। उदाहरण के लिए, एक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होना चाहिए। एक डेटा स्टोर बस अकेले अस्तित्व में नहीं आ सकता; इसे पढ़ने या लिखने के लिए किसी प्रक्रिया से जुड़ना होगा। बाहरी एकाधिकार तंत्र की सीमा के बाहर होते हैं, जो ट्रिगर या प्राप्तकर्ता के रूप में कार्य करते हैं।
सुझाए गए समय सीमा के भीतर अपना आरेख बनाने के लिए, इस तर्कसंगत क्रम का पालन करें। इस विधि से आप विवरणों में डूबने से पहले सीमाओं को स्थापित करने की गारंटी मिलती है।
एक से शुरू करेंसंदर्भ आरेख (अक्सर स्तर 0 कहलाता है)। यह सर्वोच्च स्तर का दृश्य है। यह प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी दुनिया के साथ बातचीत को दर्शाता है।
उदाहरण के लिए, एक पुस्तकालय प्रणाली में, “उधारकर्ता” एक एकाधिकार है। “पुस्तक जारी करना” प्रक्रिया प्रणाली है। डेटा प्रवाह “ऋण अनुरोध” या “पुस्तक विवरण” हो सकता है।
जब संदर्भ निर्धारित हो जाता है, तो आपको एकल मुख्य प्रक्रिया को उप-प्रक्रियाओं में विस्तारित करना होगा। इससे एक बनता हैस्तर 0 आरेख.
सुनिश्चित करें कि संदर्भ आरेख में किसी एकांक के बाहर निकलने वाली प्रत्येक तीर स्तर 0 आरेख में अभी भी दिखाई दे, लेकिन अब यह विभिन्न आंतरिक प्रक्रियाओं से जुड़ सकती है।
इससे संबंधित है स्तर 1 आरेख। आप स्तर 0 से एक प्रक्रिया चुनते हैं और इसे और अधिक विभाजित करते हैं।
यदि आरेख के लेबल अस्पष्ट हैं, तो वह बेकार है। स्पष्ट नामकरण प्रणाली समीक्षा और कार्यान्वयन के दौरान भ्रम को रोकती है।
प्रक्रिया के नाम एक क्रिया-संज्ञा संरचना का पालन करने चाहिए। इससे लेनदेन की क्रिया स्पष्ट हो जाती है।
“प्रक्रिया 1” जैसे सामान्य नामों से बचें, जब तक आप बहुत शुरुआती ड्राफ्टिंग चरण में न हों। विशिष्ट नाम समझ में मदद करते हैं।
तीर एक्रियन के बजाय डेटा का प्रतिनिधित्व करते हैं। उन्हें डेटा पैकेट के नाम से लेबल करें।
इन्हें संग्रहीत सामग्री को इंगित करना चाहिए।
ड्राफ्ट बनाने के बाद, आंतरिकता सुनिश्चित करने के लिए आरेख की मानक नियमों के अनुसार समीक्षा करें। एक वैध DFD को विशिष्ट तार्किक सीमाओं का पालन करना चाहिए।
यहां तक कि अनुभवी विश्लेषक भी प्रारंभिक मॉडलिंग के दौरान गलतियां करते हैं। इन सामान्य त्रुटियों से बचें:
DFD बनाना अक्सर एक बार का कार्य नहीं होता है। यह सुधार की पुनरावृत्तिक प्रक्रिया है। आपका पहला ड्राफ्ट लगभग निश्चित रूप से अंतराल या त्रुटियां होंगी। यह सामान्य है।
समीक्षा चक्र 1: पूर्णता की जांच करें। क्या सभी उपयोगकर्ता आवश्यकताएं प्रतिनिधित्व की गई हैं? क्या प्रत्येक डेटा स्रोत का ध्यान रखा गया है?
समीक्षा चक्र 2: स्पष्टता की जांच करें। क्या एक नए सदस्य को इसे देखकर बिना प्रश्न पूछे प्रवाह को समझने में सक्षम है?
समीक्षा चक्र 3: सुसंगतता की जांच करें। क्या आरेख के विभिन्न स्तरों पर नाम मेल खाते हैं? यदि स्तर 0 में डेटा प्रवाह को “ग्राहक जानकारी” कहा जाता है, तो यह स्तर 1 में भी सुसंगत होना चाहिए, जब तक कि इसे विशिष्ट विशेषताओं में विभाजित नहीं किया गया है।
आरेख को तेजी से अंतिम न बनाएं। स्टेकहोल्डर्स से प्रतिक्रिया प्राप्त करने के लिए समय दें। उनके योगदान से अक्सर छिपी हुई डेटा आवश्यकताएं या प्रक्रियाएं उजागर होती हैं जिन्हें आपने नजरअंदाज कर दिया था।
जैसे आपका सिस्टम बढ़ता है, एक ही पृष्ठ पर्याप्त नहीं हो सकता है। आपको कई आरेखों को प्रबंधित करने की आवश्यकता हो सकती है। यहां उन्हें तार्किक तरीके से व्यवस्थित करने का तरीका है।
पारस्परिक संदर्भ का उपयोग करें। यदि स्तर 1 में कोई प्रक्रिया स्तर 2 में विस्तारित की गई है, तो स्तर 1 में मूल प्रक्रिया को संदर्भ कोड (उदाहरण के लिए, “देखें आरेख 2.3”) के साथ चिह्नित करें। इससे आरेखों को नियंत्रित रखा जा सकता है बिना विवरण के नुकसान के।
जब आप डेटा प्रवाह के मॉडलिंग करते हैं, तो आप डेटा सुरक्षा के मॉडलिंग को भी अप्रत्यक्ष रूप से कर रहे होते हैं। एक मानक DFD में एन्क्रिप्शन या प्रमाणीकरण प्रोटोकॉल को नहीं दिखाया जाता है, लेकिन यह संवेदनशील डेटा के हस्तांतरण को दिखाता है।
यदि डेटा प्रवाह में व्यक्तिगत रूप से पहचान योग्य जानकारी (PII) या वित्तीय डेटा है, तो इसे संकेतक या लेबल में नोट करें। उदाहरण के लिए, प्रवाह को “एन्क्रिप्टेड भुगतान डेटा” लेबल करें। इससे डेवलपर्स को याद दिलाया जाता है कि उस विशिष्ट चैनल पर विशिष्ट सुरक्षा नियंत्रण लागू करने होंगे।
जब आरेख पूरा हो जाता है और मान्यता प्राप्त हो जाता है, तो यह विकास के लिए एक नक्शा बन जाता है। यह डेटाबेस डिजाइन, API परिभाषा और उपयोगकर्ता इंटरफेस लेआउट को मार्गदर्शन देता है। यह सुनिश्चित करता है कि अंतिम उत्पाद प्रारंभिक आवश्यकताओं के अनुरूप हो।
याद रखें कि उपकरण बुद्धिमत्ता के बाद दूसरे स्थान पर हैं। चाहे आप डिजिटल व्हाइटबोर्ड का उपयोग करें या पेन और कागज का, तर्क वही रहता है। मूल्य आपके द्वारा प्रणाली संरचना में लाए गए विचार की स्पष्टता में है।
ऊपर बताए गए चरणों का पालन करके आप एक पेशेवर ग्रेड का डेटा प्रवाह आरेख बना सकते हैं, जो आपकी परियोजना टीम के लिए भरोसेमंद संदर्भ के रूप में काम करता है। छोटे स्तर से शुरुआत करें, अक्सर मान्यता प्राप्त करें, और निरंतर सुधार करें। इस अनुशासित दृष्टिकोण से मजबूत प्रणाली डिजाइन बनते हैं।