 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











तकनीकी कंपनी के निर्माण के प्रारंभिक चरणों में स्पष्टता मूल्यवान है। संस्थापक अक्सर डेटा के नीचे के आंदोलन को पूरी तरह से देखे बिना सीधे कोडिंग में उतर जाते हैं। इस दृष्टिकोण के कारण बाद में तकनीकी देनदारी और जटिल डिबगिंग सेशन का खतरा रहता है। डेटा प्रवाह आरेख (DFD) एक संरचित तरीका प्रदान करता है जिससे जानकारी के प्रणाली में आंदोलन को देखा जा सकता है। यह मार्गदर्शिका एक वास्तविक दुनिया के प्रकरण का अध्ययन करती है जहां एक स्टार्टअप ने एक लाइन कोड लिखने से पहले अपनी आर्किटेक्चर को स्पष्ट करने के लिए इस विधि का उपयोग किया।
एक काल्पनिक स्टार्टअप के बारे में सोचें जिसका नाम “फ्लोस्टेट” है, जो दूरस्थ टीमों के लिए प्रोजेक्ट प्रबंधन प्लेटफॉर्म बनाने का लक्ष्य रखता है। मुख्य मूल्य प्रस्ताव में कार्य आवंटन, वास्तविक समय में स्थिति अपडेट और स्वचालित रिपोर्टिंग शामिल है। संस्थापक टीम को एक सामान्य समस्या का सामना करना पड़ा: उन्हें उपयोगकर्ता डेटा के इंटरफेस से डेटाबेस तक और वापस आने के तरीके के बारे में धुंधला विचार था।
एक स्पष्ट नक्शे के बिना, विकास टीम को निम्नलिखित जोखिम झेलना पड़ा:
हल अधिक बैठकों के बजाय बेहतर मॉडलिंग था। उन्होंने प्रणाली के तर्क को दस्तावेजीकरण के लिए डेटा प्रवाह आरेख विधि अपनाई। इस दृष्टिकोण ने उन्हें प्रणाली को एक स्थिर डेटाबेस के बजाय रूपांतरणों के श्रृंखला के रूप में देखने में सक्षम बनाया।
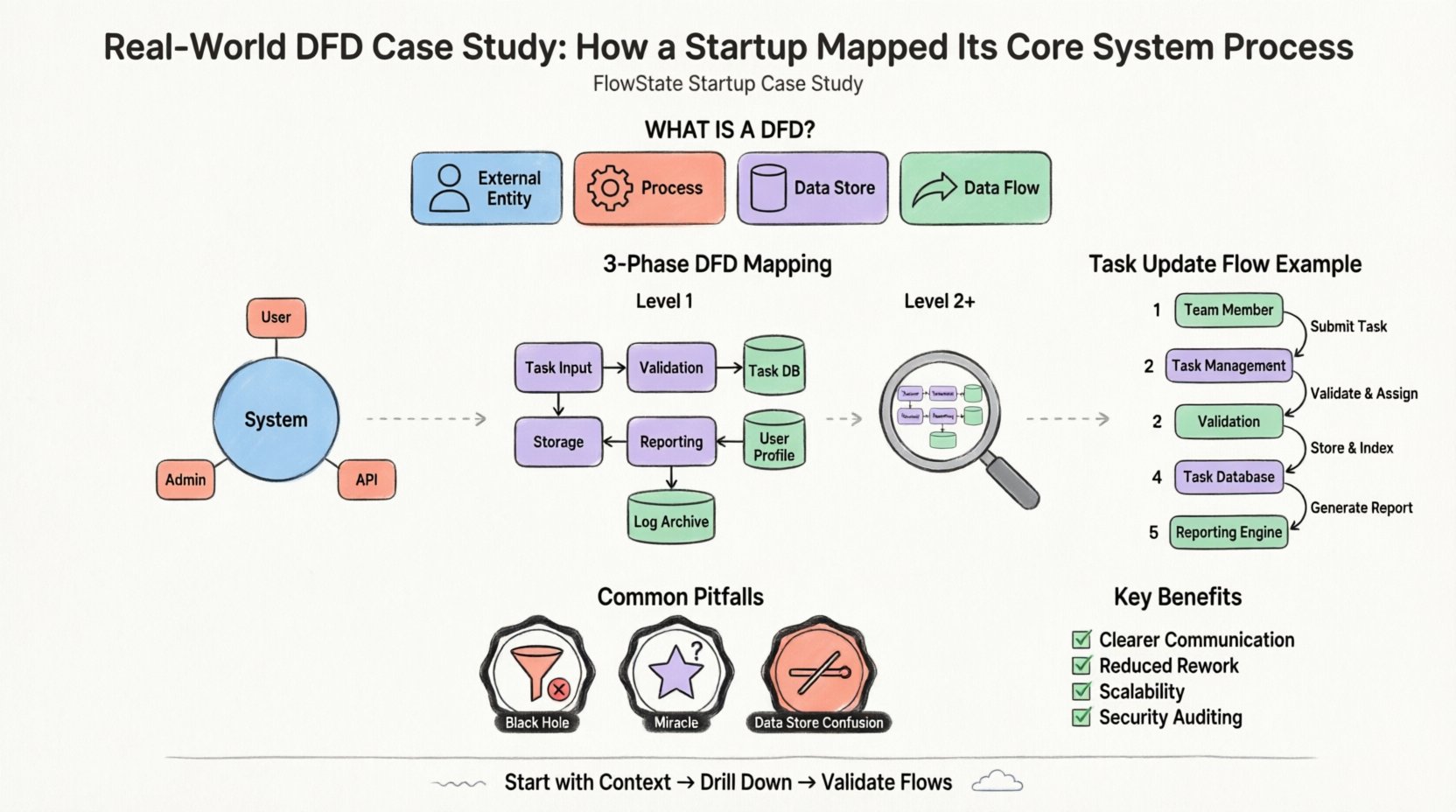
एक डेटा प्रवाह आरेख एक सूचना प्रणाली में डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। यह प्रक्रियाओं के समय या निर्णय लेने के तर्क (जैसे एल्गोरिदम) को नहीं दिखाता है, बल्कि डेटा के उत्पत्ति से गंतव्य तक आंदोलन पर ध्यान केंद्रित करता है। यह क्या, नहीं कैसे.
इस मॉडलिंग तकनीक में उपयोग किए जाने वाले मानक घटक इस प्रकार हैं:
फ्लोस्टेट परियोजना को इन घटकों में तोड़कर, टीम ने बाधाओं की पहचान करने और कार्यान्वयन से पहले डेटा अखंडता सुनिश्चित करने में सक्षम हुई।
प्रणाली के नक्शा बनाने का पहला चरण संदर्भ आरेख है। यह एक उच्च स्तरीय दृश्य है जो प्रणाली की सीमा को परिभाषित करता है। यह प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और यह बाहरी एकाधिकारों के साथ कैसे बातचीत करती है।
फ्लोस्टेट के लिए, सीमा प्रोजेक्ट प्रबंधन एप्लिकेशन ही है। इसके अंदर का सब कुछ सिस्टम का हिस्सा है; बाहर का सब कुछ एक एंटिटी है। टीम ने तीन प्राथमिक बाहरी एंटिटी की पहचान की:
टीम ने इनपुट और आउटपुट स्ट्रीम का प्रतिनिधित्व करने के लिए तीर खींचे। उदाहरण के लिए:
यह एकल आरेख ने सीमा को स्पष्ट कर दिया। यह टीम को गलती से “बिलिंग प्रोसेसिंग” जैसी सुविधाओं को शामिल करने से रोका जब वह समय में मूल सिस्टम का हिस्सा नहीं थी। इसने सिस्टम और उसके उपयोगकर्ताओं के बीच एक स्पष्ट संवाद स्थापित किया।
जब उच्च स्तर का संदर्भ स्थापित हो गया, तो टीम को आंतरिक कार्यप्रणाली को समझने की आवश्यकता थी। इसे लेवल 1 विघटन द्वारा प्राप्त किया जाता है। संदर्भ आरेख से एकल प्रक्रिया को उप-प्रक्रियाओं में विस्फोटित किया जाता है।
“फ्लोस्टेट सिस्टम” को तार्किक कार्यात्मक समूहों में विभाजित किया गया था। टीम ने निम्नलिखित मुख्य प्रक्रियाओं की पहचान की:
महत्वपूर्ण बात यह है कि लेवल 1 आरेख ने डेटा स्टोर का परिचय दिया। यह दिखाता है कि जानकारी कहाँ स्थायी रूप से संग्रहीत की जाती है। टीम ने तीन प्रमुख स्टोर की पहचान की:
इन स्टोर के नाम स्पष्ट रूप से बताकर, डेवलपर्स को तुरंत समझ में आ गया कि कौन सी डेटा को डेटाबेस में लिखने की आवश्यकता है और कौन सी डेटा को अस्थायी मेमोरी में रखने की आवश्यकता है।
लेवल 1 संरचना के स्थापित होने के बाद, टीम ने प्रक्रियाओं और स्टोर के बीच बहने वाली विशिष्ट डेटा की समीक्षा की। इस चरण में अक्सर त्वरित त्रुटियाँ पकड़ी जाती हैं।
आइए एक एकल डेटा बिंदु के आंदोलन का अनुसरण करें: एक “कार्य स्थिति परिवर्तन।”
इस अनुसरण ने एक संभावित समस्या का पता लगाया। टीम को एहसास हुआ कि “रिपोर्टिंग इंजन” हर बार कार्य में परिवर्तन होने पर हाथ से सक्रिय किया जा रहा था। उन्होंने इसे अनुकूलित करने का निर्णय लिया कि रिपोर्ट प्रक्रिया को केवल तब सक्रिय किया जाए जब एक विशिष्ट “स्थिति = पूर्ण” फ्लैग सेट की जाए, जिससे प्रणाली के बोझ में कमी आई।
परियोजना बढ़ने के साथ स्पष्टता बनाए रखने के लिए आरेख स्तरों के बीच अंतर को समझना आवश्यक है। नीचे दी गई तालिका इन अंतरों को दर्शाती है।
| स्तर | केंद्रित | सर्वोत्तम उपयोग के लिए |
|---|---|---|
| संदर्भ (स्तर 0) | प्रणाली सीमा | उच्च स्तर के हितधारक संचार |
| स्तर 1 | मुख्य प्रक्रियाएँ | आर्किटेक्चरल योजना और सीमा निर्धारण |
| स्तर 2+ | उप-प्रक्रिया विवरण | विशिष्ट कार्यान्वयन तर्क और डिबगिंग |
स्पष्ट विधि के होने के बावजूद, टीमें इन आरेखों के निर्माण के समय अक्सर गलतियाँ करती हैं। फ्लोस्टेट टीम को कई बाधाओं का सामना करना पड़ा और उन्हें बचने के तरीके सीखने पड़े।
एक प्रक्रिया जिसमें इनपुट है लेकिन आउटपुट नहीं है, वह एक काला छेद है। डेटा अंदर आता है और गायब हो जाता है। प्रारंभिक ड्राफ्ट में, “नोटिफिकेशन हैंडलर” डेटा प्राप्त करता था लेकिन बाहरी एजेंसी को जाने वाली तीर नहीं थी। टीम ने अनुमान लगाया कि उन्होंने वास्तविक भेजने की विधि को परिभाषित करना भूल दिया था। प्रत्येक प्रक्रिया को आउटपुट होना चाहिए।
एक प्रक्रिया जिसमें आउटपुट है लेकिन इनपुट नहीं है, वह एक चमत्कार है। इसका अर्थ है कि डेटा निर्माण बिना किसी कारण के हो रहा है। टीम के प्रारंभिक रूप में “रिपोर्ट जनरेट” प्रक्रिया थी जिसने “टास्क डेटाबेस” से पढ़े बिना डेटा उत्पन्न किया। उन्होंने इसे सुधारा दुर्गम डेटा प्रवाह को स्टोर से प्रक्रिया में जोड़कर।
प्रक्रियाएँ डेटा स्टोर से बातचीत करती हैं, लेकिन एजेंसियाँ नहीं। शुरुआत में, टीम ने “टीम सदस्य” से “टास्क डेटाबेस” तक सीधी रेखा खींची। इससे नियम का उल्लंघन होता है कि डेटा को परिवर्तित या प्रमाणित करने के लिए प्रक्रिया से गुजरना चाहिए। स्टोर से छूने वाली सभी डेटा को पहले प्रक्रिया से गुजरना चाहिए।
DFD विधि में सबसे महत्वपूर्ण नियमों में से एक संतुलन है। एक मातृ प्रक्रिया के इनपुट और आउटपुट को उसके बच्चे के आरेख (विघटन) के इनपुट और आउटपुट के मेल बनाना चाहिए।
फ्लोस्टेट के लिए, स्तर 1 आरेख में “टास्क मैनेजमेंट” प्रक्रिया के विशिष्ट इनपुट (टास्क डेटा) और आउटपुट (स्थिति अपडेट) थे। जब उन्होंने इसे स्तर 2 आरेखों (उदाहरण के लिए, “टास्क बनाएँ”, “टास्क हटाएँ”) में विभाजित किया, तो उन्होंने यह सुनिश्चित किया कि संयुक्त प्रवाह अभी भी मातृ प्रक्रिया के साथ मेल बनाते रहे। इससे यह सुनिश्चित होता है कि विघटन के दौरान कोई डेटा न तो खो जाए और न ही बनाया जाए।
इस दस्तावेजीकरण चरण में समय निवेश करने का क्या कारण है? लाभ प्रारंभिक मैपिंग से आगे तक फैलते हैं।
विकास में जाने से पहले, फ्लोस्टेट टीम ने अपने काम की पुष्टि के लिए निम्नलिखित चेकलिस्ट का उपयोग किया।
एक अवधारणा से एक कार्यात्मक उत्पाद तक संक्रमण केवल कोडिंग कौशल से अधिक चाहता है। इसके लिए आपको बना रहे सूचना पारिस्थितिकी तंत्र की गहन समझ की आवश्यकता होती है। डेटा प्रवाह के नक्शे बनाकर, फ्लोस्टेट ने डेप्लॉयमेंट से पहले उनकी वास्तुकला की ठोसता सुनिश्चित कर ली।
यह केस स्टडी यह उजागर करती है कि डेटा प्रवाह आरेख केवल एक ड्राइंग अभ्यास नहीं है। यह एक महत्वपूर्ण सोच का उपकरण है। यह टीम को डेटा के स्रोत, उसके गंतव्य और उसके परिवर्तन के बारे में कठिन सवाल पूछने के लिए मजबूर करता है। किसी भी स्टार्टअप के लिए जो एक टिकाऊ प्रणाली बनाना चाहता है, इस मॉडलिंग चरण में समय निवेश करना एक रणनीतिक लाभ है।
याद रखें, लक्ष्य पहली ड्राफ्ट में पूर्णता नहीं है। लक्ष्य स्पष्टता है। संदर्भ से शुरू करें, प्रक्रियाओं तक गहराई से जाएँ, और प्रवाहों की पुष्टि करें। इस अनुशासित दृष्टिकोण से ऐसी प्रणालियाँ बनती हैं जिन्हें बनाए रखना, सुरक्षित रखना और स्केल करना आसान होता है।
जैसे ही आप अपने स्वयं के प्रोजेक्ट मैपिंग की शुरुआत करें, इन सिद्धांतों को ध्यान में रखें। डेटा के गतिशीलता पर ध्यान केंद्रित करें, सीमाओं का सम्मान करें, और प्रत्येक संबंध की पुष्टि करें। आपका भविष्य का आप आज बनाई गई स्पष्टता के लिए आपका धन्यवाद करेगा।