 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Dans l’architecture des systèmes logiciels, peu d’éléments ont autant de poids qu’un diagramme de flux de données (DFD). Bien que les spécifications techniques et les dépôts de code soient essentiels, le DFD agit comme un traducteur universel entre la logique métier et la mise en œuvre technique. Il comble le fossé là où les exigences s’arrêtent et l’exécution commence. Lorsqu’un analyste dessine un processus, il ne se contente pas de représenter le déplacement des données ; il définit le contrat d’interaction entre les composants du système. Pour les développeurs, ce diagramme est le plan directeur qui informe la structure de la base de données, les points d’entrée d’API et la logique de traitement.
Ce guide explore l’application pratique des diagrammes de flux de données dans des contextes professionnels. Nous examinerons comment ces diagrammes agissent comme des outils de communication, les normes de notation spécifiques utilisées pour assurer la clarté, ainsi que les points de friction courants qui surviennent entre analystes et développeurs. En comprenant les mécanismes des DFD au-delà de leurs définitions théoriques, les équipes peuvent réduire l’ambiguïté et construire des systèmes alignés sur l’intention métier.
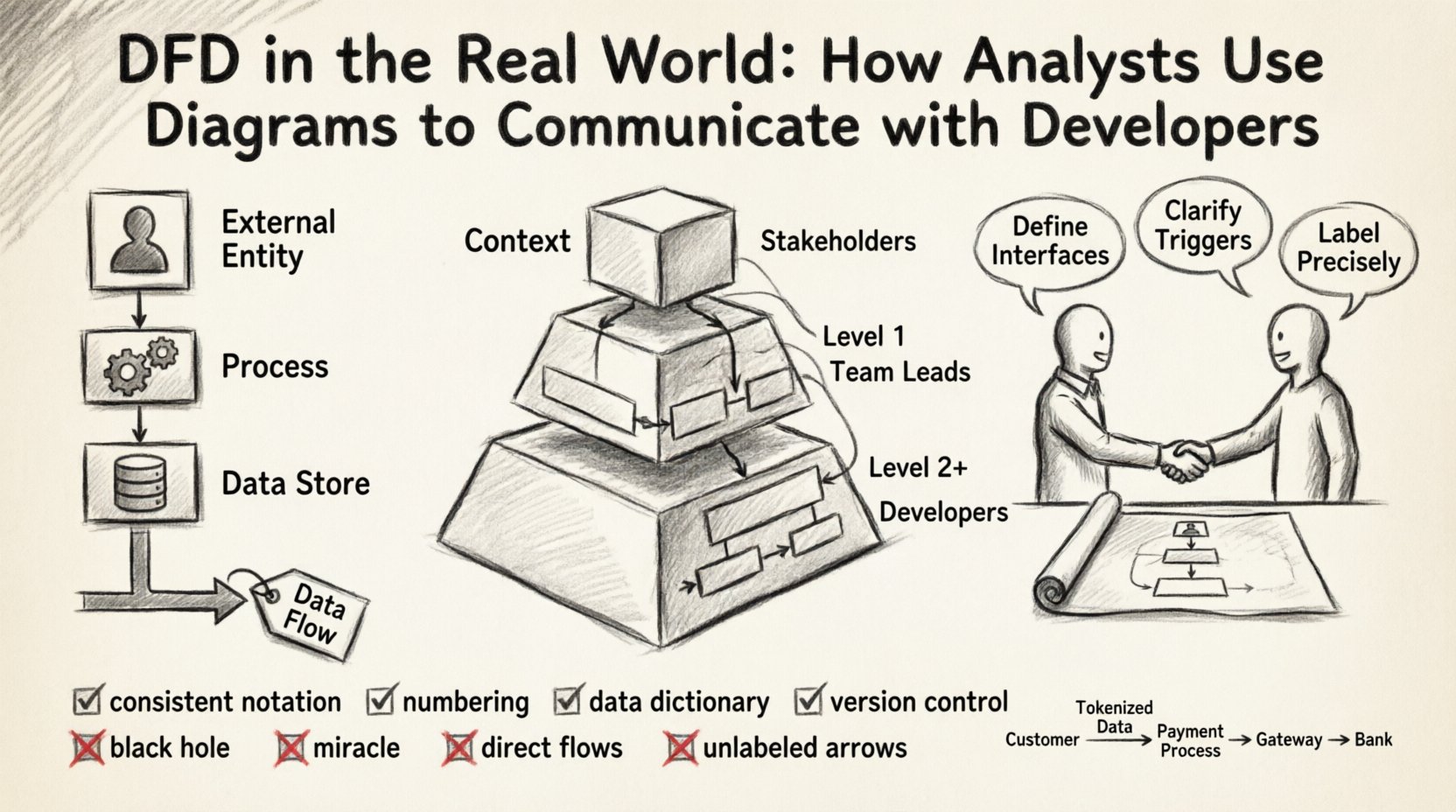
Avant de plonger dans les stratégies de collaboration, il est essentiel d’établir un vocabulaire commun. Un diagramme de flux de données est une représentation graphique du flux de données à travers un système d’information. Contrairement à un organigramme, qui illustre le flux de contrôle et la logique décisionnelle, un DFD se concentre strictement sur la transformation et le déplacement des données. Chaque élément du diagramme possède une signification sémantique précise.
Lorsque ces éléments sont combinés, ils forment une carte de l’architecture informationnelle du système. L’exactitude de cette carte dépend de la précision des étiquettes et de la cohérence logique des connexions.
Les DFD efficaces sont rarement créés en une seule étape. Ils évoluent à travers des niveaux d’abstraction, permettant aux parties prenantes de comprendre le système à différents niveaux de détail. Cette hiérarchie est cruciale pour gérer la complexité lors des transferts aux développeurs.
Il s’agit de la vue de niveau le plus élevé. Il montre le système comme un seul processus et ses interactions avec les entités externes. Il définit clairement la frontière du système. Pour un développeur, ce diagramme répond à la question : « À quoi ce système s’adresse-t-il ? » Il établit le périmètre et évite le débordement de portée en définissant visuellement ce qui est à l’intérieur et ce qui est à l’extérieur.
Ici, le processus central est décomposé en sous-processus majeurs. Ce niveau révèle la structure interne sans s’attarder sur chaque porte logique. Il est souvent le premier diagramme partagé avec les développeurs seniors pour discuter des découpages architecturaux. Il aide à identifier quels modules pourraient nécessiter d’être des services indépendants ou des tables de base de données distinctes.
Ces diagrammes descendent jusqu’à des sous-processus spécifiques. C’est là que réside la logique détaillée. Les développeurs y font souvent référence lors de l’écriture de tests unitaires ou de la mise en œuvre de règles métier spécifiques. Toutefois, une sur-documentation à ce niveau peut devenir une charge de maintenance.
| Niveau du diagramme | Public cible principal | Objectif principal | Granularité du détail |
|---|---|---|---|
| Contexte | Parties prenantes, architectes | Définir les frontières | Élevé (système comme une seule unité) |
| Niveau 1 | Chefs de projet, architectes | Identifier les modules | Moyen (sous-processus majeurs) |
| Niveau 2 et plus | Développeurs, QA | Définir la logique | Faible (transformations spécifiques des données) |
Même avec un schéma bien dessiné, les malentendus sont fréquents. L’analyste pense en termes de valeur métier et d’intégrité des données. Le développeur pense en termes de latence, de concurrence et de types de données. Le DFD est le terrain de rencontre, mais il nécessite une traduction.
Pour atténuer ces problèmes, les analystes doivent annoter les schémas avec des contraintes. Les développeurs doivent examiner les schémas pour leur faisabilité. Cette revue collaborative doit avoir lieu avant le début du codage.
Maintenir un DFD utile tout au long du cycle de développement exige de la discipline. Un schéma non mis à jour devient une charge, induit en erreur l’équipe de développement et engendre une dette technique.
Il existe deux écoles principales de notation des DFD : Yourdon/DeMarco et Gane/Sarson. Bien qu’elles diffèrent légèrement par la forme (angles arrondis vs. angles vifs pour les processus), les significations restent largement identiques. L’ensemble de l’équipe doit s’accorder sur une seule norme. Mélanger les notations au sein du même projet crée une charge cognitive et de la confusion.
Utilisez un système de numérotation hiérarchique pour les processus. Par exemple, si le processus de niveau supérieur est 0, le premier sous-processus est 1.0, et son sous-processus est 1.1. Cela permet une croisement facile. Si un développeur mentionne « Processus 3.2 », l’analyste sait immédiatement quelle partie du diagramme de niveau 1 consulter.
Un DFD ne doit jamais exister en isolation. Il doit être associé à un dictionnaire des données. Ce document définit chaque élément de données utilisé dans les flèches. Il précise le type de données, la longueur et les contraintes (par exemple, « Adresse e-mail : Chaîne de caractères, Longueur maximale 255, Unique »).
Tout comme le code, les diagrammes évoluent. Une mise à jour de fonctionnalité peut ajouter un nouveau flux de données ou modifier un processus. Ces changements doivent être suivis. Les équipes doivent conserver un historique des versions des diagrammes. Lorsqu’un développeur demande « Quand avons-nous ajouté le flux de paiement ? », l’historique des versions fournit la réponse.
Même les praticiens expérimentés commettent des erreurs. Reconnaître ces schémas tôt permet d’économiser un temps considérable pendant la phase de codage.
Cela se produit lorsque un processus a des entrées mais aucune sortie. Cela implique que des données sont créées ou consommées sans résultat. Dans un système réel, cela indique souvent une notification manquante, une exigence de journalisation ou une écriture dans la base de données oubliée.
C’est l’inverse du trou noir. Un processus a des sorties mais aucune entrée. Cela implique que les données apparaissent de nulle part. En pratique, cela signifie généralement que la source de données a été omise du diagramme, par exemple une valeur par défaut ou une horloge système.
Les données ne doivent pas circuler directement d’une entité externe à une autre sans passer par le système. Si un utilisateur envoie des données à un autre utilisateur, celles-ci doivent passer par un processus de validation et de routage. Les flux directs contournent les contrôles de sécurité et la logique métier.
Les flèches sans étiquettes sont inutiles. Elles obligent le développeur à deviner ce qui est transmis. Si un flux est étiqueté « Données », c’est trop vague. Utilisez des noms spécifiques qui décrivent le contenu.
Un DFD est un document vivant. Il doit évoluer parallèlement au logiciel. Le diagramme initial est une hypothèse sur le fonctionnement du système. Au fur et à mesure que les développeurs construisent et testent, la réalité peut différer. Le diagramme doit être mis à jour pour refléter l’implémentation réelle.
Ce processus itératif implique :
Pour illustrer l’application pratique, considérez un module de traitement des paiements. Les entités externes sont le Client, la passerelle de paiement et la Banque. Le système reçoit une « demande de paiement » du Client.
Scénario A : Communication médiocre
L’analyste dessine un processus appelé « Traiter le paiement ». Le développeur suppose que celui-ci gère directement la carte de crédit. Le schéma ne montre pas la banque. Le développeur construit une solution qui stocke les détails de la carte, violant la conformité en matière de sécurité, car le DFD n’a pas montré la nécessité de transférer vers une passerelle.
Scénario B : Communication efficace
L’analyste dessine le sous-processus « Traiter le paiement ». Il montre un flux vers la passerelle de paiement (entité externe) étiqueté « Données de carte tokenisées ». Il montre un flux de retour étiqueté « Statut de la transaction ». Le dictionnaire des données définit « Données de carte tokenisées » comme un identifiant de référence, et non des chiffres bruts. Le développeur comprend immédiatement qu’il doit utiliser une intégration par API plutôt que de construire une logique de stockage.
Le second scénario prévient une violation de sécurité. Le schéma a agi comme une contrainte, guidant le développeur vers la décision architecturale correcte.
Pour les développeurs, le DFD est un prédécesseur direct des décisions techniques. Chaque flèche représente un appel réseau, une requête de base de données ou une lecture/écriture en mémoire.
La valeur d’un diagramme de flux de données réside moins dans son aspect esthétique que dans sa capacité à réduire l’ambiguïté. Il oblige l’analyste à réfléchir d’où proviennent les données et où elles vont. Il oblige le développeur à comprendre l’intention du système avant d’écrire une seule ligne de code.
Lorsqu’il est utilisé correctement, le DFD est un partenaire silencieux dans le développement. Il ne crie pas pour attirer l’attention, mais il assure que la fondation est solide. Les équipes qui consacrent du temps à des DFD précis, maintenus et collaboratifs constateront que leurs cycles de développement sont plus fluides, avec moins de reprises et moins de malentendus. L’effort investi dans le schéma rapporte des dividendes en termes de stabilité et de maintenabilité du produit final.
En respectant les notations standard, en maintenant les dictionnaires de données et en traitant le schéma comme un artefact vivant, les organisations peuvent s’assurer que la communication entre l’analyse et l’ingénierie reste claire, précise et efficace. Cette alignement est la colonne vertébrale d’une architecture système réussie.