 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Concevoir un système d’information robuste exige bien plus que du codage ; il demande une compréhension claire de la manière dont les données circulent au sein d’un processus. Un diagramme de flux de données (DFD) sert de plan directeur à ce mouvement. Il visualise le flux d’information entre des entités externes, des processus internes et des entrepôts de données. Ce guide vous offre une exploration approfondie de la création de DFD efficaces, garantissant que votre analyse du système soit structurée, logique et évolutif.
Que vous conceviez une nouvelle application ou que vous effectuiez une revue d’une application existante, les principes du flux de données restent constants. Ce parcours couvre l’anatomie, les niveaux, les étapes de création et les bonnes pratiques nécessaires à la réalisation de schémas de qualité professionnelle, sans dépendre d’outils spécifiques. L’accent reste mis sur la méthodologie et la logique sous-jacente à la visualisation.
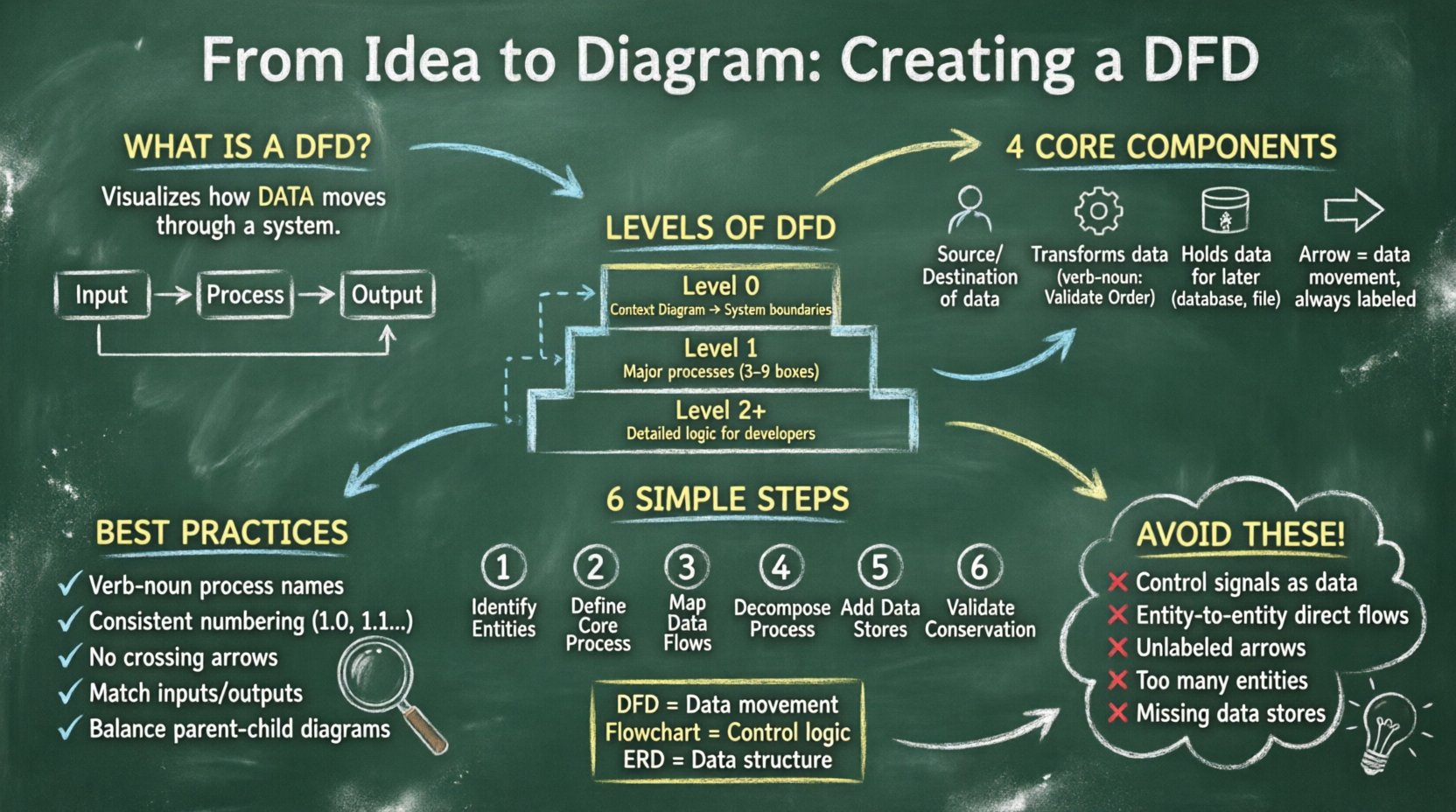
Un diagramme de flux de données est une représentation graphique du flux de données à travers un système d’information. Contrairement à un organigramme, qui se concentre sur la logique de contrôle et les étapes de prise de décision, un DFD se concentre sur les données elles-mêmes. Il répond aux questions suivantes : d’où proviennent les données ? Que leur arrive-t-il ? Où vont-elles ? Et où sont-elles stockées ?
Les DFD sont intégraux aux méthodologies d’analyse et de conception structurées. Ils aident les parties prenantes à visualiser les limites du système et à identifier les chemins de données manquants ou une complexité inutile. En décomposant les systèmes complexes en couches gérables, les analystes peuvent s’assurer que chaque élément de données a un but et une destination clairement définis.
Pour construire un DFD valide, il faut comprendre les quatre symboles fondamentaux utilisés tout au long du schéma. Ces symboles sont universels et ne changent pas, quelle que soit la notation utilisée (comme Yourdon/DeMarco ou Gane/Sarson). Maîtriser ces composants est essentiel pour une modélisation précise.
Le tableau suivant résume les interactions entre ces composants :
| Composant | Fonction | Entrée requise | Sortie requise |
|---|---|---|---|
| Entité externe | Démarre ou reçoit des données | Non | Oui (ou Non pour les puits) |
| Processus | Transforme les données | Oui | Oui |
| Entrepôt de données | Garde les données | Oui (Écriture) | Oui (Lecture) |
| Flux de données | Transporte les données | N/D | N/D |
Les systèmes complexes ne peuvent pas être décrits en une seule vue. Pour gérer la complexité, les DFD sont créés à différents niveaux de détail. Cette technique est connue sous le nom de « décomposition ». Vous commencez par un aperçu de haut niveau et décomposez progressivement les processus en sous-processus jusqu’à ce que le niveau de détail soit suffisant pour l’implémentation.
Le diagramme de contexte est le niveau d’abstraction le plus élevé. Il représente l’ensemble du système comme un seul processus et ses interactions avec les entités externes. Ce diagramme établit les limites du système. Il répond à la question : « Qu’est-ce que le système dans son ensemble ? »
Dans le diagramme Niveau 1, le processus unique du diagramme de contexte est décomposé en sous-processus majeurs. Cela révèle la structure interne du système sans s’attarder sur des détails minutieux. Il relie les grandes zones fonctionnelles aux entités externes.
Les diagrammes Niveau 2 décomposent davantage des processus spécifiques du Niveau 1. Ce processus se poursuit jusqu’à ce que les processus soient suffisamment simples pour être compris par les développeurs ou les opérateurs. Un diagramme Niveau 3 ou Niveau 4 peut être nécessaire pour des algorithmes très complexes ou des calculs financiers.
| Niveau | Focus | Complexité | Public cible principal |
|---|---|---|---|
| Diagramme de contexte | Limites du système | Faible (1 processus) | Intéressés, gestion |
| Niveau 1 | Grandes zones fonctionnelles | Moyen (3 à 9 processus) | Analystes, chefs de projet |
| Niveau 2+ | Sous-processus spécifiques | Élevé (logique détaillée) | Développeurs, programmeurs |
Créer un DFD est un processus méthodique. Il ne suffit pas de dessiner simplement des formes ; vous devez suivre une séquence logique pour garantir l’intégrité des données et la cohérence à tous les niveaux.
Commencez par lister toutes les sources et destinations des données. Ce sont les utilisateurs, d’autres systèmes ou départements qui interagissent avec votre système. Évitez de placer ici des magasins de données internes ; gardez-les séparés. Chaque entité doit avoir un nom clair, tel que « Client », « Administrateur » ou « Passerelle de paiement ». Évitez les termes vagues comme « Utilisateur » si plusieurs types d’utilisateurs existent.
Pour le diagramme de contexte, dessinez un seul cercle représentant le système. Étiquetez-le avec le nom du système. C’est votre point d’ancrage. Assurez-vous que tous les flux de données entrant et sortant de ce cercle correspondent aux entités identifiées à l’étape 1.
Dessinez des flèches reliant les entités au processus. Étiquetez chaque flèche avec les données spécifiques transférées. Au lieu d’écrire « Données », écrivez « Détails de la commande » ou « Facture ». Cette précision est cruciale pour les étapes ultérieures du développement. Assurez-vous qu’aucune flèche ne croise une autre sans point de connexion clair.
Pour créer le niveau 1, remplacez le cercle unique du système par plusieurs processus. Ces processus doivent représenter des fonctions majeures, telles que « Valider la commande », « Traiter le paiement » et « Mettre à jour le stock ». Connectez ces processus entre eux et aux entités externes en utilisant les flux de données identifiés précédemment.
Identifiez où les données doivent être sauvegardées. Si des données sont nécessaires pour un processus ultérieur ou pour des rapports, elles doivent être stockées dans un magasin de données. Connectez le magasin de données au processus qui écrit dedans et au processus qui lit dedans. Rappelez-vous qu’un processus ne peut pas écrire directement dans un autre processus ; il doit passer par un magasin si une persistance est requise.
Vérifiez chaque processus pour vous assurer que les entrées égalent les sorties. C’est le principe de conservation des données. Vous ne pouvez pas créer des données de rien, ni les supprimer sans trace. Si un processus a des entrées mais pas de sorties, c’est un « trou noir ». Si un processus a des sorties mais pas d’entrées, c’est une « miracle ». Les deux sont des erreurs dans le modèle.
Un DFD est un outil de communication. S’il est difficile à lire, il échoue à sa fonction principale. Respecter des conventions strictes aide à maintenir la clarté au sein des équipes.
Même les analystes expérimentés peuvent commettre des erreurs. Reconnaître ces erreurs courantes tôt peut éviter un travail de reprise important plus tard.
Il est fréquent de confondre les DFD avec d’autres méthodes de représentation graphique. Comprendre la différence garantit que vous utilisez l’outil approprié pour la tâche.
| Type de diagramme | Objectif | Meilleure utilisation |
|---|---|---|
| Diagramme de flux de données | Déplacement des informations | Exigences du système, Logique des processus |
| Organigramme | Logique de contrôle, Décisions | Conception d’algorithmes, Procédures étape par étape |
| Diagramme d’entité-association | Structure des données, Relations | Conception de base de données, Définition du schéma |
Alors qu’un organigramme montre l’ordre des opérations (Si X, alors Y), un DFD montre les dépendances entre les transformations des données. Un DFD ne tient pas compte de l’ordre d’exécution, mais uniquement du flux d’information. Cela rend les DFD particulièrement adaptés à l’analyse des exigences du système avant que la logique ne soit définitivement établie.
Les systèmes évoluent. Les exigences changent, et des fonctionnalités sont ajoutées. Un DFD créé au début d’un projet peut devenir obsolète. Il est essentiel de maintenir le diagramme à mesure que le système évolue.
Créer un diagramme de flux de données est une discipline qui exige de la patience et de la précision. Elle vous oblige à penser aux données, et non seulement aux fonctions. En suivant l’approche structurée décrite ci-dessus, vous assurez que le modèle obtenu est précis, maintenable et utile tout au long du cycle de vie du système.
Souvenez-vous que l’objectif n’est pas de créer une image parfaite immédiatement. Il s’agit de créer une carte qui guide l’équipe de développement. Commencez par le diagramme de contexte, validez les limites, puis descendez vers les détails. À mesure que vous pratiquerez, le processus de décomposition deviendra plus intuitif, et vos diagrammes serviront d’outil de communication puissant pour votre équipe.
Maintenez l’attention sur les données. Assurez-vous que chaque flèche a une finalité, chaque processus a une transformation, et chaque stockage a une raison d’exister. Cette approche rigoureuse conduit à des systèmes robustes, évolutifs et alignés sur les besoins métiers.