 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Créer une représentation visuelle du déplacement des informations à travers un système est une compétence fondamentale pour les analystes, les développeurs et les parties prenantes métier. Un schéma de flux de données, communément appelé DFD, remplit exactement cet objectif. Il cartographie le flux des données entre des entités externes, des processus internes et des entrepôts de données, sans nécessairement détailler la logique ou le timing spécifiques. Ce guide propose une approche structurée pour concevoir votre premier DFD de manière efficace.
Beaucoup de personnes trouvent le dessin de diagrammes intimidant, craignant qu’il nécessite des outils complexes ou beaucoup de temps. Toutefois, les principes fondamentaux de la modélisation du flux de données sont simples. Avec une compréhension claire des symboles et une approche méthodique, vous pouvez établir un diagramme fonctionnel en peu de temps. Cet article vous guide à travers les composants essentiels, le processus de construction étape par étape, ainsi que les vérifications nécessaires pour garantir l’exactitude.
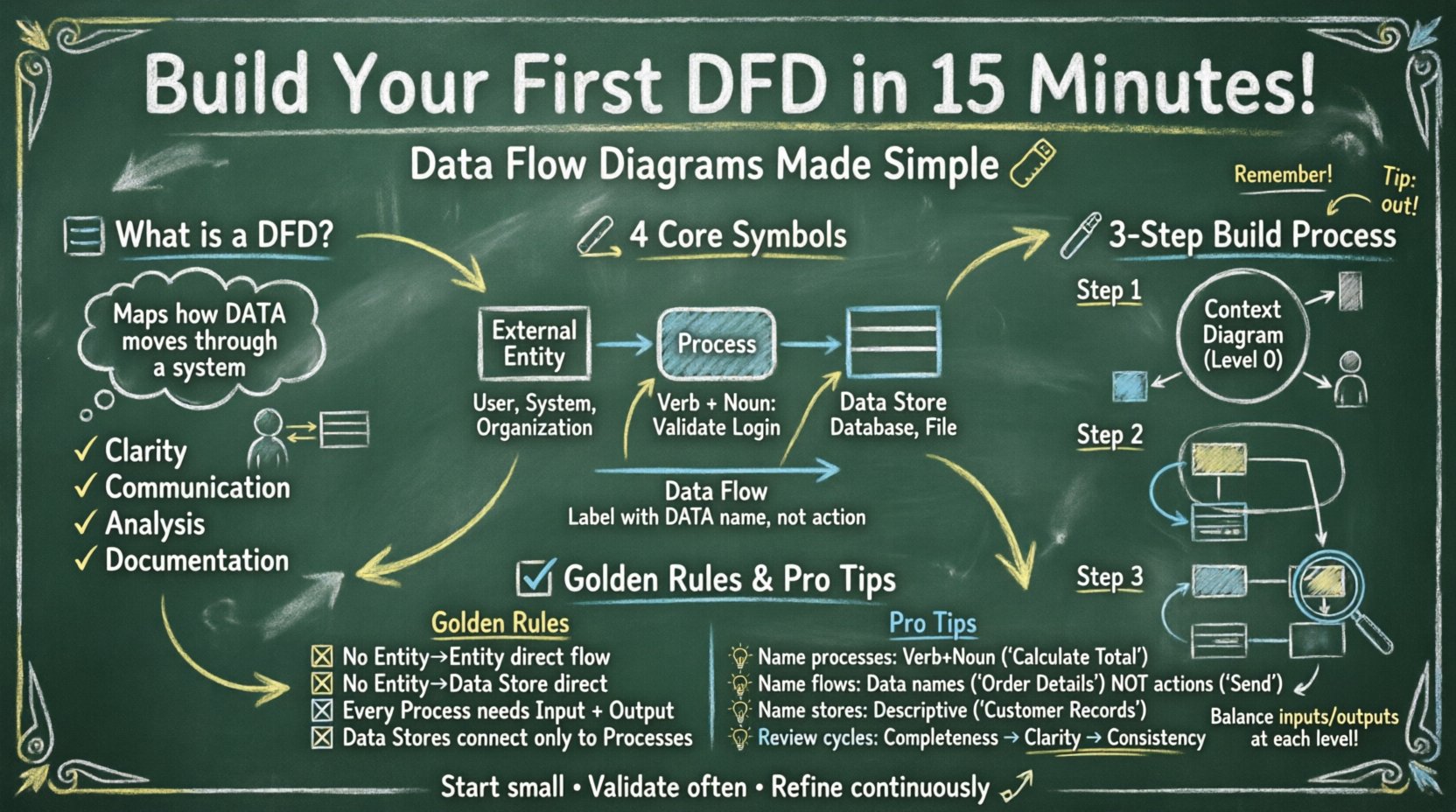
Avant de dessiner des lignes et des formes, il est important de comprendre ce qu’un DFD représente. Il s’agit d’un modèle fonctionnel. Il se concentre sur ce que le système fait plutôt que sur comment il le fait. Contrairement à un organigramme, qui suit les chemins décisionnels et les séquences logiques, un DFD suit le déplacement des paquets de données depuis une source jusqu’à une destination.
Les principaux avantages de l’utilisation de cette technique de modélisation incluent :
Lorsque vous commencez cet exercice, gardez à l’esprit l’objectif : visualiser les limites et les interactions de votre système spécifique. Vous n’avez pas besoin de logiciels avancés pour commencer. Un tableau blanc, une feuille de papier et un stylo sont des outils suffisants pour le premier brouillon.
Les DFD s’appuient sur un ensemble standardisé d’éléments graphiques. Bien qu’il existe des variations de notation (comme Yourdon/DeMarco par rapport à Gane/Sarson), les concepts fondamentaux restent constants. Voici une analyse des quatre composants principaux que vous allez rencontrer.
| Composant | Forme | Description |
|---|---|---|
| Entité externe | Rectangle ou carré | Source ou destination des données en dehors du système (par exemple, un utilisateur, un autre système). |
| Processus | Rectangle arrondi ou cercle | Transforme les données d’entrée en données de sortie. Il modifie la forme ou le contenu. |
| Magasin de données | Rectangle ou lignes parallèles ouvertes | Un dépôt où les données sont stockées (par exemple, une base de données, un classeur). |
| Flux de données | Flèche | Le chemin suivi par les données entre les composants. Il représente un déplacement, et non une action. |
Comprendre ces distinctions est essentiel. Par exemple, un processus doit avoir au moins une entrée et une sortie. Un magasin de données ne peut pas exister simplement en isolation ; il doit être connecté à un processus pour être lu ou écrit. Les entités externes existent à l’extérieur de la frontière du système, agissant comme déclencheur ou destinataire.
Pour construire votre diagramme dans le délai suggéré, suivez cette séquence logique. Cette méthode vous assure de définir les limites avant de vous plonger dans les détails.
Commencez par un Diagramme de contexte (souvent appelé Niveau 0). Il s’agit de la vue de niveau le plus élevé. Il montre le système comme un seul processus et son interaction avec le monde extérieur.
Par exemple, dans un système de bibliothèque, le « Emprunteur » est une entité. Le processus « Dépôt de livre » est le système. Le flux de données pourrait être « Demande de prêt » ou « Détails du livre ».
Une fois le contexte établi, vous devez étendre le processus central unique en sous-processus. Cela crée un Diagramme de niveau 0.
Assurez-vous que chaque flèche partant d’une entité dans le diagramme de contexte apparaît toujours dans le diagramme de niveau 0, mais qu’elle peut maintenant se connecter à des processus internes différents.
Cela conduit au Diagramme de niveau 1. Vous sélectionnez un processus du niveau 0 et le décomposez davantage.
Un diagramme est inutile s’il comporte des étiquettes ambigües. Des conventions de nommage claires évitent toute confusion lors de la revue et de la mise en œuvre.
Les noms des processus doivent suivre une structure verbe-nom. Cela clarifie l’action en cours.
Évitez les noms génériques comme « Processus 1 » sauf si vous êtes dans une phase très préliminaire de croquis. Des noms précis facilitent la compréhension.
Les flèches représentent des données, pas des actions. Étiquetez-les avec le nom du paquet de données.
Ils doivent indiquer le contenu stocké.
Après avoir établi le brouillon, examinez le diagramme selon les règles standard afin de garantir son intégrité. Un DFD valide doit respecter des contraintes logiques spécifiques.
Même les analystes expérimentés commettent des erreurs lors de la modélisation initiale. Faites attention à ces erreurs courantes :
La construction d’un DFD est rarement une activité ponctuelle. C’est un processus itératif d’affinement. Votre premier brouillon comporte probablement des lacunes ou des erreurs. C’est normal.
Cycle de révision 1 : Vérifiez la complétude. Tous les besoins utilisateurs sont-ils représentés ? Chaque source de données est-elle prise en compte ?
Cycle de revue 2 : Vérifiez la clarté. Un nouveau membre de l’équipe peut-il regarder cela et comprendre le flux sans poser de questions ?
Cycle de revue 3 : Vérifiez la cohérence. Les noms sont-ils identiques à travers les différents niveaux du schéma ? Si un flux de données est appelé « Informations client » au niveau 0, il doit rester cohérent au niveau 1, sauf s’il est divisé en attributs spécifiques.
Ne vous précipitez pas pour finaliser le schéma. Accordez du temps aux retours des parties prenantes. Leurs commentaires révèlent souvent des besoins en données ou des processus que vous aviez ignorés.
À mesure que votre système grandit, une seule page peut ne pas suffire. Vous devrez peut-être gérer plusieurs schémas. Voici comment les organiser de manière logique.
Utilisez la référence croisée. Si un processus au niveau 1 est développé au niveau 2, étiquetez le processus parent au niveau 1 avec un code de référence (par exemple, « Voir le schéma 2.3 »). Cela permet de garder les schémas gérables sans perdre de détails.
En modélisant les flux de données, vous modélisez également implicitement la sécurité des données. Bien qu’un DFD standard ne montre pas les protocoles de chiffrement ou d’authentification, il indique le déplacement des données sensibles.
Si un flux de données contient des informations personnelles identifiables (PII) ou des données financières, indiquez-le dans la légende ou les étiquettes. Par exemple, étiquetez un flux « Données de paiement chiffrées ». Cela rappelle aux développeurs qu’il faut appliquer des contrôles de sécurité spécifiques à ce canal précis.
Une fois le schéma terminé et validé, il devient un plan directeur pour le développement. Il guide la conception de la base de données, la définition des API et la mise en page de l’interface utilisateur. Il garantit que le produit final correspond aux exigences initiales.
Souvenez-vous que les outils sont secondaires par rapport à la compréhension. Que vous utilisiez un tableau blanc numérique ou un stylo et du papier, la logique reste la même. La valeur réside dans la clarté de pensée que vous apportez à la structure du système.
En suivant les étapes décrites ci-dessus, vous pouvez produire un schéma de flux de données de qualité professionnelle qui sert de référence fiable pour votre équipe de projet. Commencez petit, validez fréquemment et affinez continuellement. Cette approche rigoureuse conduit à des conceptions de systèmes solides.