 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











La méthodologie Agile promet de la flexibilité, de la réactivité et une amélioration continue. Toutefois, la réalité comporte souvent des revers. Un sprint échoué n’est pas une anomalie ; c’est un indicateur. Comprendre comment une équipe gère l’échec détermine davantage la réussite à long terme que la célébration de cycles parfaits.
Cet article examine un scénario précis où une équipe de développement a complètement manqué ses objectifs de sprint. Nous explorerons les facteurs techniques et humains impliqués, le processus de rétrospective utilisé pour diagnostiquer le problème, ainsi que les mesures concrètes prises pour restaurer la vitesse et la qualité.
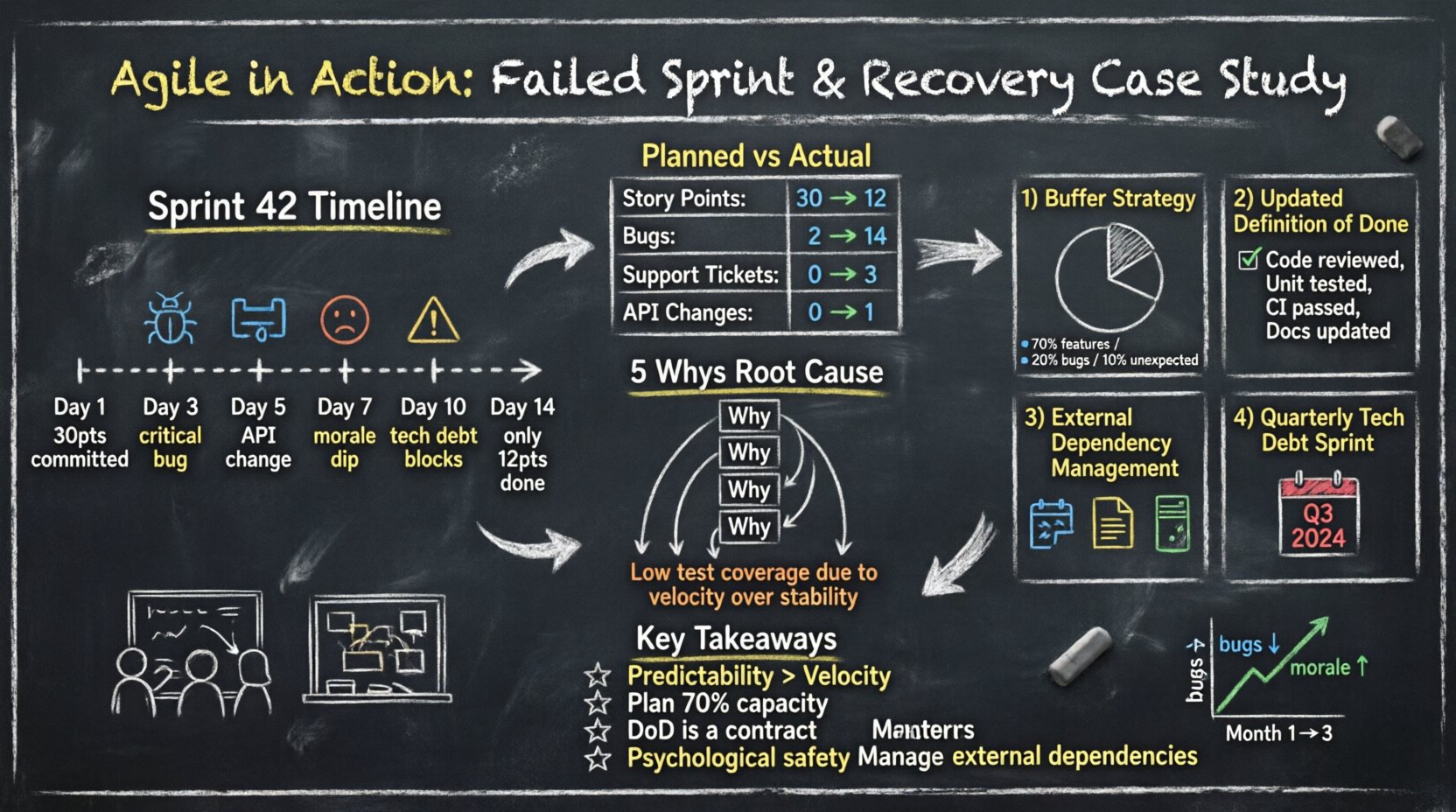
Pour comprendre l’échec, nous devons d’abord comprendre la structure. L’organisation fonctionne selon un modèle d’équipe pluridisciplinaire. Le groupe se compose de cinq développeurs, d’un product owner et d’un testeur dédié. Le travail est organisé en cycles de deux semaines.
L’équipe utilisait un tableau de suivi physique et numérique pour gérer le flux. Les histoires étaient déplacées de Backlog à En cours puis enfin à Terminé. L’objectif était une livraison constante de valeur sans compromettre la qualité du code.
Le sprint 42 a commencé avec une forte impulsion. L’équipe a tiré 30 points d’histoire depuis le backlog. Au troisième jour, le rythme semblait stable. Au cinquième jour, des frictions sont apparues. Au dixième jour, l’équipe a compris qu’elle ne terminerait pas le travail engagé.
L’échec n’était pas dû à un seul événement catastrophique. Il s’agissait d’une série cumulée de problèmes qui ont érodé la capacité.
Les chiffres racontent une histoire plus claire que les sentiments. Le tableau suivant illustre l’écart entre l’effort prévu et la livraison réelle.
| Catégorie | Prévu | Réel | Écart |
|---|---|---|---|
| Points d’histoire accomplis | 30 | 12 | -18 |
| Bugs trouvés (pendant le sprint) | 2 | 14 | +12 |
| Tickets de support traités | 0 | 3 | +3 |
| Changements de dépendances externes | 0 | 1 | +1 |
Ces données révèlent une déviation importante des ressources. Ce qui a commencé comme du travail de développement s’est transformé en maintenance et gestion de crise.
Blâmer les individus ne résout pas les problèmes systémiques. L’équipe a mené une analyse des causes profondes sans blâme afin d’identifier les problèmes fondamentaux.
Pour aller plus loin, l’équipe a appliqué la 5 pourquoi méthode au problème des délais manqués.
Le problème fondamental n’était pas la précision de la planification ; c’était la mise en œuvre de pratiques d’ingénierie durables.
Une rétrospective est le moteur de l’amélioration agile. Toutefois, un sprint échoué exige un type particulier de rétrospective. Les formats standards semblent souvent être une simple vérification de cases. Cette session a exigé un sentiment de sécurité psychologique et une enquête approfondie.
Avant la réunion, le propriétaire produit a collecté des données. L’équipe a été invitée à réfléchir individuellement à ce qui s’était bien passé et à ce qui n’avait pas fonctionné. Cela a assuré que les membres discrets aient le temps de formuler leurs idées.
L’équipe a discuté du concept de l’analyse de capacité. Ils ont réalisé qu’ils avaient engagé 100 % de leur temps sur de nouvelles fonctionnalités. Il n’y avait aucune marge de manœuvre pour les interruptions inévitables qui surviennent dans les environnements en production.
Ils ont également abordé le Définition de « fait ». Actuellement, « fait » signifiait « Code écrit ». Il ne comprenait pas « Code revu » ou « Tests écrits ». Cette divergence a créé un goulot d’étranglement à la fin de la sprint.
Connaître le problème n’est que la moitié de la bataille. La stratégie de récupération nécessitait des changements dans le flux de travail, les attentes et les normes techniques.
L’équipe a cessé de s’engager à 100 % de ses heures disponibles. Ils ont adopté une stratégie de buffer.
Ce changement a réduit la pression pour livrer des chiffres parfaits et a permis une gestion réaliste des interruptions.
L’équipe a mis à jour leur liste de vérification DoD. Une histoire ne pouvait pas passer à Terminé sans remplir ces critères :
Cela a empêché la dette technique de s’accumuler silencieusement. Cela a assuré que ce qui était livré était véritablement utilisable.
Les canaux de communication avec les fournisseurs externes ont été formalisés. L’équipe exige désormais :
L’équipe s’est accordée à consacrer un sprint par trimestre spécifiquement à la réduction de la dette technique. Cela empêche l’effet d’intérêt composé du code de mauvaise qualité. Cela signale aux parties prenantes que la stabilité est une fonctionnalité, et non une réflexion tardive.
Les changements ont été mis en œuvre immédiatement lors du sprint 43. La récupération n’a pas été instantanée, mais la trajectoire s’est modifiée.
L’équipe n’a pas cherché à revenir à l’ancienne vitesse de 30 points. Elle visait plutôt prévisibilité. Il vaut mieux s’engager sur moins et livrer de façon cohérente que de s’engager trop et échouer.
Pour assurer que la reprise soit effective, l’équipe a suivi des indicateurs précis au cours des trois prochains mois.
| Semaine | Objectif de sprint atteint | Nombre de bogues | Moral d’équipe (1-5) |
|---|---|---|---|
| Mois 1 | Oui | 12 | 3 |
| Mois 2 | Oui | 8 | 4 |
| Mois 3 | Oui | 5 | 5 |
Les données montrent une corrélation claire entre les changements de processus et la santé de l’équipe. Moins de bogues ont entraîné moins de stress, ce qui a amélioré le moral.
L’échec est un professeur. Voici les leçons tirées de cette étude de cas qui s’appliquent à tout environnement agile.
La vitesse sans stabilité est une illusion. Les équipes doivent privilégier la livraison régulière plutôt que la production brute. Les parties prenantes font confiance aux équipes qui tiennent leurs promesses, même si celles-ci sont plus modestes.
Prévoyez toujours l’imprévu. Si vous disposez de 100 heures disponibles, prévoyez 70 heures de travail. Le temps restant absorbe les frottements inévitables du développement logiciel.
La DoD n’est pas une suggestion. C’est un contrat entre l’équipe et le propriétaire produit. Si une histoire ne répond pas à la DoD, elle n’est pas prête à être livrée.
Quand les choses tournent mal, l’équipe doit se sentir en sécurité pour parler. Si les membres craignent des sanctions, ils cacheront les problèmes jusqu’à ce qu’ils deviennent des crises.
Le logiciel n’existe pas dans un vide. Les dépendances vis-à-vis des services tiers doivent être gérées avec la même rigueur que le code interne.
Beaucoup d’équipes tentent de corriger les échecs en travaillant plus dur. C’est une erreur courante. Les actions suivantes doivent être évitées pendant une période de récupération.
L’objectif de l’agilité n’est pas seulement de livrer du code, mais de construire un système capable de livrer du code indéfiniment. Le rythme durable est la fondation de ce système.
Après la récupération, l’équipe a établi un rythme d’amélioration continue. Toutes les deux semaines, ils examinent non seulement le sprint, mais aussi l’état du flux de travail. Ils se posent des questions comme :
Cette surveillance continue empêche les petits problèmes de devenir à nouveau de grandes erreurs.
La transparence vis-à-vis des parties prenantes est cruciale. Lorsqu’un sprint échoue, communiquez tôt. Expliquez l’impact, la cause et le plan. Cela renforce la confiance.
Les parties prenantes considèrent souvent un sprint échoué comme une preuve d’incompétence. Lorsqu’il est expliqué comme un point de données pour l’amélioration, cela devient une preuve de maturité professionnelle. Elles préfèrent une équipe qui reconnaît un problème et le corrige à une équipe qui le cache.
Les échecs sont normaux. Un taux d’échec de 10 % est souvent acceptable selon le domaine. Des taux élevés constants indiquent un problème systémique de planification.
Généralement, non. Arrêter un sprint perd le temps déjà investi. Il est préférable de terminer ce qui peut l’être et de recommencer pour le cycle suivant.
Oui, si votre vitesse est artificiellement gonflée par un engagement excessif. La réduire pour correspondre à la réalité améliore la précision et la prévisibilité.
Des solutions temporaires sont possibles, mais une récupération à long terme nécessite un changement de processus. Autrement, l’échec se reproduira.
L’Agile est un parcours d’adaptation. Un sprint échoué n’est pas la fin de la route ; c’est un panneau indiquant la voie vers de meilleures pratiques. En analysant profondément l’échec et en mettant en œuvre des changements structurels, les équipes peuvent ressortir plus fortes et plus résilientes.