 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Dans les premières étapes de la création d’une entreprise technologique, la clarté est une monnaie. Les fondateurs plongent souvent directement dans la programmation sans avoir pleinement visualisé le mouvement des données sous-jacent. Cette approche conduit fréquemment à des dettes techniques et à des sessions de débogage complexes plus tard. Un diagramme de flux de données (DFD) offre une méthode structurée pour visualiser le déplacement de l’information à travers un système. Ce guide explore un scénario réel où une start-up a utilisé cette méthodologie pour clarifier son architecture avant d’écrire une seule ligne de code.
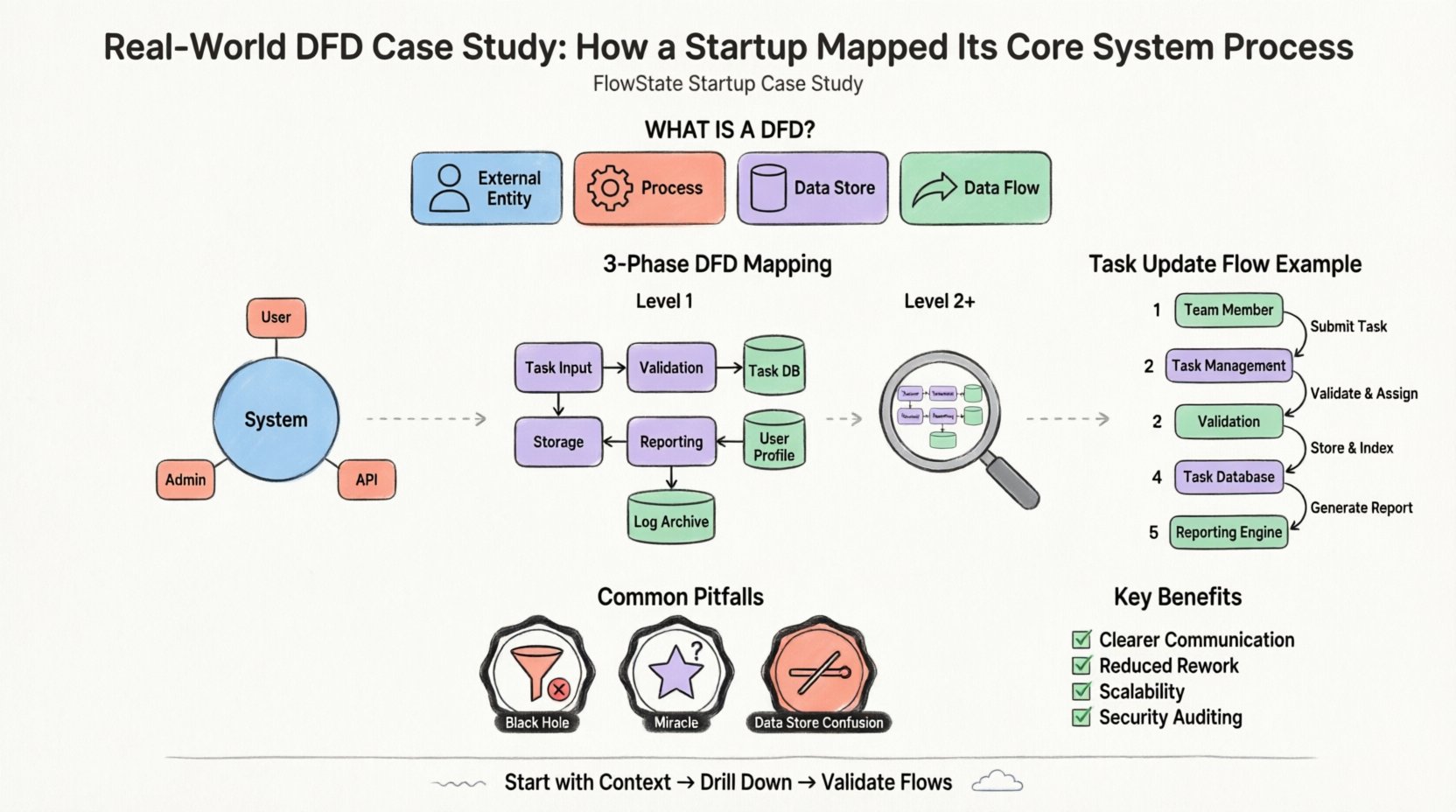
Prenons une start-up hypothétique nommée « FlowState », dont l’objectif est de créer une plateforme de gestion de projets pour les équipes à distance. La proposition de valeur centrale repose sur l’affectation des tâches, les mises à jour d’état en temps réel et les rapports automatisés. L’équipe fondatrice faisait face à un problème courant : elle avait une compréhension floue de la manière dont les données des utilisateurs devaient circuler de l’interface vers la base de données et inversement.
Sans une carte claire, l’équipe de développement risquait :
La solution n’était pas d’avoir plus de réunions, mais une modélisation plus efficace. Ils ont adopté la méthode des diagrammes de flux de données pour documenter la logique du système. Cette approche leur a permis de voir le système comme une série de transformations plutôt que comme une base de données statique.
Un diagramme de flux de données est une représentation graphique du déplacement des données à travers un système d’information. Il ne montre pas le moment des processus ni la logique de prise de décision (comme un algorithme), mais plutôt le déplacement des données depuis une origine jusqu’à une destination. Il se concentre sur le quoi, pas sur le comment.
Les composants standards utilisés dans cette technique de modélisation incluent :
En décomposant le projet FlowState en ces composants, l’équipe a pu identifier les goulets d’étranglement et garantir l’intégrité des données avant la mise en œuvre.
La première étape de la cartographie du système est le diagramme de contexte. Il s’agit d’une vue d’ensemble qui définit la frontière du système. Il montre le système comme un seul processus et explique comment il interagit avec les entités externes.
Pour FlowState, la frontière est l’application de gestion de projet elle-même. Tout ce qui est à l’intérieur fait partie du système ; tout ce qui est à l’extérieur est une entité. L’équipe a identifié trois entités externes principales :
L’équipe a dessiné des flèches pour représenter les flux d’entrée et de sortie. Par exemple :
Ce seul diagramme a clarifié le périmètre. Il a empêché l’équipe d’inclure accidentellement des fonctionnalités comme « Traitement de facturation » si ce n’était pas fait partie du système central à ce moment-là. Il a établi un contrat clair entre le système et ses utilisateurs.
Une fois le contexte de haut niveau établi, l’équipe a eu besoin de comprendre le fonctionnement interne. Cela est réalisé grâce à la décomposition au niveau 1. Le processus unique du diagramme de contexte est décomposé en sous-processus.
Le « système FlowState » a été divisé en groupes fonctionnels logiques. L’équipe a identifié les processus clés suivants :
Crucialement, le diagramme de niveau 1 a introduit des magasins de données. Cela montre où les informations sont persistées. L’équipe a identifié trois magasins principaux :
En nommant explicitement ces magasins, les développeurs pouvaient immédiatement voir quelles données devaient être écrites dans la base de données plutôt que conservées en mémoire temporaire.
Avec la structure de niveau 1 en place, l’équipe a examiné les données spécifiques qui circulent entre les processus et les magasins. Cette étape est souvent celle où les erreurs sont détectées tôt.
Analysons le déplacement d’un seul point de données : un « changement d’état de tâche ».
Cette analyse a révélé un problème potentiel. L’équipe s’est rendu compte que le « Moteur de reporting » était déclenché manuellement chaque fois qu’une tâche était modifiée. Ils ont décidé d’optimiser cela en ne déclenchant le processus de rapport que lorsque le drapeau spécifique « État = Terminé » était défini, réduisant ainsi la charge du système.
Comprendre la différence entre les niveaux de diagrammes est essentiel pour maintenir la clarté au fur et à mesure que le projet évolue. Le tableau ci-dessous décrit les distinctions.
| Niveau | Objectif | Meilleure utilisation |
|---|---|---|
| Contexte (niveau 0) | Frontière du système | Communication de haut niveau avec les parties prenantes |
| Niveau 1 | Processus majeurs | Planification architecturale et définition du périmètre |
| Niveau 2+ | Détail des sous-processus | Logique spécifique d’implémentation et débogage |
Même avec une méthodologie claire, les équipes commettent souvent des erreurs lors de la création de ces diagrammes. L’équipe FlowState a rencontré plusieurs obstacles et a appris à les éviter.
Un processus qui a une entrée mais aucune sortie est un trou noir. Les données entrent et disparaissent. Dans le premier brouillon, le « gestionnaire de notifications » recevait des données mais n’avait aucune flèche sortante vers l’entité externe. L’équipe s’est rendu compte qu’elle avait oublié de définir le mécanisme d’envoi réel. Chaque processus doit avoir une sortie.
Un processus qui a une sortie mais aucune entrée est un miracle. Cela implique que les données sont créées à partir de rien. L’équipe avait initialement un processus « Générer un rapport » qui produisait des données sans lire dans la « base de données des tâches ». Elle a corrigé cela en ajoutant un flux de données depuis le stockage vers le processus.
Les processus interagissent avec les magasins de données, mais les entités non. Au début, l’équipe a tracé une ligne directement depuis le « membre d’équipe » jusqu’à la « base de données des tâches ». Cela viole la règle selon laquelle les données doivent passer par un processus pour être transformées ou validées. Toutes les données qui touchent un magasin doivent passer par un processus en premier.
L’une des règles les plus importantes dans la méthodologie DFD est l’équilibrage. Les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties de son diagramme enfant (la décomposition).
Pour FlowState, le processus « Gestion des tâches » dans le diagramme de niveau 1 avait des entrées spécifiques (données de tâche) et des sorties (mise à jour de statut). Lorsqu’ils l’ont décomposé en diagrammes de niveau 2 (par exemple, « Créer une tâche », « Supprimer une tâche »), ils ont veillé à ce que les flux combinés correspondent toujours au parent. Cela garantit qu’aucune donnée n’est perdue ou créée lors de la décomposition.
Pourquoi investir du temps dans cette phase de documentation ? Les bénéfices vont au-delà du simple cartographie initiale.
Avant de passer au développement, l’équipe FlowState a utilisé la liste de contrôle suivante pour valider son travail.
Le passage d’un concept à un produit fonctionnel exige plus que des compétences en programmation. Il exige une compréhension approfondie de l’écosystème d’information que vous construisez. En cartographiant les flux de données, FlowState a assuré que son architecture était solide avant le déploiement.
Cette étude de cas met en évidence que le diagramme de flux de données n’est pas simplement un exercice de dessin. C’est un outil de réflexion critique. Il oblige l’équipe à se poser des questions difficiles sur l’origine des données, leur destination et leur transformation. Pour toute startup visant à construire un système robuste, consacrer du temps à cette phase de modélisation constitue un avantage stratégique.
Souvenez-vous, l’objectif n’est pas la perfection dans le premier jet. L’objectif est la clarté. Commencez par le contexte, descendez jusqu’aux processus, puis validez les flux. Cette approche rigoureuse conduit à des systèmes plus faciles à maintenir, sécurisés et évolutifs.
Lorsque vous commencerez votre propre cartographie de projet, gardez ces principes à l’esprit. Concentrez-vous sur le déplacement des données, respectez les limites et validez chaque connexion. Votre futur vous remerciera pour la clarté établie aujourd’hui.