 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











La metodología Ágil promete flexibilidad, capacidad de respuesta y mejora continua. Sin embargo, la realidad a menudo incluye contratiempos. Un sprint fallido no es una anomalía; es un dato. Comprender cómo una equipo maneja el fracaso determina el éxito a largo plazo más que celebrar ciclos perfectos.
Este artículo examina un escenario específico en el que un equipo de desarrollo no cumplió sus objetivos de sprint en absoluto. Exploraremos los factores técnicos y humanos involucrados, el proceso de retrospectiva utilizado para diagnosticar el problema y las medidas concretas tomadas para restablecer la velocidad y la calidad.
Para entender el fracaso, primero debemos comprender la estructura. La organización opera con un modelo de equipo multifuncional. El grupo está compuesto por cinco desarrolladores, un propietario de producto y un tester dedicado. El trabajo se organiza en ciclos de dos semanas.
El equipo utilizó una pizarra física y digital para gestionar el flujo. Las historias se movieron desde Backlog a En progreso y finalmente a Hecho. El objetivo era la entrega constante de valor sin comprometer la calidad del código.
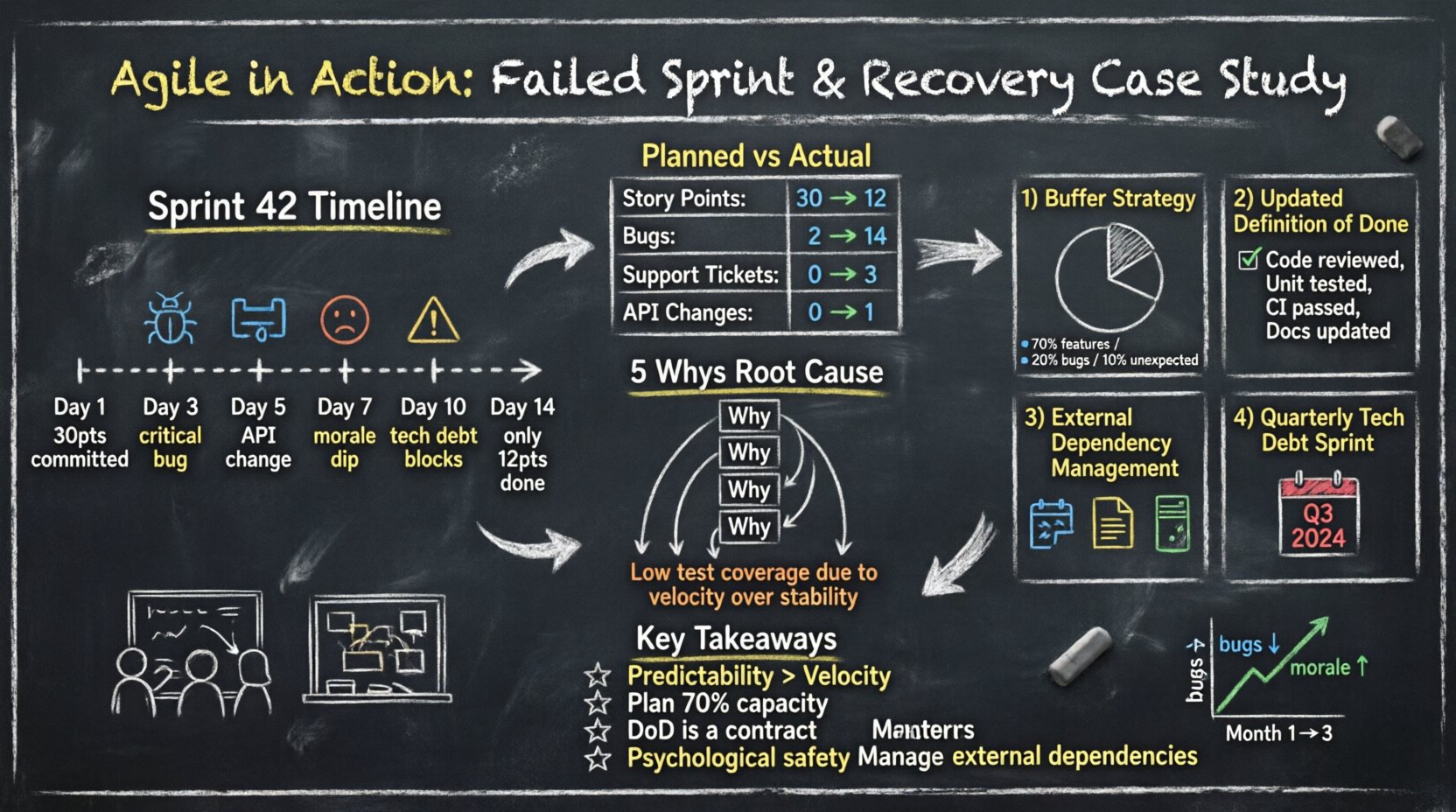
El sprint 42 comenzó con gran impulso. El equipo sacó 30 puntos de historia del backlog. Al tercer día, el ritmo parecía estable. Al quinto día, aparecieron fricciones. Al décimo día, el equipo se dio cuenta de que no completaría el trabajo comprometido.
El fracaso no se debió a un único evento catastrófico. Fue una serie acumulativa de problemas que erosionaron la capacidad.
Los números cuentan una historia más clara que las emociones. La siguiente tabla ilustra la diferencia entre el esfuerzo planeado y la entrega real.
| Categoría | Planeado | Real | Diferencia |
|---|---|---|---|
| Puntos de historia completados | 30 | 12 | -18 |
| Errores encontrados (durante el sprint) | 2 | 14 | +12 |
| Tickets de soporte atendidos | 0 | 3 | +3 |
| Cambios en dependencias externas | 0 | 1 | +1 |
Esta data revela una desviación significativa de recursos. Lo que comenzó como trabajo de desarrollo se convirtió en mantenimiento y gestión de crisis.
Responsabilizar a individuos no resuelve problemas sistémicos. El equipo realizó un análisis de la causa raíz sin culpar a nadie para identificar los problemas subyacentes.
Para profundizar más, el equipo aplicó latécnica de los 5 Porqués al problema de los plazos incumplidos.
El problema central no fue la precisión en la planificación; fue la práctica sostenible de ingeniería.
Una retrospectiva es el motor de la mejora ágil. Sin embargo, una iteración fallida requiere un tipo específico de retrospectiva. Los formatos estándar a menudo se sienten como una tarea mecánica. Esta sesión requirió seguridad psicológica e indagación profunda.
Antes de la reunión, el dueño del producto recopiló datos. Se pidió al equipo que reflexionara individualmente sobre lo que salió bien y lo que no. Esto aseguró que los miembros más reservados tuvieran tiempo para formular sus ideas.
El equipo discutió el concepto de planificación de capacidad. Se dieron cuenta de que habían comprometido el 100 % de su tiempo con nuevas funcionalidades. No había ningún margen para las interrupciones inevitables que ocurren en entornos en producción.
También abordaron el Definición de Terminado. Actualmente, ‘Terminado’ significaba ‘Código escrito’. No incluía ‘Código revisado’ ni ‘Pruebas escritas’. Esta discrepancia causó un cuello de botella al final de la iteración.
Conocer el problema es solo la mitad de la batalla. El plan de recuperación requería cambios en el flujo de trabajo, las expectativas y los estándares técnicos.
El equipo dejó de comprometer el 100 % de sus horas disponibles. Adoptaron una estrategia de buffer.
Este cambio redujo la presión de entregar números perfectos y permitió un manejo realista de las interrupciones.
El equipo actualizó su lista de verificación de DoD. Una historia no podía avanzar a Hecho sin cumplir estos criterios:
Esto evitó que la deuda técnica se acumulara en silencio. Garantizó que lo entregado fuera realmente usable.
Los canales de comunicación con los proveedores externos fueron formalizados. El equipo ahora requiere:
El equipo acordó dedicar un sprint cada trimestre específicamente a la reducción de la deuda técnica. Esto evita el efecto de interés compuesto del código de mala calidad. Envía un mensaje a los interesados de que la estabilidad es una característica, no una consideración posterior.
Los cambios se implementaron de inmediato en el Sprint 43. La recuperación no fue instantánea, pero la trayectoria cambió.
El equipo no buscó volver a la antigua velocidad de 30 puntos. Buscaron previsibilidad. Es mejor comprometerse con menos y entregar de forma consistente que comprometerse demasiado y fallar.
Para asegurar que la recuperación se mantuviera, el equipo monitoreó métricas específicas durante los próximos tres meses.
| Semana | Objetivo de Sprint Cumplido | Cantidad de Errores | Morale del Equipo (1-5) |
|---|---|---|---|
| Mes 1 | Sí | 12 | 3 |
| Mes 2 | Sí | 8 | 4 |
| Mes 3 | Sí | 5 | 5 |
Los datos muestran una clara correlación entre los cambios en el proceso y la salud del equipo. Menos errores llevaron a menos estrés, lo que mejoró el estado anímico.
El fracaso es un maestro. Aquí tienes las lecciones aprendidas de este estudio de caso que se aplican a cualquier entorno ágil.
La velocidad sin estabilidad es una ilusión. Los equipos deben priorizar la entrega consistente sobre la producción bruta. Los interesados confían en los equipos que cumplen sus promesas, incluso si esas promesas son más pequeñas.
Siempre planifica para lo inesperado. Si tienes 100 horas disponibles, planifica para 70 horas de trabajo. El tiempo restante absorbe la fricción inevitable del desarrollo de software.
La DoD no es una sugerencia. Es un contrato entre el equipo y el propietario del producto. Si una historia no cumple con la DoD, no está lista para su lanzamiento.
Cuando las cosas salen mal, el equipo debe sentirse seguro para hablar. Si los miembros temen sanciones, ocultarán los problemas hasta que se conviertan en crisis.
El software no existe en el vacío. Las dependencias con servicios de terceros deben gestionarse con la misma rigurosidad que el código interno.
Muchos equipos intentan corregir el fracaso trabajando más duro. Este es un error común. Las siguientes acciones deben evitarse durante un período de recuperación.
El objetivo del ágil no es solo entregar código, sino construir un sistema que pueda entregar código indefinidamente. El ritmo sostenible es la base de este sistema.
Después de la recuperación, el equipo estableció unritmo de mejora continua. Cada dos semanas, revisan no solo el sprint, sino también la salud del flujo de trabajo. Se hacen preguntas como:
Esta supervisión continua evita que problemas pequeños se conviertan nuevamente en grandes fracasos.
La transparencia con los interesados es crucial. Cuando un sprint falla, comunica temprano. Explica el impacto, la causa y el plan. Esto genera confianza.
Los interesados a menudo ven un sprint fallido como incompetencia. Cuando se explica como un punto de datos para la mejora, se convierte en una demostración de madurez profesional. Prefieren un equipo que reconoce un problema y lo corrige antes que un equipo que oculta el problema.
Los fracasos son normales. Una tasa de error del 10% es a menudo aceptable, dependiendo del dominio. Tasas altas y constantes de fracaso indican un problema sistémico en la planificación.
Normalmente, no. Detener un sprint desperdicia el tiempo ya invertido. Es mejor terminar lo que se pueda y reiniciar para el siguiente ciclo.
Sí, si tu velocidad está artificialmente inflada por compromisos excesivos. Reducirla para que coincida con la realidad mejora la precisión y la previsibilidad.
Es posible realizar soluciones a corto plazo, pero la recuperación a largo plazo requiere un cambio en el proceso. De lo contrario, el fracaso se repetirá.
Ágil es un viaje de adaptación. Un sprint fallido no es el final del camino; es una señal que apunta hacia mejores prácticas. Al analizar profundamente el fracaso e implementar cambios estructurales, los equipos pueden salir más fuertes y resilientes.