 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











En las primeras etapas de la creación de una empresa tecnológica, la claridad es moneda corriente. Los fundadores a menudo se lanzan directamente a la codificación sin visualizar completamente el movimiento subyacente de los datos. Este enfoque con frecuencia conduce a deuda técnica y sesiones complejas de depuración más adelante. Un Diagrama de Flujo de Datos (DFD) ofrece un método estructurado para visualizar cómo la información se mueve a través de un sistema. Esta guía explora un escenario del mundo real en el que una startup utilizó esta metodología para aclarar su arquitectura antes de escribir una sola línea de código.
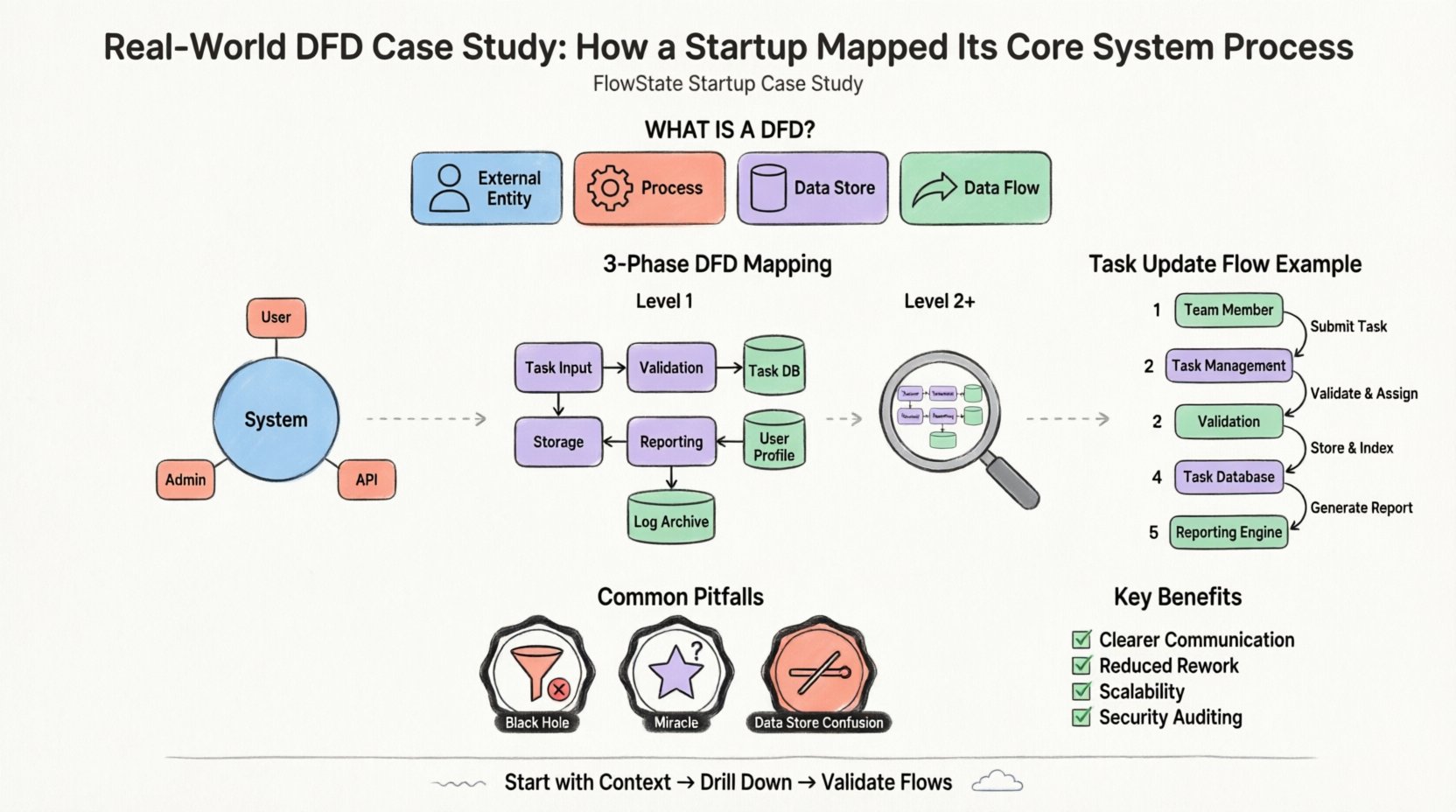
Considere una startup hipotética llamada «FlowState», que tiene como objetivo crear una plataforma de gestión de proyectos para equipos remotos. La propuesta de valor central implica la asignación de tareas, actualizaciones de estado en tiempo real y generación automatizada de informes. El equipo fundador enfrentó un problema común: tenían una comprensión vaga de cómo los datos de los usuarios deberían viajar desde la interfaz hasta la base de datos y viceversa.
Sin un mapa claro, el equipo de desarrollo corría el riesgo de:
La solución no fue tener más reuniones, sino una mejor modelización. Adoptaron el método de Diagrama de Flujo de Datos para documentar la lógica del sistema. Este enfoque les permitió ver el sistema como una serie de transformaciones en lugar de una base de datos estática.
Un Diagrama de Flujo de Datos es una representación gráfica del flujo de datos a través de un sistema de información. No muestra el tiempo de los procesos ni la lógica de la toma de decisiones (como un algoritmo), sino más bien el movimiento de datos desde un origen hasta un destino. Se enfoca en el qué, no en el cómo.
Los componentes estándar utilizados en esta técnica de modelado incluyen:
Al descomponer el proyecto FlowState en estos componentes, el equipo pudo identificar cuellos de botella y garantizar la integridad de los datos antes de la implementación.
El primer paso en el mapeo del sistema es el diagrama de contexto. Se trata de una vista de alto nivel que define el límite del sistema. Muestra el sistema como un único proceso y cómo interactúa con entidades externas.
Para FlowState, el límite es la propia aplicación de gestión de proyectos. Todo lo que está dentro forma parte del sistema; todo lo que está fuera es una entidad. El equipo identificó tres entidades externas principales:
El equipo dibujó flechas para representar los flujos de entrada y salida. Por ejemplo:
Este único diagrama aclaró el alcance. Evitó que el equipo incluyera accidentalmente funciones como «Procesamiento de facturación» si esa no formaba parte del sistema principal en ese momento. Estableció un contrato claro entre el sistema y sus usuarios.
Una vez establecido el contexto de alto nivel, el equipo necesitaba comprender el funcionamiento interno. Esto se logra mediante la descomposición de nivel 1. El proceso único del diagrama de contexto se descompone en subprocesos.
El «Sistema FlowState» se dividió en grupos funcionales lógicos. El equipo identificó los siguientes procesos clave:
Crucialmente, el diagrama de nivel 1 introdujo almacenes de datos. Esto muestra dónde se persiste la información. El equipo identificó tres almacenes principales:
Al nombrar explícitamente estos almacenes, los desarrolladores pudieron ver de inmediato qué datos debían escribirse en la base de datos frente a los que se debían mantener en memoria temporal.
Con la estructura de nivel 1 establecida, el equipo revisó los datos específicos que fluyen entre procesos y almacenes. Este paso es a menudo donde se detectan errores temprano.
Tracemos el movimiento de un solo punto de datos: un “cambio de estado de tarea”.
Esta traza reveló un problema potencial. El equipo se dio cuenta de que el “motor de informes” se activaba manualmente cada vez que cambiaba una tarea. Decidieron optimizar esto activando el proceso de informe solo cuando se estableciera una bandera específica “Estado = Completado”, reduciendo así la carga del sistema.
Comprender la diferencia entre los niveles de diagramas es vital para mantener la claridad a medida que el proyecto crece. La tabla a continuación describe las diferencias.
| Nivel | Enfoque | Mejor utilizado para |
|---|---|---|
| Contexto (nivel 0) | Límite del sistema | Comunicación de alto nivel con los interesados |
| Nivel 1 | Procesos principales | Planificación arquitectónica y definición de alcance |
| Nivel 2+ | Detalles del subproceso | Lógica específica de implementación y depuración |
Aunque se cuente con una metodología clara, los equipos a menudo cometen errores al crear estos diagramas. El equipo de FlowState se encontró con varias dificultades y aprendió a evitarlas.
Un proceso que tiene entrada pero no salida es un agujero negro. Los datos entran y desaparecen. En el primer borrador, el “Manejador de notificaciones” recibió datos pero no tenía ninguna flecha que saliera hacia la entidad externa. El equipo se dio cuenta de que había olvidado definir el mecanismo real de envío. Todo proceso debe tener una salida.
Un proceso que tiene salida pero no entrada es un milagro. Implica que los datos se crean de la nada. Inicialmente, el equipo tenía un proceso “Generar informe” que producía datos sin leer desde la “Base de datos de tareas”. Lo corrigieron añadiendo un flujo de datos desde el almacén hasta el proceso.
Los procesos interactúan con almacenes de datos, pero las entidades no. Al principio, el equipo dibujó una línea directamente desde el “Miembro del equipo” hasta la “Base de datos de tareas”. Esto viola la regla de que los datos deben pasar por un proceso para ser transformados o validados. Todos los datos que toquen un almacén deben pasar primero por un proceso.
Una de las reglas más críticas en la metodología DFD es el equilibrio. Las entradas y salidas de un proceso padre deben coincidir con las entradas y salidas de su diagrama hijo (la descomposición).
Para FlowState, el proceso “Gestión de tareas” en el diagrama de Nivel 1 tenía entradas específicas (datos de tarea) y salidas (actualización de estado). Cuando lo descompusieron en diagramas de Nivel 2 (por ejemplo, “Crear tarea”, “Eliminar tarea”), aseguraron que los flujos combinados aún coincidieran con el padre. Esto garantiza que no se pierda ni se cree ningún dato durante la descomposición.
¿Por qué invertir tiempo en esta fase de documentación? Los beneficios van más allá del mapeo inicial.
Antes de pasar a desarrollo, el equipo de FlowState utilizó la siguiente lista de verificación para validar su trabajo.
La transición de un concepto a un producto funcional requiere más que habilidades de programación. Requiere una comprensión profunda del ecosistema de información que estás construyendo. Al mapear los flujos de datos, FlowState aseguró que su arquitectura fuera sólida antes del despliegue.
Este estudio de caso destaca que un diagrama de flujo de datos no es solo un ejercicio de dibujo. Es una herramienta de pensamiento crítico. Obliga al equipo a hacer preguntas difíciles sobre de dónde proviene la data, a dónde va y cómo cambia. Para cualquier startup que aspire a construir un sistema robusto, invertir tiempo en esta fase de modelado es una ventaja estratégica.
Recuerda, el objetivo no es la perfección en el primer borrador. El objetivo es la claridad. Comienza con el contexto, profundiza en los procesos y valida los flujos. Este enfoque disciplinado conduce a sistemas más fáciles de mantener, seguros y escalables.
Al comenzar el mapeo de tu propio proyecto, ten en cuenta estos principios. Enfócate en el movimiento de los datos, respeta los límites y valida cada conexión. Tu yo futuro te lo agradecerá por la claridad establecida hoy.