 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Die Gestaltung eines robusten Informationssystems erfordert mehr als nur Programmieren; es erfordert ein klares Verständnis dafür, wie Daten durch einen Prozess fließen. Ein Datenflussdiagramm (DFD) dient als Bauplan für diesen Fluss. Es visualisiert den Informationsfluss zwischen externen Entitäten, internen Prozessen und Datenspeichern. Diese Anleitung bietet einen tiefen Einblick in die Erstellung wirksamer DFDs und stellt sicher, dass Ihre Systemanalyse strukturiert, logisch und skalierbar ist.
Unabhängig davon, ob Sie eine neue Anwendung entwerfen oder eine bestehende überprüfen, bleiben die Prinzipien des Datenflusses konstant. Diese Anleitung behandelt die Anatomie, Ebenen, Erstellungsstufen und bewährte Praktiken, die erforderlich sind, um professionelle Diagramme zu erstellen, ohne auf spezifische Werkzeuge angewiesen zu sein. Der Fokus bleibt auf der Methodik und der Logik hinter der Visualisierung.
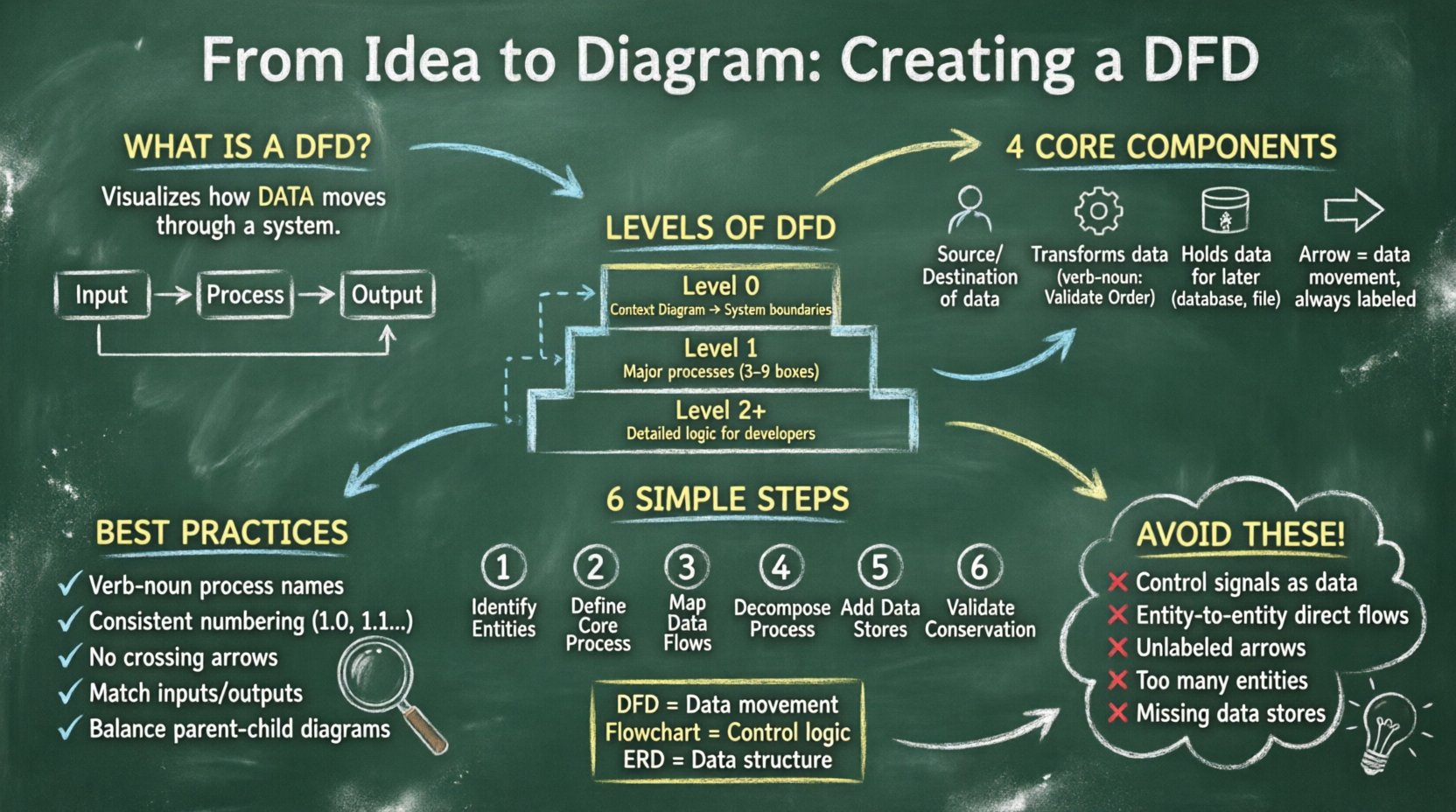
Ein Datenflussdiagramm ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Im Gegensatz zu einem Flussdiagramm, das sich auf die Steuerlogik und Entscheidungsschritte konzentriert, fokussiert ein DFD auf die Daten selbst. Es beantwortet die Fragen: Woher stammen die Daten? Was geschieht mit ihnen? Wohin gehen sie? Und wo werden sie gespeichert?
DFDs sind integraler Bestandteil strukturierter Analyse- und Entwurfsmethodologien. Sie helfen den Beteiligten, die Systemgrenzen zu visualisieren und fehlende Datenpfade oder unnötige Komplexität zu erkennen. Durch die Aufteilung komplexer Systeme in handhabbare Schichten können Analysten sicherstellen, dass jeder Datenbestand einen definierten Zweck und eine definierte Zielrichtung hat.
Um ein gültiges DFD zu erstellen, muss man die vier grundlegenden Symbole verstehen, die im gesamten Diagramm verwendet werden. Diese Symbole sind universell und ändern sich nicht, unabhängig von der verwendeten Notationsweise (z. B. Yourdon/DeMarco oder Gane/Sarson). Die Beherrschung dieser Komponenten ist entscheidend für eine genaue Modellierung.
Die folgende Tabelle fasst die Wechselwirkung zwischen diesen Komponenten zusammen:
| Komponente | Funktion | Eingabe erforderlich | Ausgabe erforderlich |
|---|---|---|---|
| Externe Entität | Beginnt mit oder empfängt Daten | Nein | Ja (oder Nein für Senken) |
| Prozess | Transformiert Daten | Ja | Ja |
| Datenspeicher | Behält Daten bei | Ja (Schreiben) | Ja (Lesen) |
| Datenfluss | Transportiert Daten | N/V | N/V |
Komplexe Systeme können nicht in einer einzigen Ansicht beschrieben werden. Um die Komplexität zu verwalten, werden DFDs auf verschiedenen Detailstufen erstellt. Diese Technik wird als „Zerlegung“ bezeichnet. Sie beginnen mit einer hochwertigen Übersicht und zerlegen die Prozesse schrittweise in Teilprozesse, bis das Detail ausreicht, um die Implementierung vorzunehmen.
Das Kontextdiagramm ist die höchste Abstraktionsstufe. Es zeigt das gesamte System als einen einzigen Prozess und dessen Interaktion mit externen Entitäten. Dieses Diagramm legt die Grenzen des Systems fest. Es beantwortet die Frage: „Was ist das System insgesamt?“
Im Diagramm der Ebene 1 wird der einzelne Prozess aus dem Kontextdiagramm in wesentliche Teilprozesse zerlegt. Dadurch wird die interne Struktur des Systems sichtbar, ohne in unnötige Details zu geraten. Es verbindet die wesentlichen Funktionsbereiche mit den externen Entitäten.
Ebene-2-Diagramme zerlegen bestimmte Prozesse aus Ebene 1 weiter. Dies geschieht, bis die Prozesse einfach genug sind, um von Entwicklern oder Betreibern verstanden zu werden. Für sehr komplexe Algorithmen oder Finanzberechnungen könnte ein Diagramm der Ebene 3 oder 4 erforderlich sein.
| Ebene | Schwerpunkt | Komplexität | Primäre Zielgruppe |
|---|---|---|---|
| Kontextdiagramm | Systemgrenzen | Niedrig (1 Prozess) | Interessenten, Management |
| Ebene 1 | Wesentliche Funktionsbereiche | Mittel (3–9 Prozesse) | Analysten, Projektmanager |
| Ebene 2+ | Spezifische Teilprozesse | Hoch (detaillierte Logik) | Entwickler, Programmierer |
Die Erstellung eines DFD ist ein systematischer Prozess. Es reicht nicht aus, einfach Formen zu zeichnen; Sie müssen einer logischen Reihenfolge folgen, um die Datenintegrität und Konsistenz auf allen Ebenen zu gewährleisten.
Beginnen Sie damit, alle Quellen und Zielorte von Daten aufzulisten. Dies sind die Benutzer, anderen Systeme oder Abteilungen, die mit Ihrem System interagieren. Vermeiden Sie es, interne Datenspeicher hier zu platzieren; halten Sie sie getrennt. Jede Entität sollte einen klaren Namen haben, beispielsweise „Kunde“, „Administrator“ oder „Zahlungsgateway“. Vermeiden Sie vage Begriffe wie „Benutzer“, wenn mehrere Arten von Benutzern existieren.
Zeichnen Sie für das Kontextdiagramm einen einzelnen Kreis, der das System darstellt. Beschriften Sie ihn mit dem Namen des Systems. Dies ist Ihr Ankerpunkt. Stellen Sie sicher, dass alle Datenflüsse, die in diesen Kreis hinein- und hinausgehen, den in Schritt 1 identifizierten Entitäten entsprechen.
Zeichnen Sie Pfeile, die Entitäten mit dem Prozess verbinden. Beschriften Sie jeden Pfeil mit den spezifischen Daten, die übertragen werden. Schreiben Sie statt „Daten“ „Bestelldetails“ oder „Rechnung“. Diese Spezifizität ist entscheidend für spätere Entwicklungsphasen. Stellen Sie sicher, dass kein Pfeil einen anderen ohne klaren Verbindungspunkt kreuzt.
Um Ebene 1 zu erstellen, ersetzen Sie den einzelnen Systemkreis durch mehrere Prozesse. Diese Prozesse sollten Hauptfunktionen darstellen, beispielsweise „Bestellung validieren“, „Zahlung verarbeiten“ und „Lagerbestand aktualisieren“. Verbinden Sie diese Prozesse miteinander und mit den externen Entitäten über die zuvor identifizierten Datenflüsse.
Identifizieren Sie, wo Daten gespeichert werden müssen. Wenn Daten für einen späteren Prozess oder zur Berichterstattung benötigt werden, müssen sie in einen Datenspeicher gelangen. Verbinden Sie den Datenspeicher mit dem Prozess, der darauf schreibt, und dem Prozess, der daraus liest. Denken Sie daran: Ein Prozess kann nicht direkt in einen anderen Prozess schreiben; er muss über einen Speicher gehen, wenn Persistenz erforderlich ist.
Überprüfen Sie jeden Prozess daraufhin, ob Eingaben und Ausgaben übereinstimmen. Dies ist das Prinzip der Datenkonservierung. Sie können keine Daten aus dem Nichts erschaffen, noch können Sie sie ohne Protokoll löschen. Wenn ein Prozess Eingaben hat, aber keine Ausgaben, handelt es sich um einen „Schwarzen Loch“. Wenn er Ausgaben hat, aber keine Eingaben, ist es ein „Wunder“. Beides sind Fehler im Modell.
Ein DFD ist ein Kommunikationswerkzeug. Wenn er schwer verständlich ist, misslingt er seiner primären Aufgabe. Die Einhaltung strenger Konventionen hilft dabei, Klarheit über Teams hinweg zu gewährleisten.
Sogar erfahrene Analysten können Fehler machen. Die frühzeitige Erkennung dieser häufigen Fehler kann erheblichen Nacharbeitsschaden später vermeiden.
Es ist üblich, DFDs mit anderen Diagrammierungsmethoden zu verwechseln. Das Verständnis des Unterschieds stellt sicher, dass Sie das richtige Werkzeug für die Aufgabe verwenden.
| Diagramm-Typ | Schwerpunkt | Am besten geeignet für |
|---|---|---|
| Datenflussdiagramm | Informationsbewegung | Systemanforderungen, Prozesslogik |
| Ablaufdiagramm | Steuerlogik, Entscheidungen | Algorithmusentwurf, Schritt-für-Schritt-Prozeduren |
| Entitäts-Beziehungs-Diagramm | Datenstruktur, Beziehungen | Datenbankdesign, Schema-Definition |
Während ein Ablaufdiagramm die Reihenfolge der Operationen zeigt (Wenn X, dann Y), zeigt ein DFD die Abhängigkeiten zwischen Datenumformungen. Ein DFD berücksichtigt nicht die Ausführungsreihenfolge, sondern nur den Informationsfluss. Dadurch sind DFDs ideal geeignet, um Systemanforderungen zu analysieren, bevor die Logik endgültig festgelegt ist.
Systeme entwickeln sich weiter. Anforderungen ändern sich, und Funktionen werden hinzugefügt. Ein DFD, der zu Beginn eines Projekts erstellt wurde, kann schnell veraltet sein. Es ist entscheidend, das Diagramm im Laufe der Systementwicklung auf dem neuesten Stand zu halten.
Ein Datenflussdiagramm zu erstellen, ist eine Disziplin, die Geduld und Genauigkeit erfordert. Es zwingt Sie dazu, über Daten nachzudenken, nicht nur über Funktionen. Indem Sie den oben beschriebenen strukturierten Ansatz befolgen, stellen Sie sicher, dass das entstehende Modell genau, wartbar und für das gesamte Lebenszyklus des Systems nützlich ist.
Denken Sie daran, dass das Ziel nicht darin besteht, sofort ein perfektes Bild zu erstellen. Es geht darum, eine Karte zu schaffen, die das Entwicklungsteam leitet. Beginnen Sie mit dem Kontextdiagramm, überprüfen Sie die Grenzen und gehen Sie dann in die Details. Je mehr Sie üben, desto intuitiver wird der Zerlegungsprozess, und Ihre Diagramme werden zu einem leistungsfähigen Kommunikationsmittel für Ihr Team.
Behalten Sie den Fokus auf den Daten. Stellen Sie sicher, dass jeder Pfeil einen Zweck hat, jeder Prozess eine Transformation durchführt und jeder Speicherort einen Grund für seine Existenz hat. Dieser disziplinierte Ansatz führt zu Systemen, die robust, skalierbar und an die geschäftlichen Anforderungen angepasst sind.