 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











Die agile Methodik verspricht Flexibilität, Reaktionsfähigkeit und kontinuierliche Verbesserung. Doch die Realität beinhaltet oft Rückschläge. Ein gescheiterter Sprint ist kein Anomalie; er ist ein Datenpunkt. Dass eine Team die Bewältigung von Fehlern versteht, bestimmt den langfristigen Erfolg mehr als das Feiern perfekter Zyklen.
Dieser Artikel untersucht einen spezifischen Fall, bei dem ein Entwicklerteam seine Sprint-Ziele vollständig verfehlte. Wir werden die technischen und menschlichen Faktoren beleuchten, den retrospektiven Prozess zur Diagnose der Probleme analysieren und die konkreten Schritte aufzeigen, die unternommen wurden, um Geschwindigkeit und Qualität wiederherzustellen.
Um den Fehler zu verstehen, müssen wir zunächst die Struktur verstehen. Die Organisation arbeitet mit einem querschnittsorientierten Teammodell. Die Gruppe besteht aus fünf Entwicklern, einem Product Owner und einem spezialisierten Tester. Die Arbeit ist in zweiwöchige Zyklen gegliedert.
Das Team nutzte eine physische und digitale Verfolgungsboard, um den Fluss zu steuern. Stories wurden von Backlog nach In Bearbeitung und schließlich nach Erledigt. Das Ziel war die konsistente Lieferung von Wert ohne Einbußen bei der Codequalität.
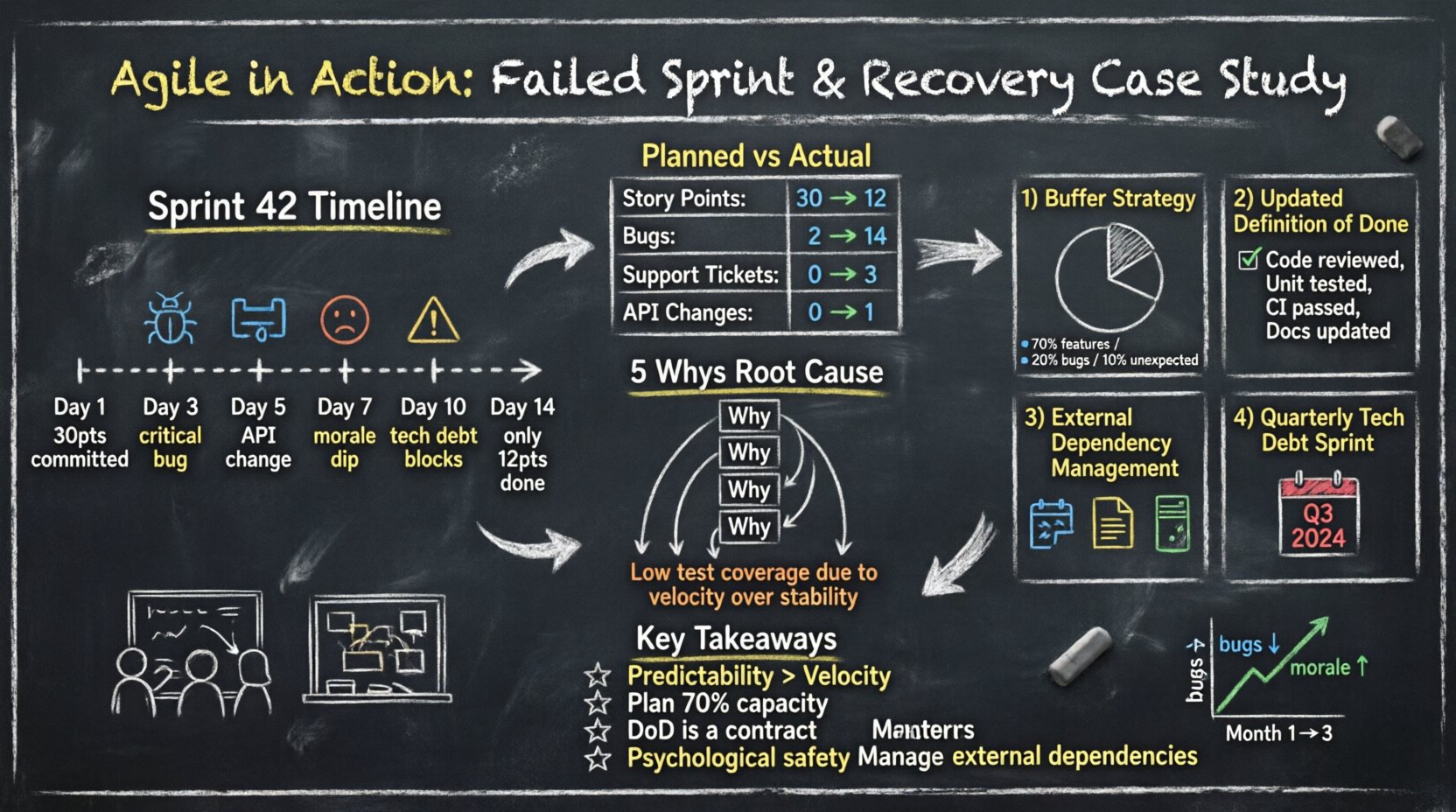
Sprint 42 begann mit hoher Dynamik. Das Team zog 30 Storypoints aus dem Backlog. Am dritten Tag schien das Tempo stabil. Am fünften Tag zeigten sich Spannungen. Am zehnten Tag erkannte das Team, dass es die verpflichteten Arbeiten nicht abschließen würde.
Der Fehler war nicht auf ein einzelnes katastrophales Ereignis zurückzuführen. Es war eine sich häufende Reihe von Problemen, die die Kapazität schrittweise aufzehrten.
Zahlen erzählen eine klarere Geschichte als Gefühle. Die folgende Tabelle veranschaulicht die Abweichung zwischen geplantem Aufwand und tatsächlichem Ergebnis.
| Kategorie | Geplant | Tatsächlich | Abweichung |
|---|---|---|---|
| Geschaffene Story-Punkte | 30 | 12 | -18 |
| Fehler gefunden (während des Sprints) | 2 | 14 | +12 |
| Support-Tickets bearbeitet | 0 | 3 | +3 |
| Änderungen externer Abhängigkeiten | 0 | 1 | +1 |
Diese Daten zeigen eine erhebliche Abweichung der Ressourcen. Was als Entwicklungsaufgabe begann, entwickelte sich zu Wartung und Krisenmanagement.
Die Schuldzuweisung einzelner Personen löst keine systemischen Probleme. Das Team führte eine schuldfreie Ursachenanalyse durch, um die zugrundeliegenden Probleme zu identifizieren.
Um tiefer zu gründen, setzte das Team die5-WhyMethode zum Problem der verpassten Fristen ein.
Das Kernproblem war nicht die Planungsgenauigkeit; es waren nachhaltige ingenieurtechnische Praktiken.
Eine Retrospektive ist die Triebkraft der agilen Verbesserung. Ein gescheiterter Sprint erfordert jedoch eine spezifische Art von Retrospektive. Standardformate wirken oft wie eine Kästchen-Arbeit. Diese Sitzung erforderte psychologische Sicherheit und tiefgreifende Untersuchung.
Vor der Sitzung sammelte der Product Owner Daten. Das Team wurde gebeten, einzeln darüber nachzudenken, was gut lief und was nicht. Dadurch hatten auch zurückhaltende Teammitglieder Zeit, ihre Gedanken zu ordnen.
Das Team diskutierte das Konzept von Kapazitätsplanung. Sie erkannten, dass sie 100 % ihrer Zeit für neue Funktionen verplant hatten. Es gab keine Pufferzeit für die unvermeidlichen Störungen, die in Produktivumgebungen auftreten.
Sie behandelten auch die Definition von Fertiggestellt. Derzeit bedeutete „Fertiggestellt“ „Code geschrieben“. Es schloss nicht „Code geprüft“ oder „Tests geschrieben“ ein. Diese Diskrepanz verursachte eine Engstelle am Ende des Sprints.
Das Erkennen des Problems ist nur die Hälfte des Kampfes. Der Erholungsplan erforderte Änderungen im Arbeitsablauf, in den Erwartungen und in den technischen Standards.
Das Team hörte auf, 100 % ihrer verfügbaren Stunden zu verplanen. Sie übernahmen eine Pufferstrategie.
Diese Änderung verringerte den Druck, perfekte Zahlen zu liefern, und ermöglichte eine realistische Bewältigung von Störungen.
Das Team aktualisierte ihre DoD-Checkliste. Eine Geschichte konnte nicht weitergehen zu Erledigt ohne diese Kriterien zu erfüllen:
Dies verhinderte eine stille Ansammlung technischer Schulden. Es stellte sicher, dass das Gelieferte wirklich nutzbar war.
Kommunikationskanäle mit externen Lieferanten wurden formalisiert. Das Team erfordert nun:
Das Team hat sich darauf geeinigt, einen Sprint pro Quartal speziell zur Reduzierung technischer Schulden zu verwenden. Dies verhindert die sich verstärkende Wirkung schlechten Codes. Es signalisiert den Stakeholdern, dass Stabilität eine Funktion ist, keine nachträgliche Überlegung.
Die Änderungen wurden sofort in Sprint 43 umgesetzt. Die Erholung war nicht sofort spürbar, aber die Entwicklungslinie veränderte sich.
Das Team zielte nicht darauf ab, die alte Geschwindigkeit von 30 Punkten zurückzugewinnen. Sie zielten aufVorhersagbarkeit. Es ist besser, weniger zu verpflichten und konsistent zu liefern, als zu viel zu versprechen und zu versagen.
Um sicherzustellen, dass die Erholung anhält, verfolgte das Team über die nächsten drei Monate spezifische Metriken.
| Woche | Sprint-Ziel erreicht | Anzahl der Bugs | Team-Morale (1-5) |
|---|---|---|---|
| Monat 1 | Ja | 12 | 3 |
| Monat 2 | Ja | 8 | 4 |
| Monat 3 | Ja | 5 | 5 |
Die Daten zeigen eine klare Korrelation zwischen Prozessänderungen und der Teamgesundheit. Weniger Bugs führten zu weniger Stress, was die Morale verbesserte.
Fehlschlag ist ein Lehrmeister. Hier sind die Lektionen aus dieser Fallstudie, die auf jede agile Umgebung anwendbar sind.
Geschwindigkeit ohne Stabilität ist eine Illusion. Teams sollten eine konsistente Lieferung gegenüber reinem Output priorisieren. Stakeholder vertrauen Teams, die ihre Versprechen halten, auch wenn diese Versprechen kleiner sind.
Planen Sie immer für das Unerwartete. Wenn Sie 100 Stunden zur Verfügung haben, planen Sie für 70 Stunden Arbeit. Die verbleibenden Stunden absorbieren die unvermeidliche Reibung der Softwareentwicklung.
DoD ist kein Vorschlag. Es ist ein Vertrag zwischen dem Team und dem Product Owner. Wenn eine Geschichte die DoD nicht erfüllt, ist sie nicht zur Freigabe bereit.
Wenn Dinge schief laufen, muss das Team sich sicher fühlen, sich zu äußern. Wenn Mitglieder Strafe fürchten, verbergen sie Probleme, bis sie zu Krisen werden.
Software existiert nicht im Vakuum. Abhängigkeiten von Drittanbieterdiensten müssen mit derselben Sorgfalt wie interner Code verwaltet werden.
Viele Teams versuchen, Versagen durch härtere Arbeit zu beheben. Das ist ein häufiger Fehler. Die folgenden Maßnahmen sollten während einer Wiederherstellungsphase vermieden werden.
Das Ziel von agilen Methoden ist nicht nur, Code auszuliefern, sondern ein System zu schaffen, das unbegrenzt Code ausliefern kann. Ein nachhaltiger Tempo ist die Grundlage dieses Systems.
Nach der Wiederherstellung etablierte das Team eine Rhythmus der kontinuierlichen Verbesserung. Alle zwei Wochen überprüfen sie nicht nur den Sprint, sondern auch die Gesundheit des Arbeitsablaufs. Sie stellen Fragen wie:
Diese kontinuierliche Überwachung verhindert, dass kleine Probleme erneut zu großen Ausfällen werden.
Transparenz gegenüber Stakeholdern ist entscheidend. Wenn ein Sprint scheitert, kommunizieren Sie frühzeitig. Erklären Sie die Auswirkungen, die Ursache und den Plan. Dadurch entsteht Vertrauen.
Stakeholder betrachten einen gescheiterten Sprint oft als Unfähigkeit. Wenn er als Datenpunkt zur Verbesserung erklärt wird, wird er zu einer Demonstration professioneller Reife. Sie bevorzugen ein Team, das ein Problem zugibt und behebt, vor einem Team, das das Problem versteckt.
Versagen ist normal. Eine Fehlerrate von 10 % ist oft akzeptabel, abhängig vom Bereich. Konsistente hohe Fehlerraten deuten auf ein systematisches Planungsproblem hin.
Normalerweise nein. Der Abbruch eines Sprints verschwendet die bereits investierte Zeit. Es ist besser, das zu Ende zu bringen, was möglich ist, und sich für den nächsten Zyklus neu zu orientieren.
Ja, wenn Ihre Geschwindigkeit durch Überverpflichtung künstlich aufgebläht ist. Die Senkung auf realistische Werte verbessert Genauigkeit und Vorhersagbarkeit.
Kurzfristige Lösungen sind möglich, aber eine langfristige Erholung erfordert einen Prozesswandel. Andernfalls wird der Fehler sich wiederholen.
Agil ist eine Reise der Anpassung. Ein gescheiterter Sprint ist nicht das Ende des Weges; er ist ein Hinweisschild, das auf bessere Praktiken hinweist. Durch eine tiefe Analyse des Fehlschlags und die Umsetzung struktureller Änderungen können Teams stärker und widerstandsfähiger hervorgehen.