 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











In den frühen Stadien des Aufbaus eines Technologieunternehmens ist Klarheit Währung. Gründer tauchen oft direkt in die Programmierung ein, ohne die zugrundeliegende Datenbewegung vollständig zu visualisieren. Dieser Ansatz führt häufig später zu technischem Schuldenberg und komplexen Debugging-Sitzungen. Ein Datenflussdiagramm (DFD) bietet eine strukturierte Methode, um zu visualisieren, wie Informationen durch ein System fließen. Dieser Leitfaden untersucht ein realweltliches Beispiel, bei dem ein Startup diese Methode nutzte, um ihre Architektur zu klären, bevor ein einziger Codezeile geschrieben wurde.
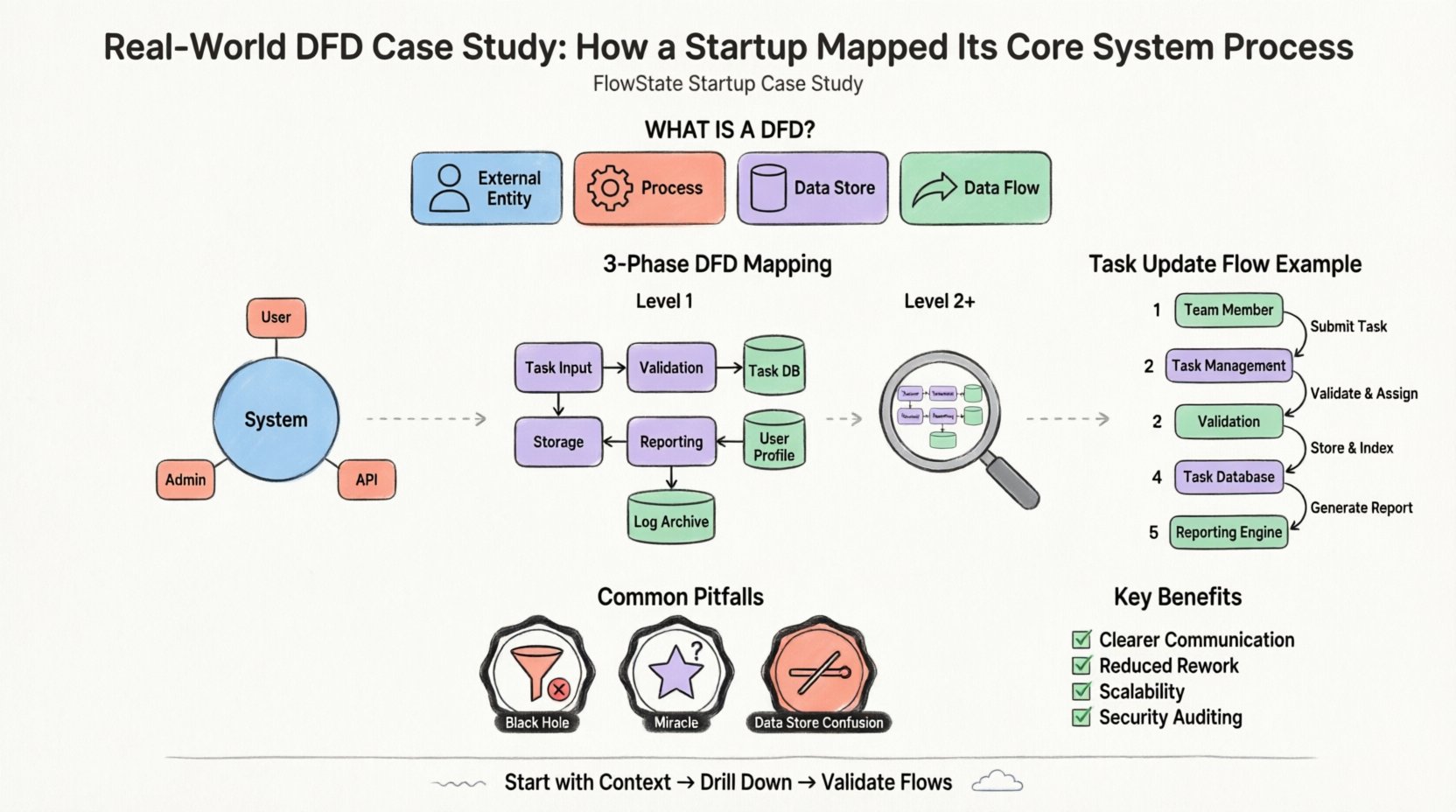
Stellen Sie sich einen hypothetischen Startup namens „FlowState“ vor, der eine Projektmanagement-Plattform für Remote-Teams entwickeln möchte. Der zentrale Wertvorschlag umfasst die Aufgabenvergabe, Echtzeit-Statusaktualisierungen und automatisierte Berichterstattung. Das Gründungsteam stand vor einem häufigen Problem: Sie hatten eine vage Vorstellung davon, wie Benutzerdaten von der Oberfläche zur Datenbank und zurück fließen sollten.
Ohne eine klare Karte lief das Entwicklungsteam Gefahr:
Die Lösung war keine zusätzlichen Besprechungen, sondern eine bessere Modellierung. Sie übernahmen die Methode des Datenflussdiagramms, um die Systemlogik zu dokumentieren. Dieser Ansatz ermöglichte es ihnen, das System als eine Reihe von Transformationen zu sehen, anstatt als eine statische Datenbank.
Ein Datenflussdiagramm ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Es zeigt nicht die zeitliche Abfolge von Prozessen oder die Logik der Entscheidungsfindung (wie ein Algorithmus), sondern vielmehr die Bewegung von Daten von einer Quelle zu einem Ziel. Es konzentriert sich auf das was, nicht auf das wie.
Die Standardkomponenten, die bei dieser Modellierungstechnik verwendet werden, umfassen:
Durch die Aufteilung des FlowState-Projekts in diese Komponenten konnten das Team Engpässe identifizieren und die Datenintegrität vor der Implementierung sicherstellen.
Der erste Schritt bei der Abbildung des Systems ist das Kontextdiagramm. Es handelt sich um eine Übersichtsebene, die die Systemgrenze definiert. Es zeigt das System als einen einzigen Prozess und wie es mit externen Entitäten interagiert.
Für FlowState ist die Grenze die Projektverwaltungsanwendung selbst. Alles, was sich innerhalb befindet, gehört zum System; alles außerhalb ist eine Entität. Das Team identifizierte drei primäre externe Entitäten:
Das Team zeichnete Pfeile, um die Eingangs- und Ausgangsströme darzustellen. Zum Beispiel:
Dieses einzige Diagramm klärte den Umfang. Es verhinderte, dass das Team versehentlich Funktionen wie „Abrechnungsverarbeitung“ einbezog, falls diese zu diesem Zeitpunkt nicht zum Kernsystem gehörten. Es schuf einen klaren Vertrag zwischen dem System und seinen Nutzern.
Sobald der übergeordnete Kontext festgelegt war, musste das Team die internen Abläufe verstehen. Dies wird durch die Zerlegung auf Ebene 1 erreicht. Der einzelne Prozess aus dem Kontextdiagramm wird in Unterverarbeitungen aufgebrochen.
Das „FlowState-System“ wurde in logische funktionale Gruppen aufgeteilt. Das Team identifizierte die folgenden Schlüsselprozesse:
Wesentlich ist, dass das Level-1-Diagramm Datenspeicher einführt. Dies zeigt, wo Informationen persistiert werden. Das Team identifizierte drei Hauptspeicher:
Durch die explizite Benennung dieser Speicher konnten die Entwickler sofort erkennen, welche Daten in die Datenbank geschrieben werden mussten und welche im temporären Speicher gehalten werden sollten.
Mit der Level-1-Struktur vorliegend, überprüfte das Team die spezifischen Daten, die zwischen Prozessen und Speichern fließen. Dieser Schritt ist oft der Punkt, an dem Fehler früh erkannt werden.
Lassen Sie uns die Bewegung eines einzelnen Datenpunkts verfolgen: eine „Aufgabenstatusänderung.“
Diese Nachverfolgung zeigte ein potenzielles Problem auf. Das Team erkannte, dass die „Berichterstattungs-Engine“ manuell jedes Mal ausgelöst wurde, wenn sich eine Aufgabe änderte. Sie entschieden sich, dies zu optimieren, indem der Berichtsprozess nur dann ausgelöst wird, wenn ein bestimmtes „Status = Abgeschlossen“-Flag gesetzt ist, wodurch die Systembelastung sinkt.
Das Verständnis der Unterschiede zwischen Diagrammebenen ist entscheidend, um Klarheit zu bewahren, während das Projekt wächst. Die folgende Tabelle zeigt die Unterschiede auf.
| Ebene | Schwerpunkt | Am besten geeignet für |
|---|---|---|
| Kontext (Ebene 0) | Systemgrenze | Hochrangige Kommunikation mit Stakeholdern |
| Ebene 1 | Hauptprozesse | Architektonische Planung und Umfangsdefinition |
| Ebene 2+ | Detailierung von Unterprozessen | Spezifische Implementierungslogik und Debugging |
Selbst mit einer klaren Methodik machen Teams häufig Fehler bei der Erstellung dieser Diagramme. Das FlowState-Team stieß auf mehrere Hürden und lernte, sie zu vermeiden.
Ein Prozess, der Eingaben hat, aber keine Ausgaben, ist ein schwarzes Loch. Daten gehen ein und verschwinden. In der ersten Entwurfsphase erhielt der „Benachrichtigungs-Handler“ Daten, hatte aber keinen Pfeil, der ihn an die externe Entität weiterleitete. Das Team erkannte, dass es den eigentlichen Versandmechanismus vergessen hatte. Jeder Prozess muss eine Ausgabe haben.
Ein Prozess, der eine Ausgabe hat, aber keine Eingabe, ist ein Wunder. Es bedeutet, dass Daten aus dem Nichts entstehen. Das Team hatte ursprünglich einen Prozess „Bericht generieren“, der Daten erzeugte, ohne aus der „Aufgaben-Datenbank“ zu lesen. Sie korrigierten dies, indem sie einen Datenfluss von der Datenbank zum Prozess hinzufügten.
Prozesse interagieren mit Datenbanken, aber Entitäten nicht. Anfangs zeichnete das Team eine Linie direkt vom „Teammitglied“ zur „Aufgaben-Datenbank“. Dies verstößt gegen die Regel, dass Daten durch einen Prozess gehen müssen, um transformiert oder validiert zu werden. Alle Daten, die eine Datenbank berühren, müssen zuerst durch einen Prozess gehen.
Eine der wichtigsten Regeln in der DFD-Methodik ist das Ausbalancieren. Die Eingaben und Ausgaben eines übergeordneten Prozesses müssen mit den Eingaben und Ausgaben seines Kind-Diagramms (der Zerlegung) übereinstimmen.
Für FlowState hatte der Prozess „Aufgabenverwaltung“ im Diagramm der Ebene 1 spezifische Eingaben (Aufgabendaten) und Ausgaben (Statusaktualisierung). Als sie dies in Diagramme der Ebene 2 zerlegten (z. B. „Aufgabe erstellen“, „Aufgabe löschen“), stellten sie sicher, dass die kombinierten Flüsse weiterhin mit dem übergeordneten Prozess übereinstimmten. Dadurch wird sichergestellt, dass während der Zerlegung keine Daten verloren gehen oder neu entstehen.
Warum Zeit in diese Dokumentationsphase investieren? Die Vorteile reichen über die ursprüngliche Abbildung hinaus.
Bevor sie in die Entwicklung gingen, nutzte das FlowState-Team die folgende Prüfliste, um ihre Arbeit zu validieren.
Der Übergang von einem Konzept zu einem funktionsfähigen Produkt erfordert mehr als nur Programmierkenntnisse. Es erfordert ein tiefes Verständnis des Informationsökosystems, das Sie aufbauen. Durch die Abbildung der Datenflüsse stellte FlowState sicher, dass ihre Architektur vor der Bereitstellung solide war.
Diese Fallstudie zeigt, dass ein Datenflussdiagramm nicht nur eine Zeichenaufgabe ist. Es ist ein Werkzeug für kritisches Denken. Es zwingt das Team, schwierige Fragen darüber zu stellen, wo die Daten herkommen, wohin sie gehen und wie sie sich verändern. Für jedes Startup, das ein robustes System aufbauen möchte, ist die Investition von Zeit in diese Modellierungsphase ein strategischer Vorteil.
Denken Sie daran, das Ziel ist keine Perfektion im ersten Entwurf. Das Ziel ist Klarheit. Beginnen Sie mit dem Kontext, gehen Sie zu den Prozessen über und validieren Sie die Flüsse. Dieser disziplinierte Ansatz führt zu Systemen, die einfacher zu pflegen, sicherer und skalierbarer sind.
Wenn Sie Ihre eigene Projektabbildung beginnen, halten Sie diese Prinzipien im Auge. Konzentrieren Sie sich auf die Bewegung der Daten, achten Sie auf die Grenzen und validieren Sie jede Verbindung. Ihre zukünftige Selbst wird Ihnen für die Klarheit danken, die Sie heute schaffen.