 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











テクノロジー企業を構築する初期段階では、明確さが価値ある資産となる。創業者たちは、データの流れを十分に可視化せずに、いきなりコーディングに取り掛かることが多い。このアプローチは、後々に技術的負債や複雑なデバッグ作業を招きやすい。データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを可視化する構造的な手法を提供する。このガイドでは、スタートアップがコードを1行も書く前に、アーキテクチャを明確にするためにこの手法を実際にどのように活用したかを、実際の事例を通して探求する。
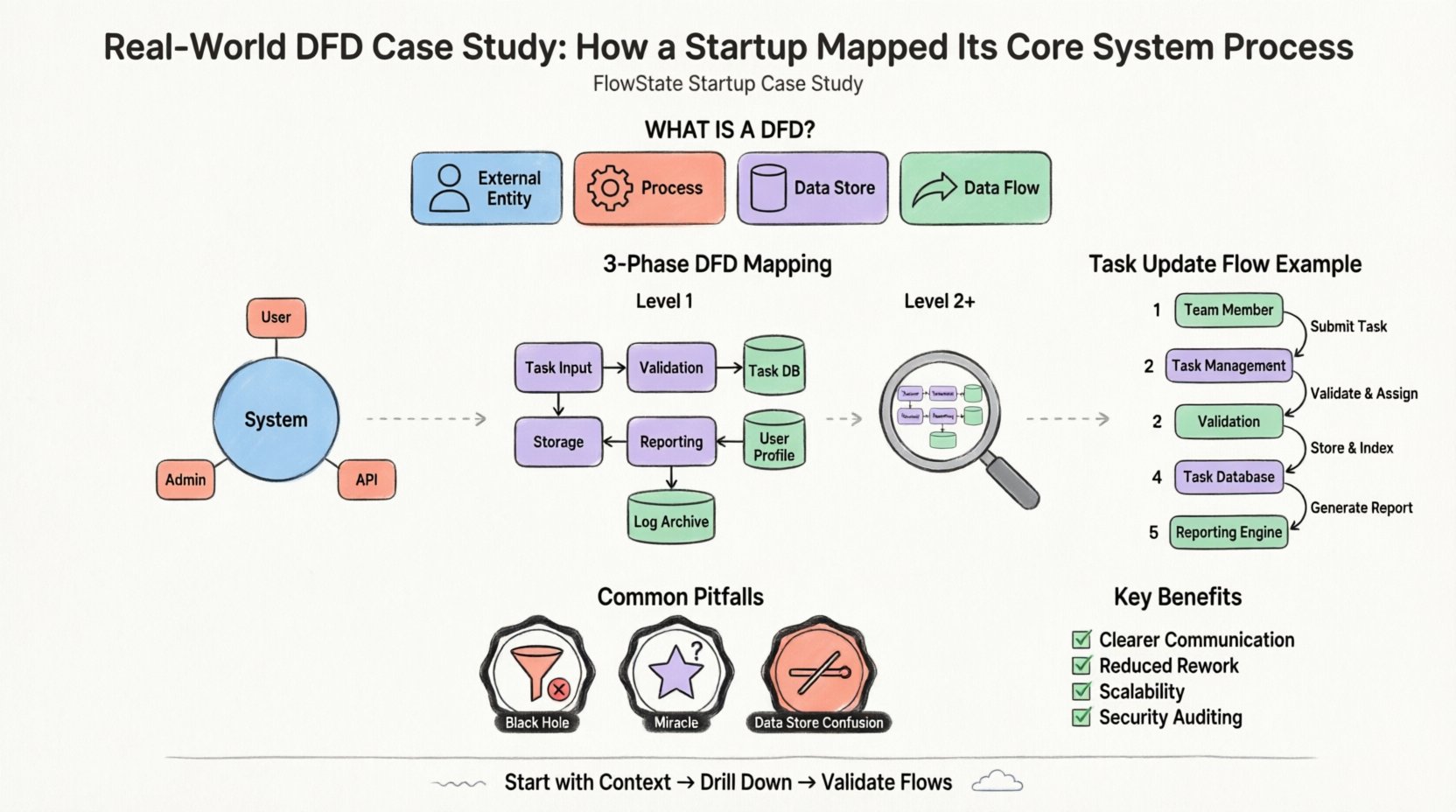
「FlowState」という架空のスタートアップを想定しよう。この企業はリモートチーム向けのプロジェクト管理プラットフォームの構築を目指している。コア価値提案は、タスクの割り当て、リアルタイムでのステータス更新、自動レポート生成にある。創業チームが直面した一般的な問題は、ユーザーのデータがインターフェースからデータベースへ、そして戻ってくるまでの流れについて、曖昧な理解しか持っていないことだった。
明確なマップがなければ、開発チームは以下のリスクに直面していた:
解決策は、さらに会議を増やすことではなく、より良いモデル化であった。彼らはデータフローダイアグラムの手法を取り入れ、システムの論理を文書化した。このアプローチにより、システムを静的なデータベースではなく、一連の変換プロセスとして捉えることが可能になった。
データフローダイアグラムとは、情報システム内を流れるデータの流れを図式化したものである。これはプロセスのタイミングや意思決定の論理(アルゴリズムのように)を示すものではないが、データが元から目的地へと移動する様子を示す。焦点は「何」にあり、そして「どう.
このモデル化手法で使用される標準的な構成要素は以下の通りである:
FlowStateプロジェクトをこれらの構成要素に分解することで、チームは実装前にボトルネックを特定し、データの整合性を確保できた。
システムをマッピングする最初のステップがコンテキスト図である。これはシステムの境界を定義する高レベルの視点である。システムを単一のプロセスとして示し、外部エントリとの相互作用を描く。
FlowStateにおいて、境界はプロジェクト管理アプリケーションそのものである。境界内部にあるものはすべてシステムの一部であり、外部にあるものはエントリティである。チームは主に3つの外部エントリティを特定した。
チームは矢印を描いて入力および出力の流れを表した。例えば:
この1枚の図で範囲が明確になった。もし当時コアシステムの一部でなかった場合、「請求処理」のような機能を誤って含めてしまうのを防ぐことができた。システムとユーザーとの間で明確な契約を確立した。
高レベルの文脈が確立された後、チームは内部の動作を理解する必要があった。これはレベル1の分解によって達成される。コンテキスト図の単一のプロセスが、サブプロセスに分解される。
「FlowStateシステム」は論理的な機能グループに分解された。チームは以下の主要プロセスを特定した:
重要なのは、レベル1の図がデータストアを導入した点である。これは情報が永続化される場所を示している。チームは主に3つのストアを特定した:
これらのストアを明確に名前付けすることで、開発者はどのデータをデータベースに書き込む必要があるか、どのデータを一時メモリに保持する必要があるかを即座に把握できた。
レベル1の構造を整えた後、チームはプロセスとストアの間を流れている具体的なデータを検討した。このステップでは、しばしば早期にエラーが発見される。
1つのデータポイントの移動を追跡してみよう:「タスクステータスの変更」である。
このトレースにより、潜在的な問題が明らかになった。チームは、タスクが変更されるたびに「レポートエンジン」が手動で起動されていたことに気づいた。特定の「ステータス=完了」フラグが設定されたときだけレポートプロセスを起動するようにすることで、システム負荷を削減する最適化を決定した。
図のレベル間の違いを理解することは、プロジェクトが拡大するにつれて明確さを保つために不可欠である。以下の表はその違いを概説している。
| レベル | 焦点 | 最も適した用途 |
|---|---|---|
| コンテキスト(レベル0) | システム境界 | 上位ステakeholderとのコミュニケーション |
| レベル1 | 主要プロセス | アーキテクチャ設計と範囲定義 |
| レベル2以上 | サブプロセスの詳細 | 具体的な実装ロジックとデバッグ |
明確なメソドロジーがあるにもかかわらず、チームはこれらの図を作成する際にしばしば誤りを犯す。FlowStateチームはいくつかの障害に直面し、それらを回避する方法を学んだ。
入力はあるが出力がないプロセスはブラックホールである。データが入って消えてしまう。初期のドラフトでは、「通知ハンドラ」はデータを受け取ったが、外部エンティティへ向かう矢印がなかった。チームは実際に送信メカニズムを定義し忘れていたことに気づいた。すべてのプロセスには出力が必要である。
出力はあるが入力がないプロセスは奇跡である。データが空から生成されたことを意味する。チームは当初、「レポート生成」プロセスが「タスクデータベース」から読み取らずにデータを生成していた。これを修正するために、ストアからプロセスへのデータフローを追加した。
プロセスはデータストアとやり取りするが、エンティティはそうではない。当初、チームは「チームメンバー」から直接「タスクデータベース」へ線を引いていた。これは、データが変換または検証されるためにプロセスを経由しなければならないというルールに違反している。ストアにアクセスするすべてのデータは、まずプロセスを経由しなければならない。
DFD手法における最も重要なルールの一つがバランスである。親プロセスの入力と出力は、その子図(分解図)の入力と出力と一致しなければならない。
FlowStateの場合、レベル1の図における「タスク管理」プロセスには特定の入力(タスクデータ)と出力(ステータス更新)があった。これをレベル2の図(例:「タスク作成」、「タスク削除」)に分解した際、結合されたフローが親プロセスと一致することを確認した。これにより、分解中にデータが失われたり、新たに生成されたりすることを防ぐことができる。
このドキュメント作成フェーズに時間を投資する理由は何か?その利点は初期マッピングを越えて広がる。
開発へ移行する前に、FlowStateチームは以下のチェックリストを使って作業の妥当性を検証した。
コンセプトから機能的な製品へと移行するには、コーディングスキル以上のものが必要です。構築している情報エコシステムについて深い理解を持つことが求められます。データフローを可視化することで、FlowStateは展開前にアーキテクチャが堅固であることを確認しました。
この事例研究は、データフローダイアグラムが単なる図面作成作業ではないことを強調しています。それは重要な思考ツールです。チームがデータの出所、行き先、変化の仕組みについて難問を自問させます。あらゆるスタートアップが堅牢なシステムを構築しようとする場合、このモデリング段階に時間を投資することは戦略的な優位性をもたらします。
思い出してください。最初のドラフトで完璧を目指すのではなく、明確さを目指すことが目的です。まずコンテキストから始め、プロセスに掘り下げ、フローを検証してください。この厳格なアプローチにより、保守性、セキュリティ、スケーラビリティが向上するシステムが生まれます。
自らのプロジェクトマッピングを始める際には、これらの原則を常に心に留めてください。データの流れに注目し、境界を尊重し、すべての接続を検証してください。今日確立した明確さのために、将来のあなたが感謝するでしょう。