 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











情報がシステム内をどのように移動するかを視覚的に表現することは、アナリスト、開発者、ビジネス関係者にとって基本的なスキルです。データフローダイアグラム(通称DFD)はまさにこの目的を果たします。DFDは、外部エンティティ、内部プロセス、データストアの間でのデータの流れを詳細な論理やタイミングを明示せずにマッピングします。このガイドは、初期のDFDを効率的に構築するための構造的なアプローチを提供します。
多くの人々は、図式化を恐れ、複雑なツールや長時間の作業を必要とすると感じます。しかし、データフロー・モデリングの基本原則はシンプルです。記号の意味を明確に理解し、体系的なアプローチを取れば、短時間で機能的な図を描くことができます。この記事では、必須の要素、ステップバイステップの構築プロセス、正確性を保証するために必要な検証チェックについて説明します。
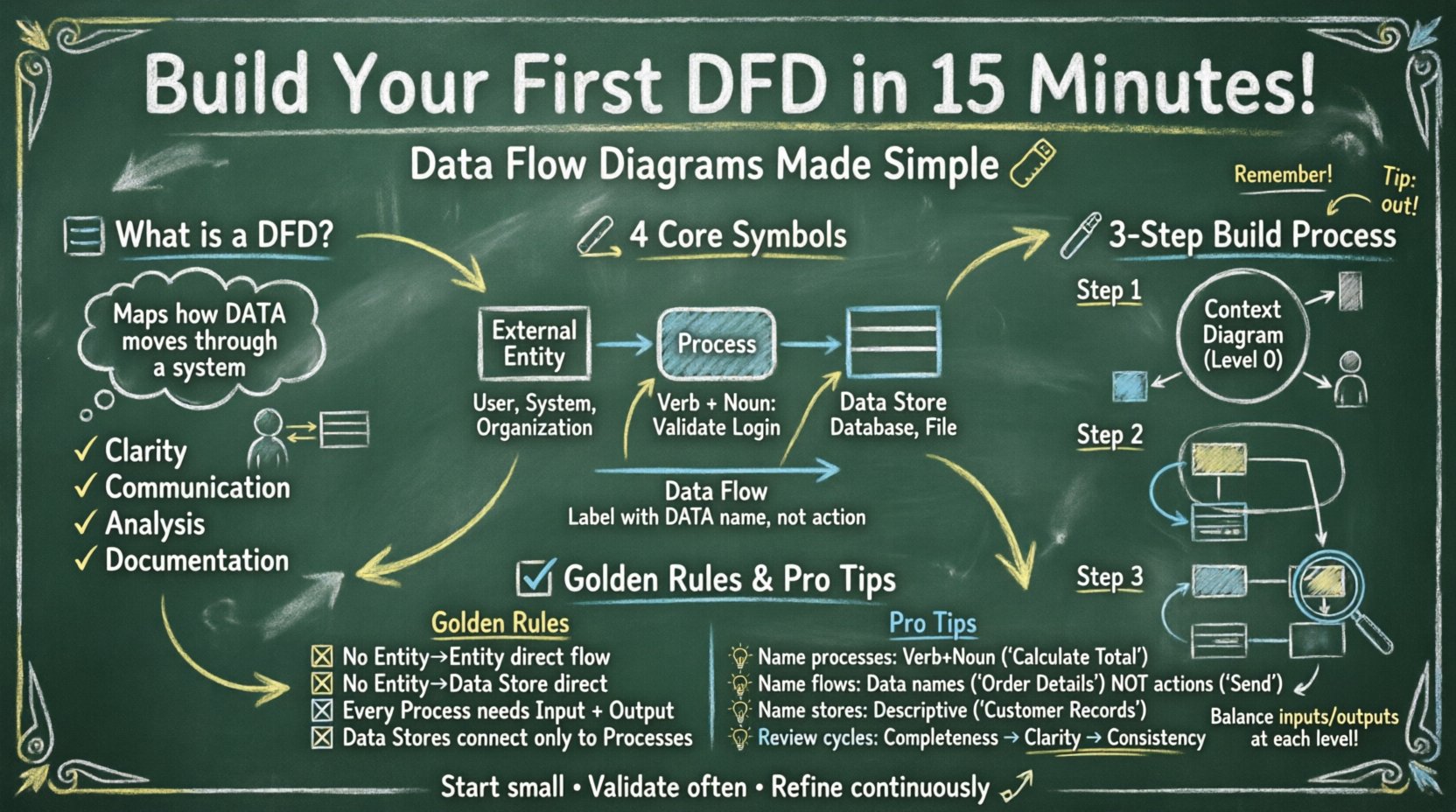
線や図形を描く前に、DFDが何を表しているかを理解することが重要です。DFDは機能モデルです。それは、システムが「何」を行うかに注目し、「どのように」行うかには注目しません。何システムが行うことを、どのようにその方法には注目しません。フローチャートは意思決定の経路や論理の順序を追跡するのに対し、DFDはデータパケットがソースから宛先へ移動する様子を追跡します。
このモデリング手法を使用する主な利点には以下が含まれます:
この作業を始める際は、目的を常に意識してください。それは、特定のシステムの境界と相互作用を可視化することです。始めるには高度なソフトウェアは必要ありません。ホワイトボード、紙、鉛筆があれば、初期のドラフトには十分です。
DFDは標準化された図形要素のセットに依存しています。表記法には違い(例えばYourdon/DeMarco表記とGane/Sarson表記)がありますが、基本的な概念は一貫しています。以下は、あなたが遭遇するであろう4つの主要な構成要素の説明です。
| 構成要素 | 形状 | 説明 |
|---|---|---|
| 外部エンティティ | 長方形または正方形 | システム外部のデータの発信元または受信先(例:ユーザー、別のシステム)。 |
| プロセス | 角が丸い長方形または円 | 入力データを出力データに変換します。データの形式や内容を変更します。 |
| データストア | 開かれた長方形または平行線 | データが保管されるリポジトリ(例:データベース、ファイルキャビネット)。 |
| データフロー | 矢印 | データがコンポーネント間を通過する経路。これは行動ではなく、移動を表す。 |
これらの違いを理解することは非常に重要です。たとえば、プロセスには少なくとも一つの入力と出力が必要です。データストアは単独で存在することはできず、読み取りまたは書き込みを行うためにプロセスに接続されなければなりません。外部エンティティはシステム境界の外に存在し、トリガーまたは受信者として機能します。
提示された時間枠内で図を構築するためには、この論理的な順序に従ってください。この方法により、詳細に突入する前に境界を明確にできます。
まずコンテキスト図(しばしばレベル0と呼ばれる)。これは最高レベルの視点です。システムを単一のプロセスとして示し、外部世界との相互作用を表します。
たとえば、図書館システムでは、「利用者」がエンティティである。「書籍の発行」プロセスがシステムである。データフローは「貸出依頼」または「書籍の詳細」になる可能性がある。
コンテキストが設定されたら、単一の中心プロセスをサブプロセスに拡張しなければなりません。これによりレベル0図.
コンテキスト図内のエンティティから出るすべての矢印が、レベル0図にも引き続き表示されていることを確認してください。ただし、今後は異なる内部プロセスに接続される可能性があります。
これにより、レベル1図。レベル0から1つのプロセスを選択し、さらに分解します。
ラベルが曖昧な図は無意味です。明確な名前付けのルールは、レビューおよび実装中に混乱を防ぎます。
プロセス名は動詞+名詞の構造に従うべきです。これにより、実行中のアクションが明確になります。
「プロセス1」のような一般的な名前は避けてください。非常に初期のスケッチ段階でない限り、具体的な名前を付けることで理解が深まります。
矢印は行動を表すのではなく、データを表します。データパケットの名前でラベルを付けます。
これらは格納された内容を示すべきです。
ドラフト作成後は、標準ルールに基づいて図を確認し、整合性を確保してください。有効なDFDは、特定の論理的制約に従わなければなりません。
経験豊富なアナリストですら、初期モデル作成時に誤りを犯すことがあります。以下の一般的な誤りに注意してください:
DFDを作成することは、ほとんど一度きりの作業ではありません。反復的な精緻化のプロセスです。最初のドラフトにはおそらく穴や誤りがあるでしょう。これは通常のことであり、問題ありません。
レビュー回目1: 完全性を確認してください。すべてのユーザー要件が表現されていますか?すべてのデータソースが考慮されていますか?
レビュー回目2: 明確性を確認してください。新しいチームメンバーがこれを見て、質問をせずにフローを理解できるでしょうか?
レビュー回目3: 一貫性を確認してください。図の異なるレベル間で名前が一致していますか?レベル0で「顧客情報」と呼ばれるデータフローは、特定の属性に分割されない限り、レベル1でも同じように呼ぶべきです。
図を急いで完成させないでください。ステークホルダーからのフィードバックに時間を割いてください。彼らの意見は、見落としていた隠れたデータ要件やプロセスを明らかにすることがあります。
システムが拡大するにつれて、1枚のページでは十分でなくなることがあります。複数の図を管理する必要があるかもしれません。ここでは、それらを論理的に整理する方法を説明します。
クロスリファレンスを使用してください。レベル1のプロセスがレベル2で拡張されている場合、レベル1の親プロセスに参照コード(例:「図2.3を参照」)を付与してください。これにより、詳細を失うことなく図を管理しやすくなります。
データフローをモデル化する際には、データセキュリティも間接的にモデル化しています。標準的なDFDは暗号化や認証プロトコルを示しませんが、機密データの移動は示します。
データフローに個人を特定できる情報(PII)や金融データが含まれる場合は、凡例やラベルにその旨を記載してください。たとえば、フローに「暗号化された支払いデータ」とラベルを付けることで、開発者がその特定のチャネルに特定のセキュリティ制御を適用する必要があることを思い出させます。
図が完成し検証された後、開発のためのブループリントになります。データベース設計、API定義、ユーザーインターフェースのレイアウトをガイドします。最終製品が初期要件と一致することを保証します。
ツールは理解よりも二次的なものであることを思い出してください。デジタルホワイトボードを使用しても、鉛筆と紙を使用しても、論理は同じです。価値は、システム構造に持ち込む思考の明確さにあります。
上記の手順に従うことで、プロジェクトチームにとって信頼できる参照資料となるプロフェッショナルレベルのデータフローダイアグラムを作成できます。小さなステップから始め、頻繁に検証し、継続的に改善してください。この規律あるアプローチが、堅牢なシステム設計につながります。