 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











アジャイル手法は柔軟性、対応力、継続的な改善を約束する。しかし現実には、挫折がつきものである。失敗したスプリントは異常ではなく、データポイントである。チームが失敗をどう乗り越えるかが、完璧なサイクルを祝うよりも長期的な成功を左右する。
本記事では、開発チームがスプリント目標をまったく達成できなかった特定の状況を検証する。技術的・人的要因、問題を診断するために用いられたリトロスペクティブプロセス、そして速度と品質を回復するために取られた具体的なステップについて考察する。
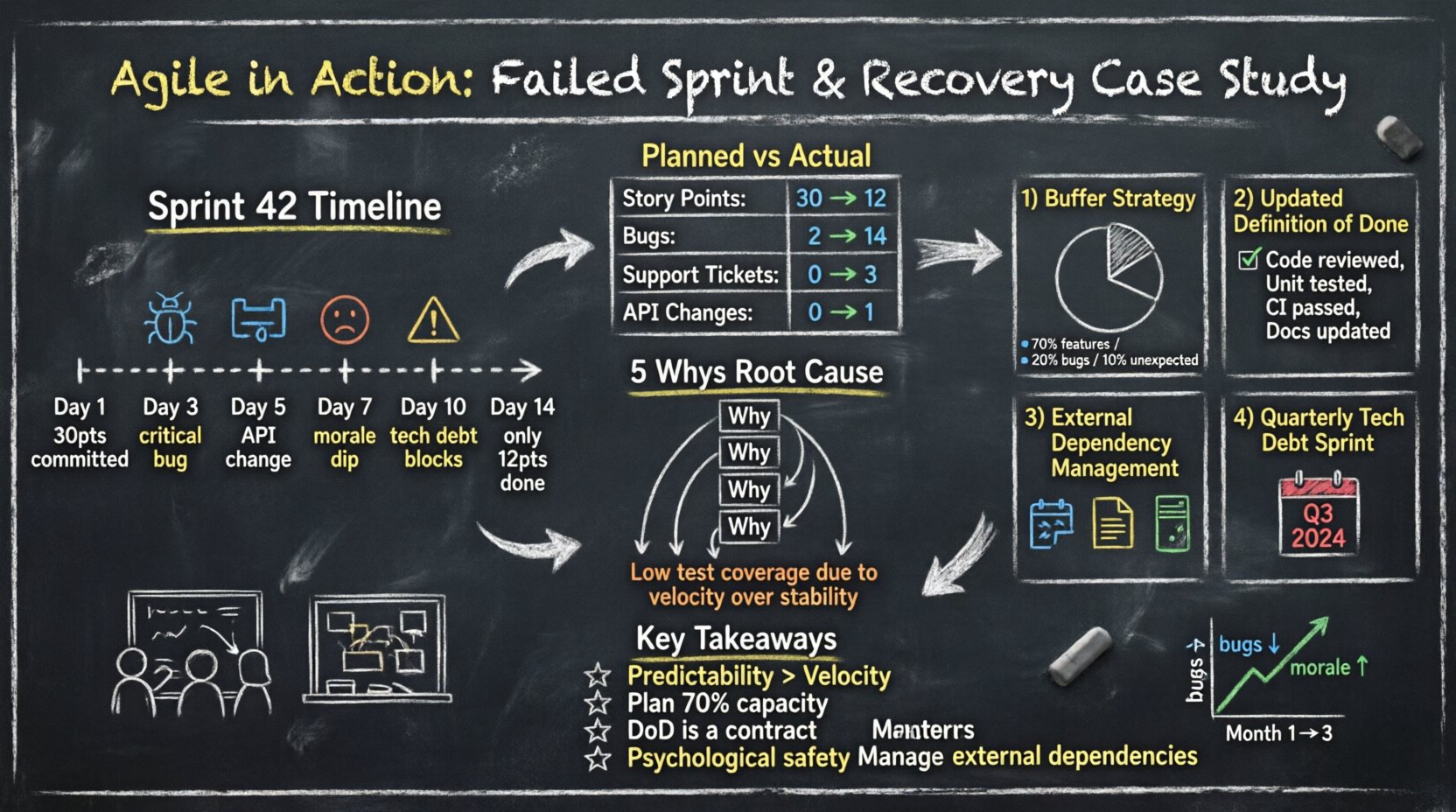
失敗を理解するためには、まず構造を把握する必要がある。組織はクロスファンクショナルチームモデルを採用している。チームは開発者5名、プロダクトオーナー1名、専任のテスト担当者から構成される。作業は2週間サイクルで組織されている。
チームは物理的およびデジタルなトラッキングボードを活用してフローを管理していた。ストーリーは「バックログ」から「進行中」へ、最終的に「完了」へと移動された。目標はコード品質を損なうことなく、一貫した価値の提供をすることだった。
スプリント42は高い勢いで始まった。チームはバックログから30ストーリーポイントを引き出した。3日目にはペースが安定しているように見えた。5日目には摩擦が生じ始めた。10日目には、チームはコミットした作業を完了できないことに気づいた。
失敗は単一の深刻な出来事によるものではなかった。能力を蝕む、複数の問題が蓄積された結果だった。
数字は感情よりもはっきりとした物語を語る。以下の表は、計画された努力と実際の納品との乖離を示している。
| カテゴリ | 計画済み | 実績 | 乖離 |
|---|---|---|---|
| 完了したストーリーポイント | 30 | 12 | -18 |
| スプリント中に発見されたバグ | 2 | 14 | +12 |
| 対応したサポートチケット | 0 | 3 | +3 |
| 外部依存の変更 | 0 | 1 | +1 |
このデータは、リソースの顕著なずれを明らかにしている。開発作業から始まったものが、維持管理と危機管理へと転換した。
個人を責めるだけでは構造的な問題は解決しない。チームは責任追及をしない根本原因分析を実施し、背後にある問題を特定した。
より深く掘り下げるために、チームは5つのなぜ遅延した納期の問題に適用した。
根本的な問題は計画の正確さではなく、持続可能なエンジニアリングの実践だった。
リトロスペクティブはアジャイル改善の原動力である。しかし、失敗したスプリントには特定のタイプのリトロスペクティブが必要だ。標準的なフォーマットはチェックボックス作業のように感じられることが多い。このセッションでは心理的安全性と深い掘り下げが求められた。
会議の前にはプロダクトオーナーがデータを集めた。チームには、何がうまくいったか、何がうまくいかなかったかを個別に振り返るよう依頼された。これにより、静かなメンバーが考えを整理する時間を持てた。
チームは「キャパシティプランニング」という概念について議論した。彼らは自分たちが新機能に100%の時間を割いていたことに気づいた。ライブ環境で避けられない中断に対応する余裕はまったくなかった。
また、彼らは「完了の定義」についても検討した。現在、「完了」とは「コードが書かれた」ことを意味していたが、「コードレビュー済み」や「テストが書かれた」は含まれていなかった。この違いがスプリントの終盤にボトルネックを生じさせていた。
問題を知ることは戦いの半分に過ぎない。回復計画にはワークフロー、期待値、技術基準の変更が必要だった。
チームは利用可能な時間の100%をコミットすることをやめた。彼らはバッファ戦略.
この変更により、完璧な数値を出さなければならないプレッシャーが軽減され、中断の対応を現実的に扱えるようになった。
チームは自身のDoDチェックリスト。ストーリーは、以下の基準を満たさない限り、次の段階に進むことはできなかった。完了これらの基準を満たさずに
これにより、技術的負債が静かに蓄積されるのを防ぎ、提供されたものが本当に使えるものであることを確実にした。
外部ベンダーとのコミュニケーションチャネルが正式化された。チームは現在、以下のものを求めている:
チームは、四半期ごとに1回、技術的負債の削減に特化したスプリントを割り当てることに合意した。これにより、悪いコードの複利効果を防ぐ。ステークホルダーに、安定性は後から考えるものではなく、機能の一部であることを示す。
変更はスプリント43で即座に実装された。回復は即時ではなかったが、トレンドは改善した。
チームは、30ポイントという古いベロシティに戻ることを目指さなかった。彼らが目指したのは予測可能性である。過剰にコミットして失敗するよりも、少ないことをコミットして一貫して納品するほうが良い。
回復が安定するようにするため、チームは次の3か月間、特定の指標を追跡しました。
| 週 | スプリント目標達成 | バグ数 | チームのモラル (1-5) |
|---|---|---|---|
| 月1 | はい | 12 | 3 |
| 月2 | はい | 8 | 4 |
| 月3 | はい | 5 | 5 |
データは、プロセスの変更とチームの健康状態の間に明確な相関関係があることを示しています。バグが減ったことでストレスが軽減され、モラルが向上しました。
失敗は教師である。このケーススタディから得られた教訓は、あらゆるアジャイル環境に適用できる。
安定性のないスピードは幻である。チームは、単なる出力よりも一貫した納品を優先すべきである。ステークホルダーは、たとえ約束が小さくても、約束を果たすチームを信頼する。
予期せぬ事態を常に想定して計画する。100時間の可用時間がいるなら、70時間分の作業を計画する。残りの時間は、ソフトウェア開発に避けがたい摩擦を吸収する。
DoDは提案ではない。チームとプロダクトオーナーとの契約である。ストーリーがDoDを満たさない限り、リリース準備は整っていない。
問題が起きたとき、チームは発言できる安心感を持たなければならない。メンバーが罰則を恐れるならば、問題は危機になるまで隠蔽されてしまう。
ソフトウェアは真空状態に存在しない。サードパーティサービスへの依存関係は、内部コードと同じ厳密さで管理されなければならない。
多くのチームは、失敗を克服するためにより頑張ろうとします。これは一般的な誤りです。回復期間中に避けなければならない以下の行動があります。
アジャイルの目的はコードを出荷することだけではなく、無限にコードを出荷できるシステムを構築することです。持続可能なペースがこのシステムの基盤です。
回復後、チームは継続的改善のリズムを確立しました。2週間に1度、スプリントだけでなくワークフローの健全性も見直します。次のような質問をします:
こうした継続的な検証により、小さな問題が再び大きな失敗になるのを防ぎます。
ステークホルダーとの透明性は不可欠です。スプリントが失敗した際は早期に連絡を取りましょう。影響、原因、対策を説明することで信頼が築かれます。
ステークホルダーはしばしば失敗したスプリントを無能さの証だと見なします。改善のためのデータポイントとして説明すれば、それはプロフェッショナルな成熟の証になります。問題を認め改善するチームよりも、問題を隠すチームを好むでしょう。
失敗は普通のことです。ドメインによっては10%のミス率はしばしば許容されます。継続的な高いミス率は、システム的な計画の問題を示しています。
通常はいいえ。スプリントを中止すると、すでに費やした時間を無駄にします。できることを終わらせ、次のサイクルに向けてリセットするほうが良いです。
はい、過度なコミットメントによって速度が人工的に高められている場合です。現実に合わせて速度を下げるほうが、正確性と予測可能性が向上します。
短期的な対策は可能ですが、長期的な回復にはプロセスの変更が必要です。そうでなければ、失敗は繰り返されます。
アジャイルとは適応の旅です。失敗したスプリントは道の終わりではなく、より良い実践へと導く指標です。失敗を深く分析し、構造的な変更を実施することで、チームはより強くなり、より回復力のある姿で生まれ変わります。