 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











सॉफ्टवेयर इंजीनियरिंग की दुनिया में प्रवेश करने के लिए अक्सर एक भी कोड लाइन लिखने से पहले जटिल ब्लूप्रिंट्स को समझना आवश्यक होता है। सिस्टम व्यवहार को मैप करने के लिए उपयोग किए जाने वाले विभिन्न डायग्राम्स में, डेटा फ्लो डायग्राम (DFD) एक महत्वपूर्ण उपकरण के रूप में उभरता है, जो जानकारी के सिस्टम के माध्यम से गति को समझने में मदद करता है। कोड के विपरीत, जो एक कार्य को कैसे किया जाता है, उसका निर्देश देता है,कैसेएक कार्य को कैसे किया जाता है, एक DFD दर्शाता हैक्याडेटा को कैसे प्रोसेस किया जाता है और वह कहाँ यात्रा करता है। एक नए इंजीनियर के लिए, इन डायग्राम्स को समझने की क्षमता सीधे तेजी से ऑनबोर्डिंग, बेहतर सिस्टम आर्किटेक्चर की समझ और स्टेकहोल्डर्स के साथ संचार में सुधार करती है।
यह गाइड आपको संकेतों की बुनियादी समझ से जटिल प्रक्रिया प्रवाहों का विश्लेषण करने की सूक्ष्म क्षमता तक ले जाने के लिए डिज़ाइन की गई है। हम DFD की रचना, इसके स्तरों की श्रेणी और मॉडलिंग त्रुटियों को दर्शाने वाले सामान्य जाल में खोज करेंगे। अंत तक, आपके पास इन डायग्राम्स को आत्मविश्वास और सटीकता के साथ पढ़ने के लिए एक व्यावहारिक ढांचा होगा।
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का एक आलेखीय प्रतिनिधित्व है। यह नियंत्रण तर्क या समय के बजाय डेटा के गति पर ध्यान केंद्रित करते हुए प्रणाली को कार्यात्मक दृष्टिकोण से मॉडल करता है। इस अंतर का महत्व है। जबकि एक क्रम आरेख घटनाओं के क्रम को दिखाता है, एक DFD इनपुट से आउटपुट तक डेटा के रूपांतरण को दिखाता है।
जब आप DFD को देखते हैं, तो आप मूल रूप से अपनी प्रणाली के तर्क का नक्शा देख रहे होते हैं। आप पहचान सकते हैं:
जहाँ डेटा उत्पन्न होता है: बाहरी स्रोत या एकाधिकार।
डेटा कैसे बदलता है: इनपुट को आउटपुट में बदलने वाली प्रक्रियाएँ।
जहाँ डेटा रुकता है: वे डेटा स्टोर जहाँ जानकारी संग्रहीत रहती है।
जहाँ डेटा समाप्त होता है: प्रोसेस की गई जानकारी के गंतव्य या प्राप्तकर्ता।
इस उद्देश्य को समझने से आप एक आम गलती से बचते हैं, जिसमें एक DFD को फ्लोचार्ट की तरह पढ़ने की कोशिश करना है। एक मानक DFD में कोई लूप, कोई निर्णय हीरा और कोई समय-आधारित क्रम नहीं होता है। यह गतिशील डेटा गति का एक स्थिर तस्वीर है। यह अमूर्तता शक्तिशाली है क्योंकि यह इंजीनियरों को निर्माण विवरणों में फंसे बिना प्रणाली की आवश्यकताओं पर चर्चा करने की अनुमति देती है।
एक DFD को प्रतिभाशाली तरीके से पढ़ने के लिए, आपको पहले इसके चार मूल घटकों को पहचानना होगा। यद्यपि नोटेशन शैलियाँ विभिन्न पद्धतियों में थोड़ी भिन्न हो सकती हैं, लेकिन मूल अवधारणाएँ स्थिर रहती हैं। निम्नलिखित तालिका इन तत्वों और उनके मानक दृश्य प्रतिनिधित्वों का वर्णन करती है।
|
घटक |
दृश्य आकृति |
कार्य |
उदाहरण |
|---|---|---|---|
|
बाहरी एकाधिकार |
आयत |
प्रणाली के बाहर डेटा का स्रोत या गंतव्य |
ग्राहक, प्रबंधक, तीसरे पक्ष का API |
|
प्रक्रिया |
वृत्त या गोल कोन वाला आयत |
इनपुट डेटा को आउटपुट डेटा में बदलता है |
कर की गणना करें, उपयोगकर्ता की पुष्टि करें |
|
डेटा स्टोर |
खुला आयत या समानांतर रेखाएं |
डेटा के बाद के उपयोग के लिए संग्रहित किया जाने वाला भंडार |
ग्राहक डेटाबेस, लॉग फ़ाइल |
|
डेटा प्रवाह |
तीर |
घटकों के बीच जाने वाले डेटा की दिशा और नाम |
आदेश विवरण, भुगतान पुष्टि |
ध्यान दें कि इन घटकों पर लेबल यादृच्छिक नहीं हैं। नामकरण पद्धति स्पष्टता के लिए निर्णायक है। एक प्रक्रिया का नाम क्रिया और संज्ञा के साथ रखा जाना चाहिए (उदाहरण के लिए, “इन्वेंटरी को अपडेट करें”), जो डेटा पर लिया गया क्रिया को दर्शाता है। एक डेटा स्टोर को संज्ञा के रूप में दर्शाया जाना चाहिए (उदाहरण के लिए, “इन्वेंटरी लॉग”), जो रिकॉर्ड के संग्रह का प्रतिनिधित्व करता है। डेटा प्रवाह को विशिष्ट सामग्री का वर्णन करने के लिए नामित किया जाना चाहिए जो तीर के साथ आगे बढ़ रही है।
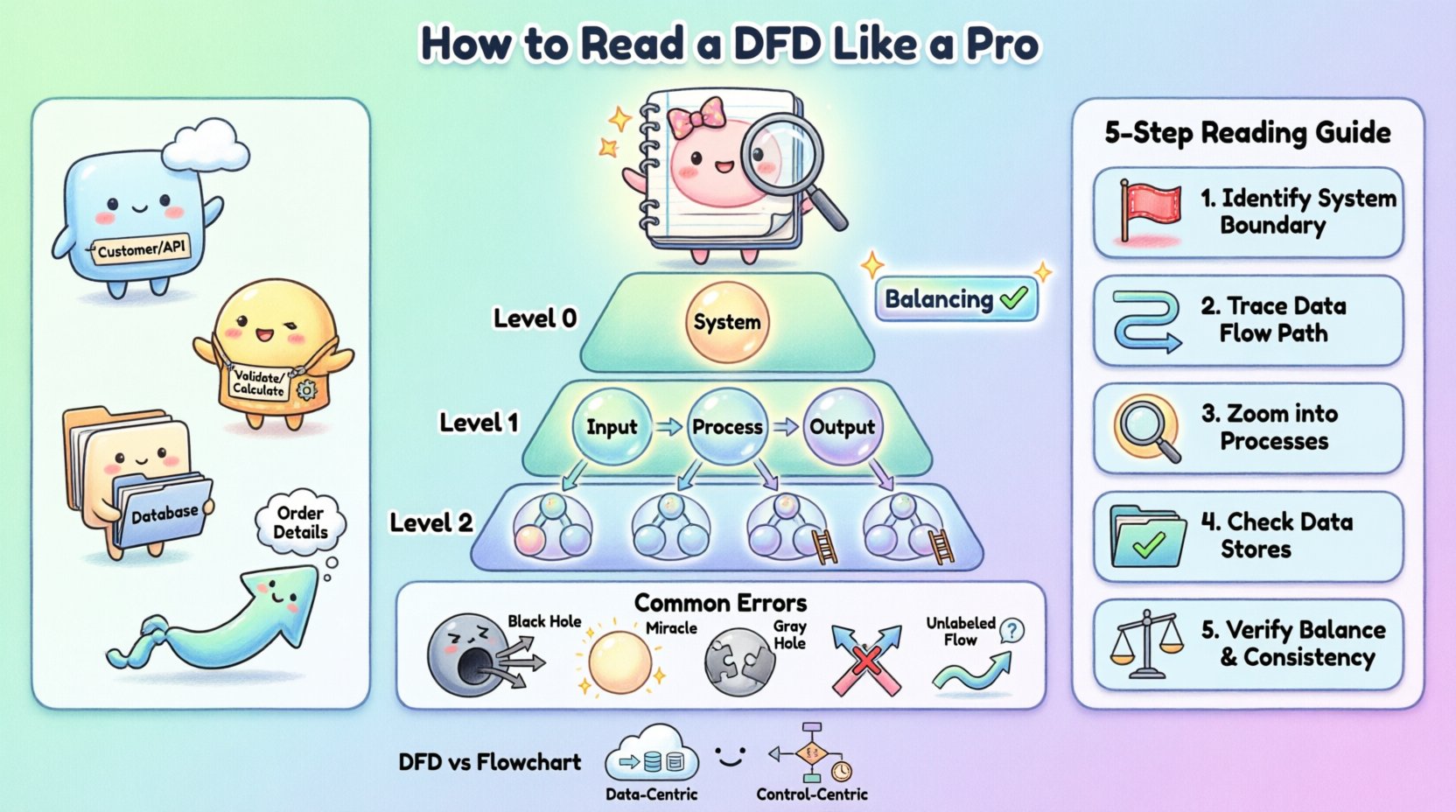
जटिल प्रणालियों को एक ही आरेख में दर्शाया नहीं जा सकता है, वरना वे पढ़ने योग्य नहीं बन जाएंगे। जटिलता को प्रबंधित करने के लिए DFD को पदानुक्रमिक रूप से व्यवस्थित किया जाता है। इस दृष्टिकोण के द्वारा आप प्रणाली में जूम इन और आउट कर सकते हैं, आवश्यकतानुसार उच्च स्तरीय तर्क या विस्तृत विवरण पर ध्यान केंद्रित कर सकते हैं।
संदर्भ आरेख उच्चतम स्तर के सारांश को प्रदान करता है। यह प्रणाली को एकल प्रक्रिया बबल के रूप में दिखाता है और यह बताता है कि यह बाहरी एजेंसियों के साथ कैसे बातचीत करती है। यहां कोई आंतरिक डेटा स्टोर या उप-प्रक्रियाएं नहीं दिखाई गई हैं। लक्ष्य प्रणाली की सीमाओं को परिभाषित करना है। आप प्रणाली को केंद्र में देखेंगे, जो उन एजेंसियों से घिरी हुई है जो इसे डेटा देती हैं और इससे डेटा प्राप्त करती हैं। यह प्रोजेक्ट के दायरे को समझने के लिए आपको पहले देखने वाला आरेख है।
इसे शीर्ष स्तर के आरेख के रूप में भी जाना जाता है, यह संदर्भ आरेख से एकल प्रणाली बबल को मुख्य उप-प्रणालियों या मुख्य प्रक्रियाओं में विभाजित करता है। यह मुख्य डेटा स्टोर और इन मुख्य कार्यों के बीच डेटा के उच्च स्तरीय प्रवाह को उजागर करता है। यह स्तर सॉफ्टवेयर के मुख्य मॉड्यूल और उनके बीच के संबंध को समझने के लिए आवश्यक है।
ये आरेख आगे के विघटन का प्रतिनिधित्व करते हैं। स्तर 1 आरेख स्तर 0 आरेख में दिखाए गए प्रक्रियाओं को विस्तार से दर्शाता है। स्तर 2 आरेख स्तर 1 की एक विशिष्ट प्रक्रिया में गहराई से जाता है। जैसे आप पदानुक्रम में नीचे जाते हैं, प्रक्रियाओं और डेटा स्टोर की संख्या बढ़ती है। हालांकि, निचले स्तर के आरेख पर प्रत्येक व्यक्तिगत प्रक्रिया को उच्च स्तर की प्रक्रिया के इनपुट और आउटपुट के साथ संगत होना चाहिए।
इस अवधारणा को जाना जाता है संतुलन। यदि स्तर 0 प्रक्रिया का इनपुट “आदेश डेटा” है और आउटपुट “रसीद” है, तो विघटन में प्रत्येक बच्चे प्रक्रिया को संयुक्त रूप से “आदेश डेटा” प्राप्त करने और “रसीद” उत्पन्न करने के लिए जिम्मेदार होना चाहिए। यह संगतता एक अच्छी तरह से निर्मित मॉडल का महत्वपूर्ण संकेत है।
जब आपको एक नई सुविधा या पुरानी प्रणाली के लिए DFD दिया जाता है, तो एक ही बार में पूरी छवि को याद रखने की कोशिश न करें। बजाय इसके, एक व्यवस्थित ट्रेसिंग विधि का उपयोग करें। इससे यह सुनिश्चित होता है कि आप जोड़ाव या तर्क को गलत नहीं समझेंगे।
चरण 1: सीमाओं को पहचानें।बाहरी एजेंसियों को खोजें। ये शुरुआत और अंत बिंदु हैं। खुद से पूछें, “यह प्रणाली के साथ कौन बातचीत कर रहा है?” यदि कोई प्रक्रिया किसी बाहरी एजेंसी या डेटा स्टोर से कोई जुड़ाव नहीं रखती है, तो यह एक स्वतंत्र घटक हो सकता है जिसके लिए आगे की व्याख्या की आवश्यकता हो सकती है।
चरण 2: डेटा प्रवाह का अनुसरण करें।एक विशिष्ट इनपुट, जैसे “लॉगिन अनुरोध” का चयन करें। एजेंसी से प्रक्रिया तक तीर का अनुसरण करें। फिर आउटपुट तीर का अनुसरण करके अगली प्रक्रिया या डेटा स्टोर तक जाएं। आरेख में बिना जाने के न बाहर न जाएं; एक समय में एक मार्ग का अनुसरण करें।
चरण 3: प्रक्रियाओं का विश्लेषण करें। प्रत्येक प्रक्रिया बबल के लिए पूछें, “परिवर्तन क्या है?” क्या इनपुट आउटपुट के साथ तार्किक रूप से मेल खाता है? उदाहरण के लिए, यदि एक प्रक्रिया का नाम “डिस्काउंट की गणना” है, तो सुनिश्चित करें कि इनपुट में “मूल्य” और “सदस्यता स्थिति” शामिल हों। यदि इनपुट अनुपस्थित हैं, तो आरेख अपूर्ण है।
चरण 4: डेटा स्टोर की पुष्टि करें। सुनिश्चित करें कि प्रत्येक डेटा स्टोर में कम से कम एक पढ़ने की संचालन (इनपुट फ्लो) और एक लिखने की संचालन (आउटपुट फ्लो) है, जब तक कि यह एक स्थायी रिकॉर्ड नहीं है जिसे बहुत कम बार अपडेट किया जाता है। एक डेटा स्टोर जो केवल डेटा प्राप्त करता है लेकिन कभी भी उसे नहीं जारी करता है, एक “सिंक” त्रुटि हो सकती है, जबकि एक ऐसा डेटा स्टोर जो केवल डेटा जारी करता है, एक “स्रोत” त्रुटि हो सकती है।
चरण 5: संतुलन की जांच करें। यदि आप लेवल 1 आरेख को देख रहे हैं, तो इसकी जांच इसके मातृ लेवल 0 आरेख के बारे में करें। क्या इनपुट और आउटपुट मेल खाते हैं? यदि मातृ प्रक्रिया कहती है “आदेश प्राप्त करें”, तो बच्चे की प्रक्रिया को भी “आदेश” डेटा प्राप्त करना चाहिए। यदि बच्चे की प्रक्रिया “भुगतान” को प्राप्त करती है, तो आरेख असंतुलित है।
इस क्रम का पालन करके, आप मैक्रो दृष्टिकोण से माइक्रो दृष्टिकोण की ओर बढ़ते हैं, जिससे सिस्टम आर्किटेक्चर की व्यापक समझ सुनिश्चित होती है।
यहां तक कि अनुभवी � ingineers भी DFDs बनाते समय गलतियां करते हैं। एक पाठक के रूप में, इन असामान्यताओं को पहचानने से विकास के दौरान आपको महत्वपूर्ण समय बचाने में मदद मिलेगी। इन त्रुटियों को पहचानने से आपको सिस्टम डिजाइनरों से सही प्रश्न पूछने में मदद मिलती है।
एक काला छेद तब होता है जब किसी प्रक्रिया के इनपुट होते हैं लेकिन आउटपुट नहीं होते हैं। डेटा प्रक्रिया में प्रवेश करता है और गायब हो जाता है। एक वास्तविक प्रणाली में, इसका अर्थ है कि डेटा खो रहा है। उदाहरण के लिए, यदि “उपयोगकर्ता को प्रक्रिया” एक “लॉगिन फॉर्म” प्राप्त करता है लेकिन किसी डेटाबेस या पुष्टि स्क्रीन को कोई आउटपुट नहीं उत्पन्न करता है, तो डेटा कहीं भी नहीं जा सकता है। इससे यह संकेत मिलता है कि आवश्यकता अनुपस्थित है या तर्क का मार्ग टूट गया है।
एक चमत्कार काले छेद का विपरीत है। यह एक प्रक्रिया है जो किसी भी इनपुट को प्राप्त किए बिना आउटपुट उत्पन्न करती है। एक प्रणाली “बिक्री रिपोर्ट” कैसे उत्पन्न कर सकती है बिना “बिक्री डेटा” को पढ़े? इससे यह संकेत मिलता है कि डेटा निर्वात में उत्पन्न किया जा रहा है, जो एक निर्धारक प्रणाली में असंभव है। अनुपस्थित इनपुट की पहचान करनी चाहिए और इसे डेटा स्टोर या बाहरी एकाइटी से जोड़ना चाहिए।
यह त्रुटि तब होती है जब किसी प्रक्रिया के इनपुट और आउटपुट तार्किक रूप से मेल नहीं खाते हैं, भले ही दोनों मौजूद हों। उदाहरण के लिए, यदि एक प्रक्रिया का नाम “कर की गणना” है लेकिन इनपुट “उपयोगकर्ता पता” है और आउटपुट “कुल मूल्य” है, तो परिवर्तन अपूर्ण है। कर की दर अनुपस्थित है। इसका अक्सर अनुपस्थित डेटा स्टोर या अनकनेक्टेड फ्लो की ओर इशारा करता है।
साफ DFD में, तीरों को बिना कनेक्शन के एक दूसरे को नहीं काटना चाहिए। यदि दो डेटा फ्लो क्रॉस करते हैं, तो यह अस्पष्ट हो सकता है कि क्या वे बातचीत कर रहे हैं या बस गुजर रहे हैं। जटिल आरेखों में कुछ प्रतिच्छेदन अनिवार्य है, लेकिन यह खराब लेआउट का संकेत है। एक अच्छी तरह से डिजाइन किए गए आरेख में, फ्लो को स्पष्ट रूप से रास्ता दिया जाना चाहिए ताकि भ्रम न हो।
प्रत्येक तीर को लेबल होना चाहिए। एक नाम रहित तीर का अर्थ है कि विशिष्ट डेटा सामग्री अज्ञात है। यदि आप एक डेटा स्टोर को एक प्रक्रिया से जोड़ने वाला तीर देखते हैं, तो आपको यह जानना चाहिए कि कौन सी डेटा प्राप्त की जा रही है। “डेटा” एक विशिष्ट लेबल नहीं है। इसे “ग्राहक सूची” या “सक्रिय सेशन टोकन” होना चाहिए। अस्पष्ट लेबल इंप्लीमेंटेशन त्रुटियों का मुख्य कारण हैं।
नए इंजीनियरों के लिए सबसे आम भ्रम के बिंदु में से एक डेटा फ्लो आरेख और फ्लोचार्ट के बीच का अंतर है। जब तक दोनों आकृतियों और तीरों का उपयोग करते हैं, उनका अर्थ आधारभूत रूप से अलग है।
फोकस: एक फ्लोचार्ट केंद्रित है नियंत्रण प्रवाह. यह संचालन के क्रम, निर्णय बिंदु (अगर/नहीं), और लूप को दिखाता है। यह “अगला क्या होता है?” का उत्तर देता है। एक DFD केंद्रित है डेटा प्रवाह. यह सूचना के आंदोलन को दिखाता है। यह “डेटा कहां जाता है?” का उत्तर देता है।
तर्क बनाम डेटा: एक फ्लोचार्ट में, आप निर्णय हीरे देखेंगे। एक मानक DFD में, आप ऐसा नहीं देखेंगे। एक DFD मानता है कि प्रक्रिया होती है; यह प्रक्रिया के शाखा तर्क को मॉडल नहीं करता है।
समय:फ्लोचार्ट अक्सर समयानुक्रमिक क्रम का अनुमान लगाते हैं। DFD आम तौर पर समयरहित होते हैं। एक DFD नहीं दिखाता कि कौन सी प्रक्रिया पहले होती है, जब तक कि डेटा निर्भरता द्वारा इसका अनुमान नहीं लगाया जाता है।
स्टोरेज: प्रवाह आरेख आम तौर पर डेटा स्टोरेज को स्पष्ट रूप से नहीं दिखाते हैं। DFDs डेटा स्टोर को एक मुख्य घटक के रूप में स्पष्ट रूप से मॉडल करते हैं।
इस अंतर को समझने से आप उस स्थान पर नियंत्रण तर्क ढूंढने की कोशिश करने से बचते हैं जहां कोई नहीं है। यदि आप “यदि यह, तो वह” तर्क ढूंढ रहे हैं, तो प्रवाह आरेख या प्रतिकृति को देखें। यदि आप जगह ढूंढ रहे हैं जहां डेटाबेस अपडेट होता है, तो DFD को देखें।
DFDs को पढ़ना केवल एक शैक्षणिक अभ्यास नहीं है; यह सॉफ्टवेयर इंजीनियरों के लिए दैनिक आवश्यकता है। यह कैसे इस कौशल का वास्तविक दुनिया के परिदृश्यों में अनुवाद होता है, इसके बारे में यहां बताया गया है।
1. ऑनबोर्डिंग और कोड समीक्षा: जब आप एक नई टीम में शामिल होते हैं, तो आर्किटेक्चर दस्तावेज़ीकरण में अक्सर DFDs शामिल होते हैं। उन्हें पढ़ने से आप कोड को छूने से पहले डेटा निर्भरता को समझने में सक्षम होते हैं। कोड समीक्षा के दौरान, आप जांच सकते हैं कि कार्यान्वयन आरेख के अनुरूप है या नहीं। यदि आरेख में डेटा कैश में जाने को दिखाता है, लेकिन कोड केवल डेटाबेस में लिखता है, तो आपने एक असंगति की पहचान कर ली है।
2. डिबगिंग और समस्या निवारण: जब कोई फीचर खराब होता है, तो DFD आपको डेटा के मार्ग को ट्रेस करने में मदद करता है। यदि एक उपयोगकर्ता बताता है कि उनका प्रोफाइल अपडेट नहीं हो रहा है, तो आप DFD पर “प्रोफाइल अपडेट” के प्रवाह का पालन कर सकते हैं। आप जांच सकते हैं कि कौन से प्रक्रियाएं शामिल हैं और कौन से डेटा स्टोर तक पहुंचा जा रहा है। इससे कोड में अंधेरे में खोज करने की तुलना में खोज के क्षेत्र को काफी सीमित कर दिया जाता है।
3. आवश्यकता संग्रह: उत्पाद प्रबंधकों के साथ काम करते समय, आपको अक्सर आवश्यकताओं को दृश्याकृत करने की आवश्यकता होती है। यदि आप DFDs को समझते हैं, तो आप आवश्यकताओं को बेहतर बनाने में मदद कर सकते हैं। आप विकास शुरू होने से पहले गायब डेटा प्रवाह या असंभव रूपांतरण की पहचान कर सकते हैं। इस सक्रिय दृष्टिकोण से तकनीकी देनदारी कम होती है।
4. प्रणाली एकीकरण: माइक्रोसर्विस आर्किटेक्चर में, DFDs API अनुबंधों को परिभाषित करने के लिए आवश्यक हैं। आप सेवाओं के बीच डेटा प्रवाह को मैप कर सकते हैं ताकि सुनिश्चित किया जा सके कि सेवा A का आउटपुट सेवा B के इनपुट के साथ संगत हो। इससे गलत डेटा प्रारूपों के कारण होने वाली एकीकरण विफलताओं को रोका जा सकता है।
यह सुनिश्चित करने के लिए कि आप पढ़ रहे आरेख समय के साथ उपयोगी बने रहें, निम्नलिखित प्रथाओं पर विचार करें। एक अद्यतन आरेख, कोई आरेख न होने से भी बदतर है।
उच्च स्तर पर रखें: हर चर के नाम के साथ DFD को भारी न करें। तार्किक डेटा इकाइयों पर ध्यान केंद्रित रखें। “उपयोगकर्ता इनपुट” को “नाम फील्ड मान” की तुलना में बेहतर है।
संगत नामकरण का उपयोग करें: सुनिश्चित करें कि एक आरेख में “ग्राहक” को सभी संबंधित आरेखों में “ग्राहक” कहा जाए। अलग-अलग इकाइयों को संदर्भित न करने तक “ग्राहक” या “उपयोगकर्ता” जैसे समानार्थी शब्दों से बचें।
परिवर्तन के दौरान अद्यतन करें: यदि कोड में महत्वपूर्ण परिवर्तन होते हैं, तो DFD को अद्यतन किया जाना चाहिए। एक संस्करण नियंत्रित आरेख प्रणाली के विकास के इतिहास के रूप में कार्य कर सकता है।
जटिलता को सीमित करें: यदि एक आरेख बहुत भारी हो जाता है, तो उसे निम्न स्तर के आरेखों में विभाजित करने का समय आ गया है। एक अच्छा नियम यह है कि लेवल 0 आरेख में 7 से 10 तक के अधिक प्रमुख प्रक्रियाएं नहीं होनी चाहिए।
डेटा प्रवाह आरेखों के व्याख्या को समझने के लिए धैर्य और अभ्यास की आवश्यकता होती है। इसमें प्रतीकों से आगे बढ़कर उनके बीच तार्किक संबंधों को समझना शामिल है। डेटा के आंदोलन पर ध्यान केंद्रित करके, असामान्यताओं की पहचान करके और पदानुक्रम को समझकर, आप अपने आप को प्रणाली विश्लेषण के लिए एक शक्तिशाली उपकरण से लैस करते हैं।
जैसे-जैसे आप अपने इंजीनियरिंग कैरियर में आगे बढ़ते हैं, आपको विभिन्न मॉडलिंग तकनीकों का सामना करना पड़ता है। DFD एक मूलभूत कौशल बना रहता है। यह आपको प्रवेश, परिवर्तन और निर्गम के संदर्भ में प्रणालियों के बारे में सोचने के लिए सिखाता है। यह मानसिकता डेटाबेस डिज़ाइन, API आर्किटेक्चर और क्लाउड इंफ्रास्ट्रक्चर योजना में लागू की जा सकती है। ओपन-सोर्स प्रोजेक्ट्स या आंतरिक दस्तावेज़ीकरण में इन आरेखों को पढ़ने का अभ्यास जारी रखें। जितना आप प्रवाह को ट्रेस करेंगे, उतना ही प्रणाली संरचना स्वाभाविक होगी।