 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











पुरानी प्रणालियाँ अक्सर संगठनों के लिए महत्वपूर्ण बुनियादी ढांचे के रूप में काम करती हैं, फिर भी वे अक्सर काले डिब्बों के रूप में मौजूद होती हैं। कोडबेस कई दशक पहले लिखे गए हो सकते हैं, जिनके दस्तावेज़ खो गए हैं, अद्यतन नहीं हुए हैं या शुरू से ही नहीं बनाए गए हैं। जब एक आधुनिक टीम को इन प्रणालियों को समझने, फिर से लिखने या स्थानांतरित करने की आवश्यकता होती है, तो दृश्यता की कमी बड़े जोखिम का कारण बनती है। यहीं पर डेटा प्रवाह आरेख (DFD) एक अनिवार्य उपकरण बन जाता है। 📊
एक DFD एक प्रणाली के माध्यम से डेटा के आवागमन का दृश्य प्रतिनिधित्व प्रदान करता है, जो विशिष्ट प्रोग्रामिंग भाषा या डेटाबेस तकनीक पर निर्भर नहीं होता है। पुरानी प्रणाली के विश्लेषण के लिए, यह कार्यान्वयन विवरणों को हटाकर मूल व्यापार तर्क को उजागर करता है। यह मार्गदर्शिका DFD के उपयोग के लिए एक संरचित, व्यावहारिक दृष्टिकोण को चित्रित करती है, जिससे पुरानी आर्किटेक्चर को समझने और आधुनिक बनाने में मदद मिलती है, बिना जोरदार बातों या सैद्धांतिक भाषा पर निर्भर हुए।
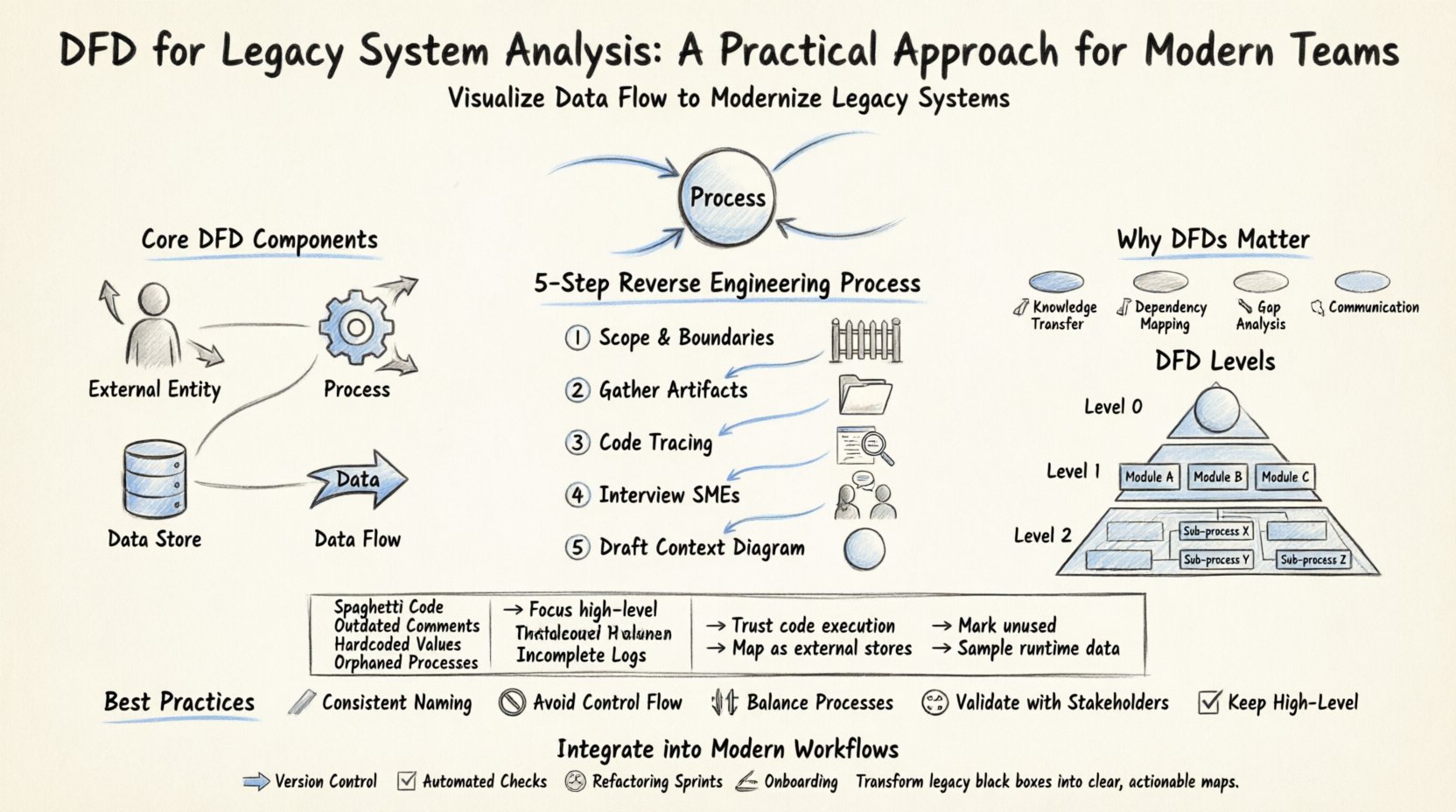
पुरानी प्रणाली के विश्लेषण में डुबकी लगाने से पहले, उपकरण के बारे में एक साझा समझ बनाना आवश्यक है। एक डेटा प्रवाह आरेख एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का ग्राफिकल प्रतिनिधित्व है। फ्लोचार्ट के विपरीत, जो नियंत्रण प्रवाह और निर्णय तर्क पर ध्यान केंद्रित करता है, DFD डेटा के आवागमन पर ध्यान केंद्रित करता है। यह प्रणाली के इनपुट, प्रसंस्करण, भंडारण और आउटपुट को नक्शा बनाता है।
DFD के मुख्य घटकों में शामिल हैं:
जब एक पुरानी प्रणाली का विश्लेषण कर रहे हों, तो तुरंत एक सही, पाठ्यपुस्तक-मानक आरेख बनाना आवश्यक नहीं है। लक्ष्य एक नक्शा बनाना है जो इंजीनियरिंग टीम को मौजूदा कोडबेस की जटिलता को समझने और नेविगेट करने में सक्षम बनाए।
आधुनिक विकास विधियाँ लचीलेपन और गति पर जोर देती हैं, लेकिन पुरानी प्रणालियाँ अक्सर धीमी गति से चलती हैं। पुराने कोड के लिए आरेख बनाने में समय लगाने का क्या फायदा? यहाँ मुख्य कारण हैं:
एक पुरानी प्रणाली के लिए DFD बनाना उलटा इंजीनियरिंग की प्रक्रिया है। आप आउटपुट से वापस जाकर इनपुट और प्रसंस्करण को समझने का काम कर रहे हैं। इसके लिए जटिलता से बचने के लिए एक अनुशासित दृष्टिकोण की आवश्यकता होती है।
सबसे पहले यह निर्धारित करें कि प्रणाली के अंदर क्या है और बाहर क्या है। एक पुराने एप्लिकेशन के लिए, सीमा एप्लिकेशन सर्वर हो सकती है, या इसमें डेटाबेस और मिडलवेयर भी शामिल हो सकते हैं। सीमा को स्पष्ट रूप से चिह्नित करने से विश्लेषण के दौरान सीमा के विस्तार (स्कोप क्रीप) को रोका जा सकता है। 🚧
किसी भी मौजूदा दस्तावेज़ की खोज करें, भले ही वह अप्रचलित हो। निम्नलिखित खोजें:
ये दस्तावेज़ आपके प्रारंभिक आरेख के आधार के रूप में कार्य करते हैं। 📂
डेटा पथ का पता लगाने के लिए स्थिर विश्लेषण उपकरणों का उपयोग करें। प्रवेश बिंदुओं (कंट्रोलर, मुख्य कार्य) की पहचान करें और तर्क के माध्यम से डेटा का अनुसरण करें। निम्नलिखित खोजें:
इस चरण में अक्सर उच्च स्तरीय मान्यताओं के बजाय गहन कोड जांच की आवश्यकता होती है। 🧐
अगर कोई मूल टीम सदस्य बचे हैं, तो उनसे साक्षात्कार करें। निम्नलिखित प्रश्न पूछें:
मानवीय संदर्भ कोड द्वारा समझाए न जा सकने वाले अंतराल को भरता है। 👥
सबसे ऊंचे स्तर के दृश्य से शुरू करें। यह प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और बाहरी एजेंसियों के साथ इसके बातचीत को दर्शाता है। विवरण में डूबने से पहले इससे सीमा निर्धारित होती है। 🌐
DFD हीरार्किक होते हैं। उच्च स्तर से निम्न स्तर तक जाने से जटिलता का प्रबंधन करने में मदद मिलती है। लीगेसी विश्लेषण में, आपको हर एक कोड लाइन को मैप करने की आवश्यकता नहीं हो सकती, लेकिन आपको महत्वपूर्ण मार्गों को मैप करना चाहिए।
यह शीर्ष स्तर का दृश्य है। इसमें पूरी प्रणाली का प्रतिनिधित्व करने वाली एक प्रक्रिया होती है। यह मुख्य इनपुट और आउटपुट दिखाता है। यह स्टेकहोल्डर्स के लिए प्रणाली की सीमा समझने में उपयोगी है।
यह मुख्य प्रक्रिया को मुख्य उप-प्रक्रियाओं में बांटता है। लीगेसी प्रणाली के लिए, ये मुख्य कार्यात्मक मॉड्यूल (जैसे बिलिंग, इन्वेंटरी, रिपोर्टिंग) के संबंध में हो सकते हैं। इस स्तर में मोनोलिथ के किन भागों को अलग किया या मॉड्यूलर बनाया जा सकता है, इसकी पहचान करने में मदद मिलती है। 🧩
यह विशिष्ट उप-प्रक्रियाओं में गहराई से जाता है। यह विशिष्ट डेटा समस्याओं के निराकरण या जटिल रूपांतरण को समझने में उपयोगी है। हालांकि, बहुत सारे आरेख बनाने से सावधान रहें, क्योंकि वे बनाए रखने में कठिन हो जाते हैं। 📄
लीगेसी प्रणालियों के साथ काम करना विशिष्ट बाधाओं को प्रस्तुत करता है। नीचे सामान्य समस्याओं और उन्हें दूर करने के व्यावहारिक रणनीतियों का विश्लेषण दिया गया है।
| चुनौती | विश्लेषण पर प्रभाव | व्यावहारिक समाधान |
|---|---|---|
| 🧩 स्पैगेटी कोड | डेटा फ्लो लॉजिक का पता लगाना मुश्किल है। | सबसे पहले उच्च स्तरीय मॉड्यूल पर ध्यान केंद्रित करें; आवश्यकता पड़ने तक निम्न स्तरीय तर्क को नजरअंदाज करें। |
| 📅 अद्यतन नहीं किए गए कमेंट्स | कोड के कमेंट्स वर्तमान व्यवहार के विपरीत हो सकते हैं। | कमेंट्स को नजरअंदाज करें; वास्तविक कोड निष्पादन मार्गों और डेटाबेस स्थितियों पर भरोसा करें। |
| 🔒 कड़े मूल्य | कॉन्फ़िगरेशन कोड में दबा हुआ है। | सभी कड़े मूल्य वाले मार्गों की पहचान करें और उन्हें DFD में बाहरी डेटा स्टोर के रूप में मानचित्रित करें। |
| 👻 असंगत प्रक्रियाएँ | तर्क मौजूद है लेकिन कभी भी कॉल नहीं किया जाता है। | इन्हें निर्माण योजना में सहायता के लिए आरेख में “अनउपयोगी” के रूप में चिह्नित करें। |
| 📉 अपूर्ण लॉग | ऐतिहासिक डेटा फ्लो का पता लगाना मुश्किल है। | फ्लो पैटर्न का अनुमान लगाने के लिए वर्तमान रनटाइम डेटा नमूनाकरण का उपयोग करें। |
DFD बनाना एक बार का कार्य नहीं है। इसे आधुनिक विकास चक्र में फिट होना चाहिए। यहां विश्लेषण को संबंधित रखने के तरीके दिए गए हैं:
DFD को एक उपयोगी संपत्ति बनाए रखने के लिए बोझ न बनने देने के लिए इन बेस्ट प्रैक्टिसेज का पालन करें:
DFD के लिए सबसे बड़ा जोखिम अप्रचलित होना है। एक बार बनाए गए और कभी छूए न जाने वाले आरेख का अंततः झूठ बन जाना है। इससे बचने के लिए:
पुरानी प्रणालियाँ प्राकृतिक रूप से जटिल होती हैं। वे समय के साथ विशेषताओं को एकत्र करती हैं, अक्सर एक सुसंगत डिजाइन रणनीति के बिना। DFD इस जाल को सुलझाने में मदद करता है। डेटा को दृश्यमान बनाकर, आप निर्धारित कर सकते हैं:
यह याद रखना महत्वपूर्ण है कि DFD एक मॉडल है, प्रणाली नहीं। यह एक सरलीकरण है। लक्ष्य इतनी विस्तार से विवरण लेना है कि उपयोगी हो, लेकिन छोटे-छोटे विवरण में खो न जाए। यदि आरेख कोड के जितना जटिल बन जाता है, तो इसका उद्देश्य विफल हो जाता है। सरलता ही अंतिम सूक्ष्मता है। 🎨
पुराने सिस्टम विश्लेषण के लिए DFD रणनीति को लागू करना एक मैराथन है, न कि एक दौड़। इसमें धैर्य, विस्तार से ध्यान देने और कोड के साथ गहराई से जुड़ने की इच्छा की आवश्यकता होती है। हालांकि, इसका लाभ बहुत बड़ा है। टीमों को दृश्यता मिलती है, जोखिम कम होता है, और आधुनिकीकरण का रास्ता स्पष्ट हो जाता है।
DFD को एक जीवंत दस्तावेज के रूप में मानते हुए और इसे अपनी मानक इंजीनियरिंग प्रथाओं में शामिल करके, आप एक स्थिर आरेख को एक गतिशील संपत्ति में बदल देते हैं। इस दृष्टिकोण से यह सुनिश्चित होता है कि पुराना सिस्टम समझा जाए, बनाए रखा जाए और अंततः आत्मविश्वास के साथ स्थानांतरित किया जाए। कोड पुराना हो सकता है, लेकिन इसके द्वारा उत्पन्न समझ आधुनिक और क्रियान्वयन योग्य है। 🚀