 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











सिस्टम इंटीग्रेशन आधुनिक डिजिटल इंफ्रास्ट्रक्चर की रीढ़ है। यह अलग-अलग एप्लिकेशन, डेटाबेस और सेवाओं को एक समेकित इकाई के रूप में काम करने के लिए जोड़ता है। हालांकि, इन सिस्टमों के बीच आने-जाने वाले डेटा की जटिलता जल्दी ही अदृश्य हो सकती है। इसी बिंदु पर डेटा फ्लो डायग्राम (DFD) का उपयोग अनिवार्य हो जाता है। DFD एक सिस्टम में डेटा के यात्रा के तरीके का दृश्य प्रतिनिधित्व प्रदान करता है, जिसमें इनपुट, प्रक्रियाएं, स्टोरेज और आउटपुट को उजागर किया जाता है। सिस्टम इंटीग्रेशन पर लागू करने पर, यह डेटा लाइनेज और निर्भरताओं को समझने के लिए एक नक्शा के रूप में कार्य करता है।
एक स्पष्ट नक्शे के बिना, इंटीग्रेशन परियोजनाओं को डेटा असंगतियों, सुरक्षा कमजोरियों और बॉटलनेक का खतरा होता है। कई घटकों के माध्यम से डेटा को दृश्यमान बनाकर, वास्तुकार और इंजीनियर उन खामियों को पहले ही पहचान सकते हैं, जो आलाप विफलताओं में बदल सकती हैं। यह मार्गदर्शिका जटिल सिस्टमों के इंटीग्रेशन के संदर्भ में विशेष रूप से DFD के उपयोग की विधि का अध्ययन करती है।
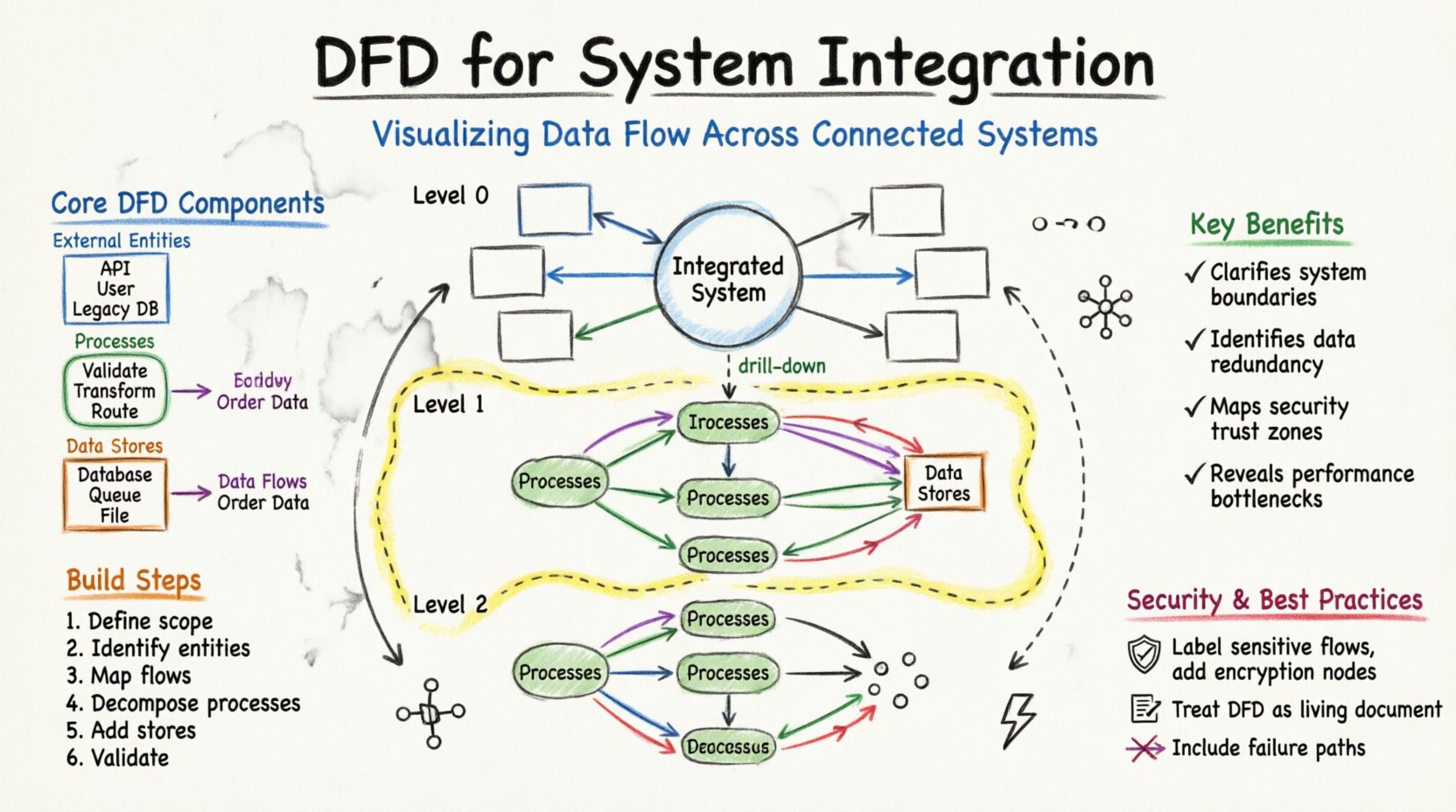
इंटीग्रेशन के विशिष्ट पहलुओं में डूबने से पहले, DFD के मूल निर्माण तत्वों को समझना आवश्यक है। ये तत्व सिस्टम की जटिलता के बावजूद स्थिर रहते हैं।
DFD के फ्लोचार्ट से अंतर स्पष्ट करना महत्वपूर्ण है। फ्लोचार्ट केंद्रित होते हैं नियंत्रण प्रवाह और निर्णय तर्क (if/else पथ) पर। DFD केवल डेटा के आंदोलन पर केंद्रित होते हैं। सिस्टम इंटीग्रेशन में, डेटा अखंडता को लेकर लिए गए विशिष्ट निर्णय पथ से अधिक महत्वपूर्ण होती है। इसलिए, डेटा रूपांतरण पाइपलाइन के नक्शा बनाने के लिए DFD प्राथमिक उपकरण है।
जब कई सिस्टम आपस में संचार करने की आवश्यकता महसूस करते हैं, तो आर्किटेक्चर अक्सर एक जाल की तरह दिखता है। एक केंद्रीय दृश्यमानता के बिना, जोड़ाव एक भारी जाल में बदल सकते हैं। DFD जानकारी को परतों में व्यवस्थित करके इस जटिलता को स्पष्ट करने में मदद करता है।
जटिलता को प्रबंधित करने के लिए, DFD को आमतौर पर विभिन्न स्तरों के अमूर्तता पर बनाया जाता है। इस पदानुक्रम के कारण स्टेकहोल्डर्स को सिस्टम को उच्च स्तर के दृश्य से लेकर विशिष्ट तकनीकी विवरण तक देखने की अनुमति मिलती है।
संदर्भ आरेख अधिकतम अमूर्तता का स्तर है। इसमें पूरे एकीकृत सिस्टम को एकल प्रक्रिया के रूप में लिया जाता है। यह सिस्टम के बाहरी एजेंसियों के साथ बातचीत को दर्शाता है।
यह आरेख मुख्य प्रक्रिया को प्रमुख उप-प्रक्रियाओं में बांटता है। यह इंटीग्रेशन वास्तुकारों के लिए मुख्य नक्शा है।
स्तर 2 आरेख स्तर 1 से विशिष्ट उप-प्रक्रियाओं में गहराई से जाते हैं। इनका उपयोग विकासकर्मी और इंजीनियर करते हैं जो विशिष्ट तर्क कार्यान्वयन करते हैं।
एक टिकाऊ डीएफडी बनाने के लिए एक संरचित दृष्टिकोण की आवश्यकता होती है। यह सिर्फ एक ड्राइंग एक्सरसाइज नहीं है, बल्कि व्यापार तर्क को समझने की आवश्यकता वाली एक मॉडलिंग गतिविधि है।
इंटीग्रेशन में भाग लेने वाले सभी प्रणालियों की सूची बनाने से शुरुआत करें। डेटा उत्पन्न करने वाली प्रणालियों और उसे उपयोग करने वाली प्रणालियों के बीच अंतर करें। संगठनात्मक सीमा को परिभाषित करें। कौन से डेटा प्रवाह आंतरिक हैं, और कौन से सार्वजनिक क्षेत्र में जाते हैं?
प्रत्येक स्रोत और गंतव्य की सूची बनाएं। इसमें शामिल है:
केंद्रीय प्रणाली से संबंधित एकता को जोड़ने वाली तीर खींचें। इन प्रवाहों को गतिशील डेटा के प्रकार (उदाहरण के लिए, “आदेश विवरण”, “इन्वेंटरी स्थिति”) के साथ लेबल करें। अभी आंतरिक तर्क के बारे में चिंता न करें। गति पर ध्यान केंद्रित करें।
केंद्रीय प्रणाली को तार्किक प्रक्रियाओं में विभाजित करें। उदाहरण के लिए, “आदेश संभालें” नामक एक प्रक्रिया के बजाय, इसे “आदेश की पुष्टि करें”, “इन्वेंटरी जांचें”, और “भुगतान प्रक्रिया” में विभाजित करें। इस विभाजन से पता चलता है कि डेटा कहाँ पर बदला जाता है।
यह पहचानें कि डेटा कहाँ संग्रहीत किया जाना चाहिए। एकीकरण में, यह अस्थायी स्टेजिंग क्षेत्र या स्थायी गोदाम हो सकता है। सुनिश्चित करें कि प्रत्येक डेटा स्टोर को एक प्रक्रिया से जुड़ा हो जो उसमें लिखती है और एक प्रक्रिया से जुड़ा हो जो उसमें से पढ़ती है।
सामान्य त्रुटियों की जांच करें। सुनिश्चित करें कि कोई भी डेटा प्रवाह किसी निर्जीव स्थान से शुरू या समाप्त नहीं होता है। प्रत्येक तीर का एक शुरुआत और एक समाप्ति होनी चाहिए। सुनिश्चित करें कि जब डेटा को स्थायी रूप से रखने की आवश्यकता होती है, तो डेटा स्टोर को छोड़ा नहीं जाता है।
एकीकरण के लिए DFD बनाना कोई बाधाओं से रहित नहीं है। डेटा असंगति और छिपे हुए निर्भरताएँ सामान्य जाल हैं। नीचे दी गई तालिका में आम समस्याओं और उन्हें दूर करने के लिए सुझाए गए तरीकों का वर्णन किया गया है।
| चुनौती | विवरण | समाधान |
|---|---|---|
| डेटा अतिरेक | कई प्रणालियाँ स्वतंत्र रूप से एक ही ग्राहक जानकारी संग्रहीत करती हैं। | जहां संभव हो, DFD में डेटा स्टोर को एकल सत्य स्रोत में संगठित करें। |
| छिपे हुए निर्भरताएँ | डेटा प्रवाह पृष्ठभूमि कार्यों पर निर्भर होते हैं जो आरेख में दिखाई नहीं देते। | असमान गति वाली प्रक्रियाओं और पृष्ठभूमि कार्यों को DFD में स्पष्ट प्रक्रियाओं के रूप में शामिल करें। |
| सुरक्षा के अंतराल | एन्क्रिप्ट नहीं किए गए डेटा सार्वजनिक नेटवर्कों के माध्यम से प्रवाहित होते हैं। | सुरक्षित प्रवाहों को लेबल करें और नेटवर्क सीमाओं पर एन्क्रिप्शन प्रक्रियाओं को लागू करें। |
| पुरानी प्रणाली के इंटरफेस | पुरानी प्रणालियों में मानक API नहीं होते हैं। | डेटा प्रारूपों के अनुवाद के लिए आवश्यक व्रैपर या मिडलवेयर को मॉडल करें। |
| आयतन शिखर | शीर्ष समय के दौरान डेटा प्रवाह अप्रत्याशित रूप से बढ़ जाता है। | प्रक्रिया से पहले ट्रैफिक शिखर को अवशोषित करने के लिए बफरिंग डेटा स्टोर जोड़ें। |
DFD को समय के साथ उपयोगी बनाए रखने के लिए, इन डिज़ाइन सिद्धांतों का पालन करें। एक आरेख जो बहुत जटिल हो जाता है, उसे पढ़ना मुश्किल हो जाता है; एक आरेख जो बहुत सरल हो जाता है, वह असही हो जाता है।
प्रणाली एकीकरण में डेटा के ठीक वैसे ही आने-जाने की बहुत कम संभावना होती है। फॉर्मेट बदलते हैं, फ़ील्ड जोड़े जाते हैं, और मानों की गणना की जाती है। DFD को इन रूपांतरणों को दर्शाना चाहिए।
जब डेटा एक प्रणाली में प्रवेश करता है, तो इसे आमतौर पर मानकीकृत करने की आवश्यकता होती है। उदाहरण के लिए, एक प्रणाली में तारीख का फॉर्मेट “DD/MM/YYYY” हो सकता है और दूसरी प्रणाली में “YYYY-MM-DD” हो सकता है। DFD में विशेष रूप से “फॉर्मेट मानकीकरण” के लिए एक प्रक्रिया नोड दिखाना चाहिए।
कभी-कभी डेटा को अन्य स्रोतों के साथ मिलाकर मूल्य जोड़ा जाता है। उदाहरण के लिए, एक आदेश को वर्तमान विनिमय दरों के साथ समृद्ध किया जा सकता है। इसके लिए एक प्रक्रिया की आवश्यकता होती है जो एक द्वितीयक स्रोत (जैसे मुद्रा भंडार) से डेटा निकालती है और इसे मुख्य प्रवाह के साथ मिलाती है।
सुरक्षा आवश्यकताएं अक्सर यह निर्धारित करती हैं कि संवेदनशील डेटा को छिपाया जाए। यदि कोई प्रक्रिया डेटा को लॉगिंग प्रणाली में भेजती है, तो DFD में एक रूपांतरण चरण दिखाना चाहिए जो डेटा के सुरक्षित क्षेत्र से बाहर निकलने से पहले क्रेडिट कार्ड नंबर या सामाजिक सुरक्षा संख्या को मास्क करे।
विभिन्न आर्किटेक्चरल पैटर्न डेटा प्रवाह का अलग-अलग तरीके से उपयोग करते हैं। इन पैटर्नों को समझने में सही DFD बनाने में मदद मिलती है।
DFD एक बार के लिए बनाया गया तत्व नहीं है। प्रणालियाँ विकसित होती हैं, नए APIs लाए जाते हैं, और पुराने अप्रचलित हो जाते हैं। जुड़े हुए आरेख के कारण बग और सुरक्षा उल्लंघन हो सकते हैं। रखरखाव DFD जीवनचक्र का एक महत्वपूर्ण चरण है।
DFD में अद्यतन को निम्न बातों द्वारा प्रेरित किया जाना चाहिए:
आरेख को कोडबेस या कॉन्फ़िगरेशन फ़ाइलों से जोड़े रखें। जब कोई डेवलपर डेटा मैपिंग स्क्रिप्ट में परिवर्तन करता है, तो वह एक साथ DFD को भी अद्यतन करे। इससे यह सुनिश्चित होता है कि दस्तावेज़ीकरण सच्चाई का स्रोत बना रहे।
सुरक्षा एक अतिरिक्त चीज़ नहीं है; यह डेटा प्रवाह का एक मूलभूत पहलू है। जब डेटा को दृश्यीकृत करते हैं, तो आपको यह विचार करना होगा कि विश्वास सीमाएँ कहाँ मौजूद हैं।
व्यावहारिक अनुप्रयोग को समझाने के लिए एक परिदृश्य पर विचार करें जहाँ एक कंपनी वेबसाइट, मोबाइल ऐप और एक भौतिक दुकान के माध्यम से उत्पाद बेचती है।
एकाइयाँ वेबसाइट, मोबाइल ऐप, POS प्रणाली और ग्राहक शामिल हैं।
मुख्य प्रक्रियाएँ “आदेश प्राप्ति”, “स्टॉक घटाना” और “भुगतान प्रक्रिया” शामिल हैं।
जब कोई ग्राहक एक वस्तु खरीदता है:
इस विज़ुअलाइज़ेशन से स्पष्ट होता है कि यदि इन्वेंटरी स्टोर बंद है, तो ऑर्डर इनग्रेशन सफल हो सकती है लेकिन फुलफिलमेंट विफल हो जाएगी। यह निर्भरता केवल आरेख के माध्यम से दिखाई देती है।
डेटा फ्लो डायग्राम जटिल सिस्टम इंटीग्रेशन के भीतर जानकारी के आंदोलन को समझने का एक संरचित तरीका प्रदान करते हैं। वे स्थापित कोड और API कॉल्स को स्टेकहोल्डर्स द्वारा समझे जा सकने वाली दृश्य भाषा में बदल देते हैं। यहां बताए गए चरणों का पालन करके टीमें अपनी डेटा आर्किटेक्चर के सटीक मानचित्र बना सकती हैं।
प्रभावी डीएफडी बेहतर सिस्टम डिज़ाइन, कम इंटीग्रेशन त्रुटियों और स्पष्ट सुरक्षा सीमाओं की ओर जाते हैं। वे विकास और रखरखाव को मार्गदर्शन करने वाले एक जीवंत दस्तावेज़ के रूप में कार्य करते हैं। एक ऐसे वातावरण में जहां डेटा सबसे मूल्यवान संपत्ति है, इसके यात्रा को दृश्य रूप से दिखाना वैकल्पिक नहीं है—यह संचालन उत्कृष्टता के लिए एक आवश्यकता है।