 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











प्रणाली विश्लेषण कई वर्षों से जटिल तर्क को समझाने के लिए दृश्य प्रतिनिधित्व पर निर्भर रहा है। डेटा फ्लो डायग्राम (DFD) इस प्रथा की एक मूल बात बनी हुई है। हालांकि, सॉफ्टवेयर आर्किटेक्चर का माहौल बहुत बदल गया है। हमने एकल ब्लॉक एप्लिकेशन से वितरित माइक्रोसर्विसेज में, स्थानीय डेटाबेस से क्लाउड-नेटिव स्टोरेज में और सिंक्रोनस रिक्वेस्ट से एसिंक्रोनस इवेंट स्ट्रीम में स्थानांतरित किया है। पारंपरिक DFD, जो सरल, रेखीय प्रक्रियाओं के लिए डिज़ाइन किया गया था, इन परिस्थितियों में नए चुनौतियों का सामना कर रहा है। यह गाइड यह अन्वेषण करता है कि विधि कैसे विकसित हो रही है ताकि वह संबंधित रहे और सटीक मॉडलिंग सुनिश्चित हो, जिससे वह अप्रासंगिक न हो जाए। 🛠️
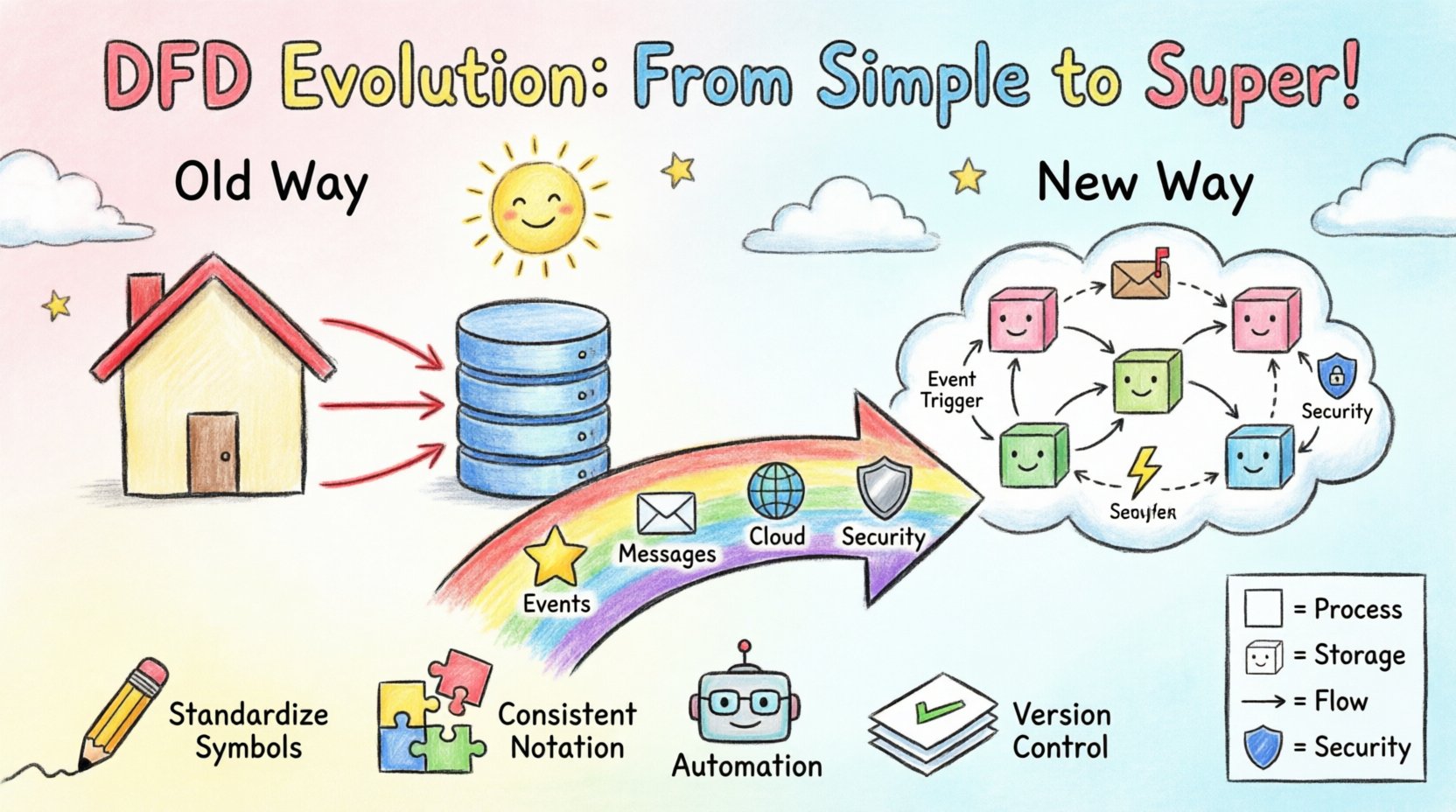
विकास की जांच करने से पहले, आधार रेखा तय करना आवश्यक है। एक मानक DFD प्रणाली के माध्यम से जानकारी के प्रवाह को दृश्य रूप से दर्शाता है। यह क्या प्रणाली करती है, न कि कैसे यह करती है। इस अंतर के कारण प्रक्रिया मॉडलिंग और संरचनात्मक डिज़ाइन में अंतर होता है। मूल घटक पीढ़ियों भर तक स्थिर रहते हैं:
पारंपरिक संदर्भ में, इन डायग्राम को पदानुक्रमित बनाया जाता था। एक संदर्भ डायग्राम एक उच्च स्तरीय दृश्य (स्तर 0) प्रदान करता था, जिसे बाद में विस्तृत स्तर 1 और स्तर 2 डायग्राम में विभाजित किया जाता था। जब एक प्रणाली का स्पष्ट आरंभ और अंत होता था और डेटा इनपुट से आउटपुट तक भविष्यवाणी के अनुसार आगे बढ़ता था, तो यह अच्छी तरह से काम करता था। हालांकि, आधुनिक प्रणालियों में अक्सर एकल प्रवेश बिंदु या निश्चित निकास नहीं होता है। डेटा लगातार प्रवेश और निकास करता है, अक्सर रियल-टाइम में। 🔄
मोनोलिथ से वितरित प्रणालियों की ओर बदलाव स्थिर मॉडलिंग के लिए घर्षण लाता है। एक मोनोलिथिक एप्लिकेशन में, डेटाबेस ट्रांजैक्शन एक फंक्शन कॉल की श्रृंखला को तुरंत सक्रिय कर सकता है। DFD डेटाबेस से प्रक्रिया तक और फिर आउटपुट तक सीधी रेखा खींच सकता है। माइक्रोसर्विस पर्यावरण में, परिदृश्य बहुत अधिक जटिल है।
आधुनिक प्रणालियाँ अक्सर मैसेज ब्रोकर और कतारों पर निर्भर रहती हैं। एक रिक्वेस्ट प्राप्त होती है, एक कतार में संग्रहीत की जाती है, और बाद में एक वर्कर द्वारा प्रोसेस की जाती है। पारंपरिक DFDs समय का प्रतिनिधित्व करने में कठिनाई महसूस करते हैं। वे तुरंत प्रवाह का अनुमान लगाते हैं। एक स्थिर तीर आसानी से नहीं दर्शाता कि डेटा अगली प्रक्रिया शुरू करने से पहले घंटों तक बफर में रह सकता है। इससे प्रणाली व्यवहार विश्लेषण में अस्पष्टता आती है।
क्लाउड आर्किटेक्चर अक्सर राज्यहीन कंटेनर का उपयोग करते हैं जो चालू और बंद होते हैं। एक DFD आमतौर पर स्थायी प्रक्रिया का अनुमान लगाता है। जब प्रक्रिया अस्थायी होती है, तो डायग्राम में स्पष्ट करना आवश्यक है कि राज्य कहाँ रखा जाता है (डेटा स्टोर) और तर्क कहाँ स्थित है (गणना)। यदि डायग्राम दोनों के बीच अंतर नहीं करता है, तो डेवलपर्स गलती से मान सकते हैं कि राज्य प्रक्रिया के भीतर बनाए रखा जाता है, जिससे बग आते हैं।
पुराने मॉडल अक्सर डेटा स्टोर को सामान्य बॉक्स के रूप में मानते थे। आधुनिक संगतता के लिए यह समझना आवश्यक है कि डेटा कहाँ भौगोलिक रूप से स्थित है और इसे कैसे एन्क्रिप्ट किया जाता है। अब एक DFD को डेटा स्वायत्तता और सुरक्षा स्तर को दर्शाना आवश्यक है। यदि डेटा प्रवाह सुरक्षा क्षेत्र को पार करता है, तो डायग्राम में उस सीमा को दर्शाना चाहिए, केवल तार्किक कनेक्शन के बजाय।
इन अंतरालों को दूर करने के लिए, व्यवसायिक व्यक्ति आयोजित आर्किटेक्चर (EDA) के अनुकूल बनाने के लिए मानक नोटेशन को बदल रहे हैं। मूल अवधारणा डेटा के प्रवाह की बनी रहती है, लेकिन ट्रिगर बदल जाते हैं।
इस अनुकूलन के लिए दृष्टिकोण में परिवर्तन की आवश्यकता होती है। आरेख अब सिस्टम का केवल एक नक्शा नहीं है; यह है एक नक्शा घटनाएं जो सिस्टम को आगे बढ़ाती हैं। यह स्टेकहोल्डर्स को डेटा के जीवनचक्र को समझने में मदद करता है, जिसमें रचना से अंतिम उपभोग तक के सभी चरण शामिल हैं, साथ ही बीच के रुकावटों को भी। 🕒
जैसे-जैसे एप्लीकेशन क्लाउड की ओर बढ़ते हैं, DFD को API कॉन्ट्रैक्ट और सेवा सीमाओं के साथ मेल खाना चाहिए। आरेख व्यापार आवश्यकताओं और तकनीकी कार्यान्वयन के बीच सेतु के रूप में कार्य करता है।
अधिकांश आधुनिक सिस्टम एक API गेटवे को उजागर करते हैं। DFD में, इससे सामान्य “बाहरी एकाई” का स्थान ले लिया जाता है। गेटवे एक विशिष्ट प्रक्रिया बन जाता है जो रूटिंग, प्रमाणीकरण और दर सीमा के लिए जिम्मेदार होता है। आरेख में आने वाले अनुरोध के आंतरिक कमांड में रूपांतरण को दिखाना चाहिए। इससे चिंताओं के विभाजन को स्पष्ट करने में मदद मिलती है।
वितरित डेटाबेस में, डेटा अक्सर शेड (sharded) होता है। एक पारंपरिक डेटा स्टोर संकेत अपर्याप्त है। आरेख में इंगित करना चाहिए कि एक प्रक्रिया कई शेड्स को प्रश्न कर सकती है ताकि एक प्रतिक्रिया तैयार की जा सके। इससे पढ़ने के ऑपरेशन की जटिलता को लिखने के ऑपरेशन के बीच दिखाया जा सकता है। उदाहरण के लिए, लिखने के लिए एक पार्टीशन में जाना हो सकता है, जबकि पढ़ने के लिए तीन से जुड़ना हो सकता है।
सेवाएं अक्सर डिज़ाइन समय दूसरी सेवाओं के नेटवर्क पते के बारे में नहीं जानती हैं। वे रनटाइम पर उन्हें खोजती हैं। DFD इसे “सेवा रजिस्ट्री” नोड का उपयोग करके दर्शा सकता है। प्रक्रियाएं रजिस्ट्री से जुड़ती हैं ताकि एक निर्भर सेवा के वर्तमान एंडपॉइंट को खोजा जा सके। इससे तार्किक प्रवाह में इंफ्रास्ट्रक्चर दृश्यता का एक परत जोड़ी जाती है।
अंतरों को समझना टीमों को सही स्तर के सारांश चुनने में मदद करता है। निम्नलिखित तालिका आज DFD के निर्माण और व्याख्या के तरीकों में महत्वपूर्ण अंतरों को दर्शाती है, जो अतीत के तरीकों से तुलना में है।
| विशेषता | पारंपरिक DFD | आधुनिक DFD |
|---|---|---|
| प्रवाह दिशा | समकालिक, तुरंत | असमकालिक, देरी से, या बैच में |
| प्रक्रिया प्रकृति | एकल, लंबे समय तक चलने वाला | माइक्रोसर्विस, अस्थायी, राज्यहीन |
| स्टोरेज | केंद्रीकृत डेटाबेस | शेड, वितरित, या ऑब्जेक्ट स्टोरेज |
| ट्रिगर | इनपुट डेटा के आगमन | घटनाएँ, संदेश या योजित कार्य |
| सीमाएँ | प्रणाली की परिधि | सुरक्षा क्षेत्र और API गेटवे |
| समानांतरता | अक्सर उपेक्षित | स्पष्ट रूप से मॉडल किया गया (कतारें, लॉक) |
जैसे-जैसे आरेख अधिक जटिल होते हैं, पठनीयता एक जोखिम बन जाती है। निम्नलिखित प्रथाएँ सुनिश्चित करती हैं कि DFD एक उपयोगी उपकरण बनी रहे, भ्रमित वस्तु नहीं।
सुरक्षा अब एक बाद की बात नहीं है। इसे डिज़ाइन चरण में एम्बेड किया जाना चाहिए। DFD डेटा के कहाँ खुले होने के दृश्य के माध्यम से सुरक्षा जोखिमों की पहचान करने के लिए एक उत्कृष्ट उपकरण है।
हर बार डेटा एक प्रक्रिया से दूसरी प्रक्रिया में पार करता है, तो एक विश्वास सीमा पार की जाती है। आधुनिक प्रणाली में, यह एक सार्वजनिक API से आंतरिक माइक्रोसर्विस तक हो सकता है। DFD इन सीमाओं को उजागर करना चाहिए। यदि कोई प्रवाह एन्क्रिप्शन या प्रमाणीकरण के बिना सीमा पार करता है, तो आरेख तुरंत एक दुर्लभता को उजागर करता है।
सभी डेटा प्रवाह एक ही महत्व के नहीं होते हैं। संवेदनशील जानकारी जैसे PII (व्यक्तिगत रूप से पहचान योग्य जानकारी) को सख्ती से संभालने की आवश्यकता होती है। आरेख रंग कोडिंग या विशिष्ट प्रतीकों का उपयोग करके संवेदनशील प्रवाहों को चिह्नित कर सकता है। इससे यह सुनिश्चित होता है कि जब डेवलपर्स तर्क कार्यान्वित करते हैं, तो उन्हें उन विशिष्ट मार्गों के लिए एन्क्रिप्शन और पहुंच नियंत्रण को प्राथमिकता देनी होती है।
नियम जैसे GDPR या HIPAA डेटा के भंडारण और गति के तरीके को निर्धारित करते हैं। आधुनिक DFD डेटा प्रवाहों को संगतता आवश्यकताओं से मैप कर सकता है। उदाहरण के लिए, एक डेटा स्टोर को “केवल यूरोपीय क्षेत्र” लेबल किया जा सकता है। यदि कोई प्रक्रिया इस स्टोर से दूसरे क्षेत्र में डेटा निकालती है, तो आरेख एक संभावित संगतता उल्लंघन को चिह्नित करता है। इससे आर्किटेक्ट्स को कोड लिखने से पहले समस्याओं को ठीक करने का अवसर मिलता है।
DFD के साथ सबसे बड़ी चुनौती रखरखाव है। कोड में परिवर्तन होने पर आरेख अक्सर अद्यतन नहीं रहता है। आधुनिक कार्यप्रणालियाँ इस अंतर को स्वचालन के माध्यम से पार करने का प्रयास करती हैं।
जब तक पूरी तरह से स्वचालित आरेख पूर्ण नहीं हैं, वे एक आधार रेखा प्रदान करते हैं जो महीनों पहले बनाए गए एक स्थिर दस्तावेज से बहुत अधिक वास्तविकता के करीब है। यह डॉक्यूमेंटेशन को सिस्टम के अनुक्रमित होने के साथ संबंधित रखता है। 🔄
DFD का विकास चल रहा है। तकनीक विकसित होती है, तो मॉडलिंग तकनीकों का भी विकास होता है।
मशीन लर्निंग मॉडल गैर- tentative प्रवाह लाते हैं। एक प्रक्रिया संभावना के आधार पर निश्चित तर्क के बजाय अलग-अलग परिणाम उत्पन्न कर सकती है। भविष्य के DFD में निश्चयात्मकता अंतराल या प्रशिक्षण डेटा प्रवाह को निष्कर्ष डेटा प्रवाह से अलग रूप से दर्शाने की आवश्यकता हो सकती है। इससे डेटा स्टोर और प्रक्रिया नोड्स में एक नई आयाम जोड़ी जाती है।
स्थिर आरेख डिजाइन के लिए अच्छे हैं, लेकिन संचालन के लिए क्या? भविष्य के संस्करण में आरेखों को लाइव डैशबोर्ड से जोड़ा जा सकता है। यदि उत्पादन में डेटा प्रवाह अवरुद्ध हो जाता है, तो आरेख में संबंधित तीर लाल हो सकता है। इससे एक जीवंत दस्तावेज बनता है जो सिस्टम के वर्तमान स्वास्थ्य को दर्शाता है।
DFD में घटनाओं के प्रतिनिधित्व के लिए वर्तमान में कोई सार्वभौमिक मानक नहीं है। जैसे ही उद्योग विशिष्ट घटना पैटर्न (जैसे CQRS या इवेंट सोर्सिंग) पर एकता बनाता है, एक मानक संकेत सेट आमतौर पर उभरेगा। इससे आरेखों को विभिन्न टीमों और संगठनों के बीच अंतरक्रिया करने में सक्षम बनाया जाएगा।
अपनी वर्तमान मॉडलिंग प्रथाओं को अनुकूलित करना शुरू करने के लिए, इस सामान्य क्रम का पालन करें।
डेटा प्रवाह आरेख तकनीकी परिवर्तन के दशकों से बचा है क्योंकि इसका मूल उद्देश्य अभी भी वैध है: स्पष्टता। जब तक नोटेशन को माइक्रोसर्विसेज, क्लाउड इंफ्रास्ट्रक्चर और असिंक्रोनस घटनाओं को समायोजित करने के लिए फैलाया जाता है, डेटा गति को दृश्यीकृत करने का मूल लक्ष्य अपरिवर्तित रहता है। उनके पीछे के प्रतीकों और मानसिक मॉडल को अपडेट करके, टीमें DFD का उपयोग तकनीकी विश्लेषण के मुख्य उपकरण के रूप में जारी रख सकती हैं। विकास का उद्देश्य विधि को बदलना नहीं है, बल्कि आधुनिक डिजिटल लैंडस्केप की जटिलता के अनुरूप इसे बेहतर बनाना है। 🌐