 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











सॉफ्टवेयर प्रोजेक्ट अक्सर कोड की गुणवत्ता के कारण नहीं, बल्कि गलत समझे गए आवश्यकताओं के कारण फंस जाते हैं। जब टीमें डेटा के आवागमन के स्पष्ट नक्शे के बिना सीधे डिजाइन या विकास में कूद जाती हैं, तो परिणाम तकनीकी ऋण और स्कोप क्रीप होता है। यहीं डेटा फ्लो डायग्राम, या DFD, अपनी कार्यक्षमता साबित करता है। यह व्यावसायिक हितधारकों और तकनीकी वास्तुकारों के बीच के अंतर को पार करने वाली एक दृश्य भाषा के रूप में कार्य करता है।
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। फ्लोचार्ट्स के विपरीत, जो नियंत्रण तर्क और निर्णय बिंदुओं पर ध्यान केंद्रित करते हैं, DFDs सूचना प्रवाह पर ध्यान केंद्रित करते हैं। वे दिखाते हैं कि डेटा प्रणाली में कैसे प्रवेश करता है, इसे कैसे परिवर्तित किया जाता है, इसे कहाँ संग्रहीत किया जाता है, और यह कैसे बाहर निकलता है। आवश्यकताओं संग्रह के संदर्भ में, इस अंतर की महत्वपूर्ण भूमिका है। यह बातचीत को प्रणाली क्या करती है से प्रणाली कौन से डेटा को संभालती है.
यह मार्गदर्शिका DFDs के यांत्रिकी, लाभ और रणनीतिक अनुप्रयोग का अध्ययन करती है। हम देखेंगे कि वे अस्पष्टता को स्पष्ट कैसे करते हैं, मान्यता के समर्थन में कैसे काम करते हैं, और अंतिम उत्पाद को व्यावसायिक आवश्यकताओं के अनुरूप बनाने में कैसे सुनिश्चित करते हैं।
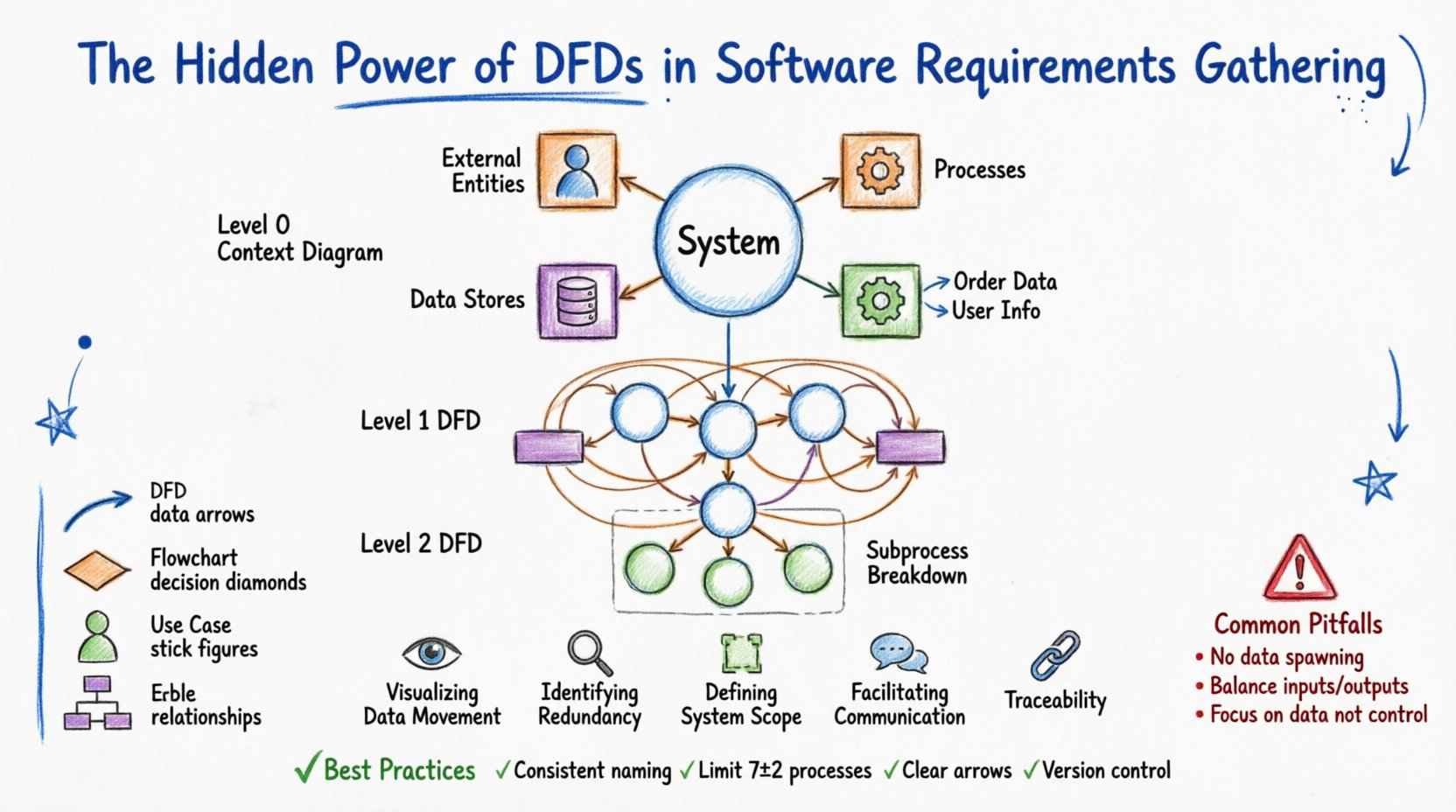
जटिल प्रोजेक्ट्स में DFDs के अनुप्रयोग से पहले, एक को निर्माण ब्लॉक्स को समझना आवश्यक है। एक DFD चार मूल तत्वों से मिलकर बनता है। प्रत्येक का एक विशिष्ट ज्यामितीय प्रतिनिधित्व होता है और इसके प्रणाली के भीतर के कार्य के संबंध में सख्त परिभाषा होती है।
इन घटकों को समझने से आवश्यकताओं के कार्यशाला के दौरान भ्रम को रोका जा सकता है। हितधारक अक्सर एक प्रक्रिया और डेटा स्टोर को गलती से बराबर कर देते हैं। एक स्पष्ट आरेख स्पष्ट करता है कि एक “ग्राहक” एक एकाधिकार है, लेकिन “ग्राहक रिकॉर्ड” एक स्टोर है। यह अंतर सटीक प्रणाली मॉडलिंग की नींव है।
आवश्यकताओं के दस्तावेज अक्सर विवादास्पद व्याख्या के लिए खुले टेक्स्ट-भारी वर्णनों के कारण पीड़ित होते हैं। एक DFD एकमात्र सच्चाई का स्रोत प्रदान करता है जो दृश्य और अंतरिक्षगत है। यहां विश्लेषण चरण के दौरान उनकी अनिवार्यता के कारण हैं।
DFD को एक ही दृश्य में नहीं बनाया जाता है। जटिलता को प्रबंधित करने के लिए उन्हें पदानुक्रमिक रूप से विभाजित किया जाता है। इस दृष्टिकोण से विश्लेषकों को उच्च स्तर के अवलोकन से शुरुआत करने और पाठक को अधिक जानकारी से भारी नहीं किए बिना विशिष्ट विवरणों में गहराई से जाने की अनुमति मिलती है।
यह सबसे ऊंचा स्तर है। इसमें पूरी प्रणाली को एकल प्रक्रिया के रूप में दर्शाया जाता है। यह प्रणाली के बाहरी दुनिया के साथ संबंध को दर्शाता है। आपको केंद्र में एकल प्रक्रिया दिखाई देगी, जो सभी बाहरी एकाधिकारों द्वारा डेटा प्रवाह से घिरी होगी। इस आरेख का उत्तर है: “प्रणाली क्या है, और यह किससे बातचीत करती है?”
यहाँ, संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विस्तारित किया जाता है। इस स्तर में आमतौर पर 5 से 9 प्रक्रियाएँ होती हैं। यह प्रणाली के मुख्य कार्यात्मक क्षेत्रों को दर्शाता है। इसमें डेटा भंडार और बाहरी एकाधिकार शामिल होते हैं, लेकिन फोकस मुख्य रूपांतरणों पर होता है।
स्तर 1 से प्रत्येक प्रक्रिया को एक स्तर 2 आरेख में और विभाजित किया जा सकता है। यह जटिल तर्क के लिए उपयोगी है। उदाहरण के लिए, “भुगतान प्रक्रिया” प्रक्रिया को “कार्ड की पुष्टि करना”, “खाते को लेना”, और “लेजर को अद्यतन करना” में विभाजित किया जा सकता है। विभाजन तब रुक जाता है जब प्रक्रियाएँ इतनी सरल हो जाती हैं कि एकल मॉड्यूल या फ़ंक्शन के रूप में कार्यान्वित किया जा सके।
एक प्रभावी DFD बनाने के लिए अनुशासन की आवश्यकता होती है। यह केवल रेखाएँ खींचने के बारे में नहीं है; यह तर्क को सही तरीके से दर्शाने के बारे में है। गुणवत्ता सुनिश्चित करने के लिए इस संरचित दृष्टिकोण का पालन करें।
यहाँ तक कि अनुभवी विश्लेषक भी गलतियाँ करते हैं। इन त्रुटियों को जल्दी पहचानने से विकास चरण में महत्वपूर्ण समय बचता है। नीचे आवश्यकताओं के मॉडलिंग के दौरान सबसे अधिक आम समस्याएँ दी गई हैं।
| गलती | विवरण | सुधार |
|---|---|---|
| डेटा का अनावश्यक उत्पादन | डेटा बिना किसी इनपुट स्रोत के अचानक दिखाई देता है। | प्रत्येक त стрी एक एंटिटी, प्रक्रिया या स्टोर से उत्पन्न होनी चाहिए। |
| डेटा विनाश | डेटा एक प्रक्रिया में प्रवेश करता है लेकिन आउटपुट या स्टोरेज के बिना गायब हो जाता है। | सुनिश्चित करें कि प्रत्येक इनपुट का एक मायने रखने वाला आउटपुट हो या सहेजा जाए। |
| नियंत्रण तर्क | डेटा प्रवाह के बजाय निर्णय तर्क (यदि/विकल्प) दिखाने के लिए DFD का उपयोग करना। | तर्क नियंत्रण के लिए फ्लोचार्ट का उपयोग करें; डेटा गतिशीलता के लिए DFD का उपयोग करें। |
| असंतुलित आरेख | चाइल्ड आरेख में मूल आरेख के बजाय अलग इनपुट/आउटपुट होते हैं। | सुनिश्चित करने के लिए विभाजन की समीक्षा करें कि सभी डेटा प्रवाहों को ध्यान में रखा गया है। |
| भूत प्रक्रियाएँ | वे प्रक्रियाएँ जो डेटा को बदलती नहीं हैं या उसे स्टोर नहीं करती हैं। | प्रतिस्थापन न करने वाली प्रक्रियाओं को हटाएं। |
| सीधा एंटिटी-टू-एंटिटी प्रवाह | डेटा दो बाहरी एंटिटी के बीच प्रणाली से गुजरे बिना प्रवाहित होता है। | यह प्रणाली के दायरे से बाहर है। प्रणाली को इंटरैक्शन को प्रक्रिया करना चाहिए। |
DFD को अन्य डायग्रामिंग विधियों के साथ भ्रमित करना आम बात है। प्रत्येक उपकरण सॉफ्टवेयर इंजीनियरिंग चक्र में एक विशिष्ट उद्देश्य के लिए होता है। यह जानना कि किस समय किस डायग्राम का उपयोग करना है, भ्रम को रोकता है।
प्रोजेक्ट जीवनचक्र के दौरान आपके आरेख उपयोगी संसाधन बने रहें, इसके लिए इन मानकों का पालन करें। स्थिरता आवश्यकता मॉडल की अखंडता बनाए रखने के लिए महत्वपूर्ण है।
अच्छी तरह से निर्मित DFD के सबसे शक्तिशाली पहलुओं में से एक ट्रेसेबिलिटी मैट्रिक्स के समर्थन करने की क्षमता है। ट्रेसेबिलिटी सुनिश्चित करती है कि प्रत्येक आवश्यकता पूरी की जाती है और कोई भी बिना उद्देश्य के नहीं बनाया जाता है।
जब आप एक DFD बनाते हैं, तो आप प्रत्येक प्रक्रिया और डेटा स्टोर के लिए एक अद्वितीय ID निर्धारित कर सकते हैं। उदाहरण के लिए, प्रक्रिया P1.0 को आवश्यकता REQ-001 के साथ मिलाया जा सकता है। यदि कोई स्टेकहोल्डर एक नई सुविधा के लिए अनुरोध करता है, तो आप उसे एक विशिष्ट प्रक्रिया ID से मैप कर सकते हैं। यदि आप आरेख में प्रक्रिया को ढूंढ सकते हैं, तो आपको बिल्कुल पता चल जाता है कि डेटा तर्क में कहां पर बदलाव की आवश्यकता है।
यह पुनरावृत्ति परीक्षण के दौरान विशेष रूप से महत्वपूर्ण है। यदि “ब्याज की गणना” प्रक्रिया को बदला जाता है, तो DFD QA टीम को बिल्कुल पता चलता है कि कौन से डेटा प्रवाह प्रभावित होते हैं। उन्हें पता चलता है कि इनपुट (मूलधन राशि) और आउटपुट (ब्याज भुगतान) को विशेष रूप से परीक्षण करना चाहिए। DFD के बिना, परीक्षक डेटा रूपांतरण से संबंधित एज केसेज को छोड़ सकते हैं।
कुछ टीमें कहती हैं कि DFDs एजाइल पद्धतियों के लिए बहुत भारी हैं। वे उपयोगकर्ता कहानियों और स्वीकृति मानदंडों को प्राथमिकता देते हैं। जबकि उपयोगकर्ता कहानियां कार्यक्षमता के लिए उत्तम हैं, वे अक्सर डेटा प्रवाह के प्रणालीगत दृष्टिकोण के अभाव में होती हैं। DFDs एजाइल में अच्छी तरह से फिट होती हैं यदि इन्हें एक जीवंत सामग्री के रूप में उपयोग किया जाए।
एक DFD को अक्सर डेटा शब्दकोश के साथ जोड़ा जाता है। डेटा शब्दकोश आरेख में दिखाए गए प्रत्येक डेटा तत्व की तकनीकी परिभाषा प्रदान करता है। इसमें डेटा प्रकार, लंबाई और प्रारूप निर्दिष्ट किए जाते हैं।
उदाहरण के लिए, आरेख पर “जन्म तिथि” लेबल वाले डेटा प्रवाह को शब्दकोश में “YYYY-MM-DD, ISO 8601, Nullable” के रूप में परिभाषित किया जा सकता है। इस सटीकता से विकासकर्ताओं को डेटा को कैसे स्टोर करना है, इसके बारे में अनुमान लगाने से बचाया जाता है। जब आवश्यकता एकत्र करने में DFDs और डेटा शब्दकोश दोनों शामिल होते हैं, तो डेटा प्रकार के असंगत होने का जोखिम महत्वपूर्ण रूप से कम हो जाता है।
अपने डेटा शब्दकोश के लिए निम्नलिखित घटकों पर विचार करें:
अवधारणा से कोड तक का सफर गलत व्याख्या से भरा है। डेटा प्रवाह आरेख इस यात्रा में एक स्थिर बल के रूप में कार्य करते हैं। वे टीम को डेटा गतिशीलता के वास्तविकता का सामना करने के लिए मजबूर करते हैं। वे एक भी कोड लाइन लिखे जाने से पहले तर्क की कमियों को उजागर करते हैं।
उच्च गुणवत्ता वाले DFDs बनाने में समय निवेश करने से पुनर्कार्य कम होता है। जब हितधारक आरेख की पुष्टि करते हैं, तो वे प्रणाली के तर्क की पुष्टि कर रहे होते हैं। इस साझा समझ से व्यवसाय और प्रौद्योगिकी टीमों के बीच तनाव कम होता है। यह चर्चा को राय से तथ्य पर ले जाता है।
याद रखें कि DFD एक स्थिर डिलीवरेबल नहीं है। आवश्यकताओं के विकास के साथ यह विकसित होता है। इसे कोडबेस के समान गंभीरता से लें। इसे अपडेट रखें, इसे उपलब्ध रखें, और इसका उपयोग अपने विकास प्रयासों को मार्गदर्शन के लिए करें। डेटा मॉडलिंग के कला को समझने से आप सुनिश्चित कर सकते हैं कि आप जो सॉफ्टवेयर बना रहे हैं, वह केवल कार्यात्मक नहीं है, बल्कि तार्किक रूप से स्थिर और व्यवसाय की आवश्यकताओं के अनुरूप है।
DFD की छिपी हुई शक्ति उनकी सरलता में है। वे कार्यान्वयन विवरणों की आवाज़ को हटा देते हैं और मूल सत्य पर ध्यान केंद्रित करते हैं: डेटा को सही तरीके से प्रवाहित होना चाहिए। जब डेटा सही तरीके से प्रवाहित होता है, तो प्रणाली काम करती है। जब डेटा गायब होता है या गलत दिशा में जाता है, तो प्रणाली विफल हो जाती है। इस उपकरण का उपयोग आपके आवश्यकता संग्रह को आत्मविश्वास और सटीकता के साथ मार्गदर्शन के लिए करें।