 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











डेटा फ्लो डायग्राम (DFD) सूचना प्रणालियों के दृश्य नक्शे के रूप में कार्य करते हैं। कोड के विपरीत, जो वाक्य रचना के माध्यम से तर्क का वर्णन करता है, एक DFD गति के माध्यम से तर्क का वर्णन करता है। यह डेटा किस प्रकार प्रणाली में प्रवेश करता है, विभिन्न प्रक्रियाओं के माध्यम से परिवर्तित होता है और आउटपुट या भंडारण के रूप में बाहर निकलता है, इसका नक्शा बनाता है। यह मार्गदर्शिका निजी उपकरणों पर निर्भर न करते हुए इन डायग्रामों के निर्माण के बारे में व्यापक जानकारी प्रदान करती है, जिसमें प्रणाली विश्लेषण के मूल सिद्धांतों पर ध्यान केंद्रित किया गया है।
चाहे आप एक नए एप्लिकेशन के लिए आवश्यकताओं को परिभाषित कर रहे हों या मौजूदा पुरानी प्रणाली की जांच कर रहे हों, डेटा फ्लो को समझना आवश्यक है। एक अच्छी तरह से संरचित DFD अस्पष्टता को दूर करता है। यह स्टेकहोल्डर्स को जानकारी के उत्पत्ति स्थल और समाप्ति स्थल के बारे में सहमत होने के लिए मजबूर करता है। यह दस्तावेज DFD की रचना, उनके निर्माण के नियमों और जटिल प्रणालियों को प्रबंधन योग्य दृश्यों में विभाजित करने की विधियों के बारे में अन्वेषण करता है।
एक डेटा फ्लो डायग्राम नियंत्रण प्रवाह डायग्राम नहीं है। यह घटनाओं के समय या क्रम को नहीं दिखाता है। इसके बजाय, यह डेटा के स्वयं पर ध्यान केंद्रित करता है। इसे एक नदी प्रणाली के नक्शे के रूप में सोचें। आपको पानी की गति या मौसम के बारे में चिंता नहीं है, आपको नदी की सहायक नदियों, जलाशयों और नदियों के मुख के बारे में चिंता है।
जब किसी व्यवसाय प्रणाली का मॉडलिंग किया जाता है, तो DFD तीन प्रमुख प्रश्नों के उत्तर देता है:
इन प्रश्नों के उत्तर देकर आप व्यवसाय का तार्किक प्रतिनिधित्व बनाते हैं। यह प्रतिनिधित्व बनाने के लिए उपयोग किए जाने वाले तकनीकी स्टैक के बावजूद वैध रहता है। यह एक अमूर्तता की भाषा है जो व्यवसाय की आवश्यकताओं और तकनीकी कार्यान्वयन के बीच के अंतर को पार करती है।
प्रत्येक डेटा फ्लो डायग्राम चार विशिष्ट प्रतीकों के उपयोग से बनाया जाता है। विधियों के बीच नोटेशन में थोड़ा अंतर हो सकता है, लेकिन मूल अवधारणाएँ स्थिर रहती हैं। इन तत्वों को समझना सटीक मॉडलिंग की नींव है।
बाहरी एकाइयाँ उन स्रोतों या गंतव्यों का प्रतिनिधित्व करती हैं जो मॉडल की जा रही प्रणाली की सीमा के बाहर स्थित हैं। वे अक्सर लोग, विभाग या अन्य प्रणालियाँ होती हैं जो मुख्य प्रणाली के साथ बातचीत करती हैं।
आरेखों में, इन्हें आमतौर पर वर्ग या आयत के रूप में दर्शाया जाता है। इन्हें हमेशा किसी प्रक्रिया से जोड़ा जाना चाहिए; डेटा बिना कारण या अदृश्य होकर गायब नहीं हो सकता।
एक प्रक्रिया इनपुट डेटा को आउटपुट डेटा में बदलती है। यह प्रणाली का इंजन है। DFD में, प्रक्रियाओं को आमतौर पर वृत्त या गोल आयत के रूप में दर्शाया जाता है। प्रक्रिया के नाम को हमेशा क्रिया को दर्शाने वाले क्रिया-संज्ञा वाक्यांश के रूप में होना चाहिए।
प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होने चाहिए। यदि कोई प्रक्रिया इनपुट है लेकिन आउटपुट नहीं है, तो यह एक “काला छेद” है। यदि इसके आउटपुट हैं लेकिन इनपुट नहीं हैं, तो यह एक “चमत्कार” है। दोनों मॉडलिंग त्रुटियों का प्रतिनिधित्व करते हैं।
डेटा भंडार उन स्थानों का प्रतिनिधित्व करते हैं जहाँ जानकारी बाद में प्राप्त करने के लिए संग्रहीत की जाती है। यह एक डेटाबेस, फाइल प्रणाली, भौतिक फाइल बॉक्स या अस्थायी बफर हो सकता है। प्रक्रियाओं के विपरीत, डेटा भंडार डेटा को नहीं बदलते हैं; वे इसे रखते हैं।
इन्हें आमतौर पर खुले अंत वाले आयत या दो समानांतर रेखाओं के रूप में बनाया जाता है। ये डेटा प्रवाह के माध्यम से प्रक्रियाओं से जुड़ते हैं, जो पढ़ने या लिखने के संचालन को इंगित करते हैं।
डेटा प्रवाह वे तीर हैं जो घटकों को जोड़ते हैं। ये एकताओं, प्रक्रियाओं और भंडारों के बीच डेटा के गति का प्रतिनिधित्व करते हैं। तीर के सिरे गति की दिशा को इंगित करते हैं।
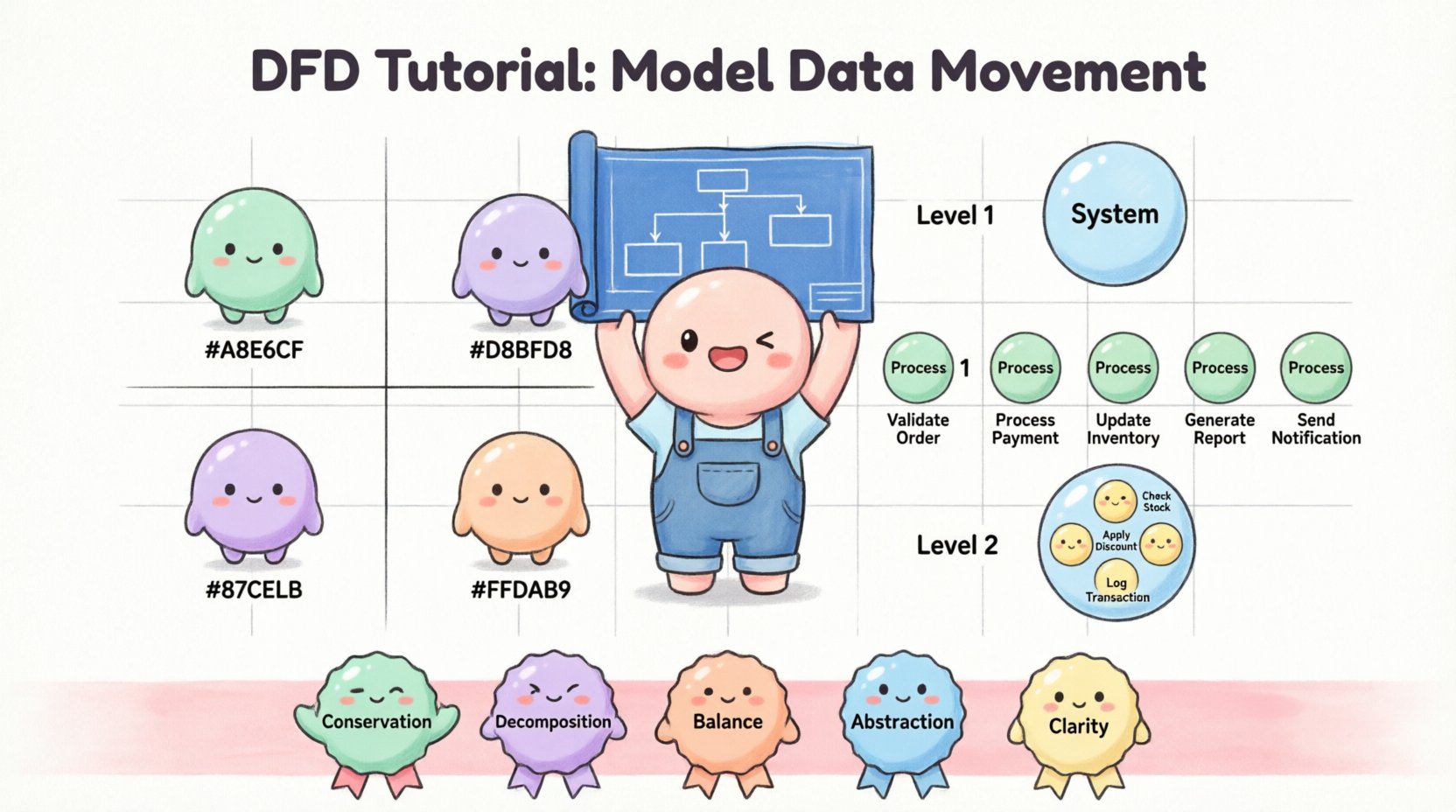
जटिल प्रणालियों को एक ही पृष्ठ पर नहीं बनाया जा सकता है। जटिलता को प्रबंधित करने के लिए, डेटा प्रवाह आरेख (DFD) विभिन्न विवरण स्तरों में विभाजित किए जाते हैं। इस पदानुक्रमिक दृष्टिकोण के कारण विश्लेषक प्रणाली संरचना में जूम इन और जूम आउट कर सकते हैं।
संदर्भ आरेख सर्वोच्च स्तर का दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया बबल के रूप में दिखाता है। यह दिखाता है कि प्रणाली बाहरी एकताओं के साथ कैसे बातचीत करती है।
स्तर 1 संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विस्तारित करता है। इस स्तर पर प्रणाली के प्राथमिक कार्यात्मक क्षेत्रों की पहचान की जाती है।
लेवल 2 लेवल 1 से विशिष्ट प्रक्रियाओं पर ध्यान केंद्रित करता है। यह जटिल कार्यों को छोटे, कार्यान्वित करने योग्य चरणों में बांटता है। इस स्तर पर विकासकर्ता अक्सर विशिष्ट तार्किक आवश्यकताओं की तलाश करते हैं।
प्रणाली विश्लेषण में दो प्रमुख नोटेशन का उपयोग किया जाता है। जब तक तर्क समान रहता है, दृश्य प्रस्तुतीकरण भिन्न होता है। सही एक का चयन टीम की परिचितता और संगठन के मानकों पर निर्भर करता है।
| विशेषता | यौरडॉन और डीमार्को | गेन और सर्सन |
|---|---|---|
| प्रक्रिया आकृति | गोल आयत | गोल आयत |
| एंटिटी आकृति | वर्ग | वर्ग |
| डेटा स्टोर आकृति | खुला आयत | मोटे ऊपरी/निचले हिस्से वाला खुला आयत |
| डेटा प्रवाह आकृति | वक्र तीर | सीधा तीर |
| प्रवाह लेबल स्थिति | रेखा के नीचे | ऊपर या नीचे |
गेन और सर्सन तथा यौरडॉन और डीमार्को के बीच चयन अधिकांश रूप से सौंदर्यात्मक है। हालांकि, सुसंगतता बहुत महत्वपूर्ण है। एक ही दस्तावेज में नोटेशन का मिश्रण भ्रम पैदा करता है और दस्तावेज की स्पष्टता को कम करता है।
DFD बनाना एक व्यवस्थित प्रक्रिया है। इसमें पुनरावृत्ति और प्रमाणीकरण की आवश्यकता होती है। सटीकता और पूर्णता सुनिश्चित करने के लिए इन चरणों का पालन करें।
किसी भी रेखा को खींचने से पहले, यह पहचानें कि सिस्टम के अंदर क्या है और बाहर क्या है। इसका निर्धारण अक्सर परियोजना के दायरे द्वारा किया जाता है। कोई भी चीज जो इनपुट प्रदान करती है या आउटपुट प्राप्त करती है, एक सीमा की स्थिति है।
सभी स्रोतों और गंतव्यों की सूची बनाएं। यह तय करने के लिए स्टेकहोल्डर्स से साक्षात्कार करें कि सिस्टम के साथ कौन बातचीत करता है। स्वचालित प्रणालियों को न भूलें; वे मनुष्यों की तरह ही एक एंटिटी हैं।
बड़ी तस्वीर से शुरू करें। सिस्टम को एक बबल के रूप में बनाएं। बाहरी एंटिटीज को तीरों से जोड़ें। तीरों को आदान-प्रदान किए जा रहे डेटा के साथ लेबल करें। यह सभी बाद के आरेखों के लिए आधार बनता है।
एकल बबल को लेवल 1 में विस्तारित करें। प्रमुख कार्यों की पहचान करें। सिस्टम को तार्किक खंडों में बांटें। यह सुनिश्चित करें कि लेवल 0 आरेख के इनपुट और आउटपुट लेवल 1 प्रक्रियाओं के संग्रहित इनपुट और आउटपुट के बराबर हों।
यह पहचानें कि डेटा कहाँ स्थायी रूप से रखा जाना चाहिए। यदि किसी प्रक्रिया को पिछले लेन-देन से जानकारी याद रखने की आवश्यकता है, तो एक डेटा स्टोर की आवश्यकता होती है। इन स्टोर्स को संबंधित प्रक्रियाओं से जोड़ें।
यह एक महत्वपूर्ण नियम है। एक मातृ प्रक्रिया के इनपुट और आउटपुट को उसके बच्चों के इनपुट और आउटपुट के योग के बराबर होना चाहिए। यदि संदर्भ आरेख में “ऑर्डर प्राप्त” दिखाया गया है, तो लेवल 1 आरेख में भी “ऑर्डर प्राप्त” को सिस्टम में कहीं प्रवेश करते हुए दिखाना चाहिए।
आरेख के माध्यम से चलें। डेटा के एक टुकड़े का आरंभ से अंत तक अनुसरण करें। क्या यह तार्किक रूप से प्रवाहित होता है? क्या कोई अनाथ प्रक्रिया है? क्या सभी डेटा प्रवाह लेबल किए गए हैं?
यहां तक कि अनुभवी विश्लेषक भी इन मॉडलों के निर्माण के दौरान गलतियां करते हैं। सामान्य त्रुटियों के बारे में जागरूक रहने से समीक्षा चरण में महत्वपूर्ण समय बच सकता है।
यह महत्वपूर्ण है कि सिस्टम के तार्किक दृष्टिकोण और भौतिक दृष्टिकोण के बीच अंतर करना। तार्किक DFD वर्णन करता हैक्यावह क्या करता है। भौतिक DFD वर्णन करता हैकैसे प्रणाली इसे कैसे करती है।
तार्किक मॉडल से शुरुआत करें। तकनीकी सीमाओं को बहुत जल्दी न लाएं। तकनीक को बहुत जल्दी लाने से डिज़ाइन विकल्पों को सीमित किया जा सकता है और विश्लेषण में आंशिकता उत्पन्न हो सकती है। जब तार्किक मॉडल को मंजूरी मिल जाती है, तो विकास को मार्गदर्शन करने के लिए भौतिक मॉडल विकसित किया जा सकता है।
यह सुनिश्चित करने के लिए कि DFDs प्रोजेक्ट जीवनचक्र के दौरान उपयोगी रहें, इन मानकों का पालन करें।
इन आरेखों को बनाने में समय निवेश क्यों करें? लिखित आवश्यकताएं गलत व्याख्या के लिए झुकी होती हैं। किसी प्रक्रिया का वर्णन करने वाला वाक्य कई तरीकों से पढ़ा जा सकता है। एक आरेख दृश्य और अंतरिक्षीय होता है।
जब कोई हितधारक एक आरेख देखता है, तो वह तुरंत अनुपस्थित प्रवाहों को पहचान सकता है। वह यह देख सकता है कि डेटा कहाँ दोहराया गया है। वह तुरंत प्रणाली की जटिलता को समझ सकता है। इस दृश्य पुष्टि से गलत प्रणाली बनाने के जोखिम को कम किया जा सकता है।
इसके अलावा, DFDs व्यापार और तकनीकी टीमों के बीच संचार उपकरण के रूप में कार्य करते हैं। व्यापार विश्लेषक इन्हें आवश्यकताओं को समझने के लिए उपयोग करते हैं। विकासकर्ता इन्हें आर्किटेक्चर को समझने के लिए उपयोग करते हैं। एक साझा कलाकृति को बनाए रखकर संगठन सिलों को कम करता है और समन्वय में सुधार करता है।
डेटा प्रवाह आरेख विधि को लागू करने के लिए अनुशासन की आवश्यकता होती है। रेखाएं खींचना पर्याप्त नहीं है; आपको डेटा संरक्षण और विघटन के नियमों को समझना होगा। जैसे-जैसे आप अभ्यास करेंगे, आप पाएंगे कि आरेख आपकी सोच की प्रक्रिया का एक प्राकृतिक विस्तार बन जाते हैं।
छोटे से शुरू करें। एक सरल लेन-देन का मॉडल बनाएं। फिर विभाग तक विस्तार करें। अंत में, पूरी संगठन का मॉडल बनाएं। प्रत्येक स्तर पर, आपकी प्रणाली के बारे में समझ गहरी होती है। लक्ष्य एक सही आरेख बनाना नहीं है, बल्कि सूचना के आवागमन का स्पष्ट मानचित्र बनाना है जो लचीले सॉफ्टवेयर समाधानों के निर्माण को मार्गदर्शन करे।
याद रखें, आरेख सोचने का एक उपकरण है, केवल फाइल करने के लिए दस्तावेज़ नहीं है। इसका उपयोग धारणाओं को चुनौती देने, अंतराल को पहचानने और तर्क की पुष्टि करने के लिए करें। सिस्टम डिज़ाइन के क्षेत्र में, स्पष्टता ही सबसे ऊंचा रूप है।
इन सिद्धांतों का पालन करके, आप सुनिश्चित करते हैं कि किसी भी व्यापार प्रणाली के भीतर डेटा गतिशीलता का सटीक रूप से दस्तावेजीकरण किया जाता है और प्रोजेक्ट चक्र में शामिल सभी हितधारकों द्वारा समझा जाता है।