डेटा फ्लो डायग्राम (DFD) सिस्टम डिज़ाइन और विश्लेषण की आधारशिला के रूप में कार्य करते हैं। वे जानकारी के एक सिस्टम में गति के तरीके का दृश्य प्रतिनिधित्व प्रदान करते हैं, जिसमें प्रक्रियाओं, डेटा स्टोर्स और बाहरी अंतरक्रियाओं को उजागर किया जाता है। हालांकि, एक डायग्राम केवल उसकी सटीकता और स्पष्टता के बराबर ही अच्छा होता है। कठोर जांच के बिना, एक DFD गलत अपेक्षाओं, विकास त्रुटियों और सुरक्षा की कमी की ओर ले जा सकता है।
यह मार्गदर्शिका आपके डेटा फ्लो डायग्राम की पुष्टि करने के लिए एक व्यापक चेकलिस्ट प्रदान करती है। हम डायग्राम के हर पहलू का अध्ययन करेंगे, संरचनात्मक अखंडता से लेकर तार्किक संगतता तक, ताकि आपका दस्तावेज़ केवल एक ड्राइंग न हो, बल्कि इंजीनियरिंग और संचार के लिए एक कार्यात्मक उपकरण हो। 🛠️
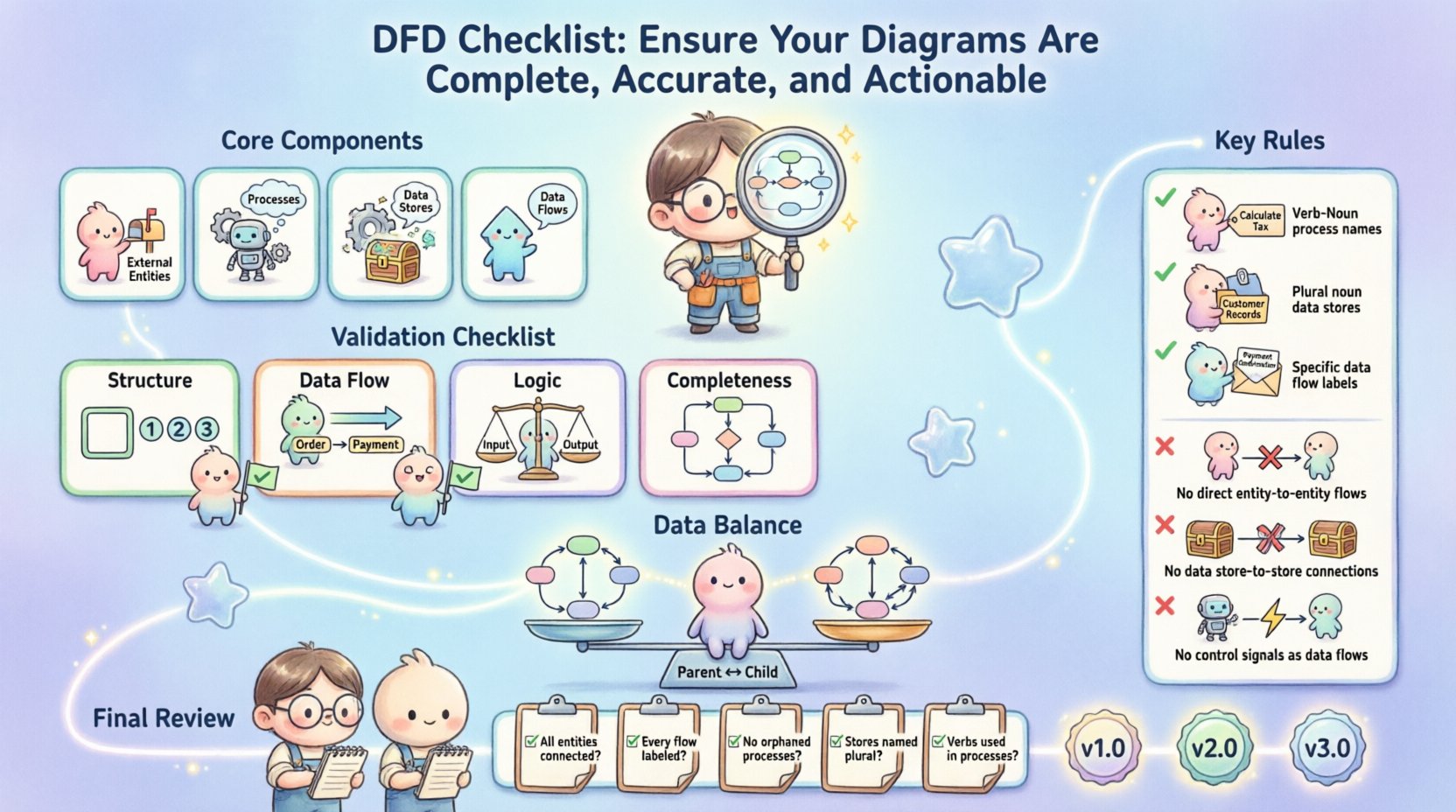
मूल घटकों को समझना 🧩
चेकलिस्ट के लागू करने से पहले, यह आवश्यक है कि आप सुनिश्चित करें कि मूल तत्व मौजूद हैं और सही तरीके से परिभाषित हैं। एक वैध DFD चार विशिष्ट घटकों पर निर्भर करता है। यदि कोई भी घटक गायब है या गलत तरीके से उपयोग किया गया है, तो डायग्राम की अखंडता प्रभावित हो जाती है।
- बाहरी एजेंसियाँ: ये सिस्टम सीमा के बाहर डेटा के स्रोत या गंतव्य हैं। वे उपयोगकर्ताओं, अन्य सिस्टम या हार्डवेयर उपकरणों का प्रतिनिधित्व करते हैं जो सिस्टम के साथ अंतरक्रिया करते हैं।
- प्रक्रियाएँ: ये डेटा पर लागू की जाने वाली क्रियाओं या परिवर्तनों का प्रतिनिधित्व करते हैं। वे इनपुट डेटा लेते हैं, उसे संशोधित करते हैं और आउटपुट डेटा उत्पन्न करते हैं।
- डेटा स्टोर्स: ये डेटा के विश्राम के स्थान का प्रतिनिधित्व करते हैं। इनमें डेटाबेस, फाइलें या भौतिक आर्काइव्स शामिल हैं।
- डेटा प्रवाह: ये घटकों को जोड़ने वाली तीर हैं, जो सूचना के गति की दिशा को इंगित करती हैं।
प्रत्येक घटक को विशिष्ट नोटेशन नियमों का पालन करना चाहिए। हालांकि नोटेशन शैलियाँ भिन्न होती हैं, लेकिन मूल तर्क समान रहता है। सुनिश्चित करें कि आप अपने संगठन में उपयोग की जा रही विशिष्ट मानक के बारे में परिचित हैं, चाहे वह गेन और सर्सन हो या यौरडॉन और डेमार्को।
डायग्राम से पहले तैयारी 📝
जांच तब शुरू होती है जब पहला तीर खींचा जाता है। अच्छी तरह से तैयार परिवेश डायग्रामिंग चरण के दौरान त्रुटियों को कम करता है। एक मजबूत आधार बनाने के लिए निम्नलिखित तैयारी चरणों का उपयोग करें।
- सिस्टम सीमा को परिभाषित करें: स्पष्ट रूप से पहचानें कि सिस्टम के अंदर क्या है और बाहर क्या है। इससे यह निर्धारित होता है कि कौन सी प्रक्रियाएँ शामिल हैं और कौन सी एजेंसियाँ बाहरी हैं।
- हितधारकों को पहचानें: जानें कि डायग्राम की समीक्षा कौन करेगा। डेवलपर्स को बिजनेस एनालिस्ट्स की तुलना में अलग विवरण की आवश्यकता होती है।
- नामकरण प्रणाली स्थापित करें: शुरुआत से पहले प्रक्रियाओं, डेटा प्रवाहों और स्टोर्स के लिए नामकरण मानकों पर सहमति बनाएं। संगतता बाद में भ्रम से बचाती है।
- विभाजन की सीमा निर्धारित करें: यह तय करें कि कितने स्तरों की विस्तार से आवश्यकता है। एक ही डायग्राम सब कुछ नहीं दिखा सकता; विभाजन की व्यवस्था बनाएं।
व्यापक जांच चेकलिस्ट ✅
अपनी समीक्षा प्रक्रिया के दौरान इस तालिका का संदर्भ के रूप में उपयोग करें। यह महत्वपूर्ण क्षेत्रों को कवर करता है जिन पर ध्यान देने की आवश्यकता है ताकि डायग्राम कार्यात्मक और सटीक हो।
| श्रेणी |
जांच आइटम |
जांच मानदंड |
| संरचना |
सीमा परिभाषा |
प्रणाली की सीमाओं को स्पष्ट रूप से एक अलग रेखा या बॉक्स के साथ चिह्नित किया गया है। |
| रचना |
प्रक्रिया संख्या |
प्रक्रियाओं की क्रमिक संख्या दी गई है (उदाहरण के लिए, 1.0, 2.0, 3.0)। |
| डेटा प्रवाह |
तीर की दिशा |
सभी प्रवाहों का स्पष्ट शुरुआत और अंत बिंदु है; कोई तैरता हुआ तीर नहीं है। |
| डेटा प्रवाह |
डेटा लेबलिंग |
प्रत्येक तीर के लिए एक वर्णनात्मक संज्ञा वाक्यांश होता है, कोई क्रिया नहीं। |
| तर्क |
प्रक्रिया इनपुट/आउटपुट |
प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होना चाहिए। |
| तर्क |
डेटा स्टोर पहुंच |
डेटा स्टोर को पढ़ने (इनपुट) और लिखने (आउटपुट) दोनों प्रवाह की आवश्यकता होती है। |
| पूर्णता |
बाहरी एकाधिकार पहुंच |
प्रत्येक बाहरी एकाधिकार कम से कम एक प्रक्रिया से जुड़ा हुआ है। |
| पूर्णता |
डेटा स्टोर अलगाव |
डेटा प्रवाह सीधे दूसरे डेटा स्टोर से नहीं जुड़ते हैं। |
1. संरचनात्मक अखंडता 🔨
आरेख की भौतिक व्यवस्था को तार्किक प्रवाह का समर्थन करना चाहिए। एक अव्यवस्थित आरेख अक्सर प्रणाली की अव्यवस्थित समझ की ओर जाता है।
- क्रमिक संख्यांकन: सुनिश्चित करें कि सभी प्रक्रियाओं को तार्किक रूप से संख्या दी गई हो। स्तर 0 को 0.0 या 1.0 से शुरू करना चाहिए। विभाजित प्रक्रियाओं को माता-पिता-बच्चा पदानुक्रम का पालन करना चाहिए (उदाहरण के लिए, 1.1, 1.2)।
- संगत आकृतियाँ: यदि प्रक्रियाओं के लिए आयताकार आकृतियों का उपयोग कर रहे हैं, तो सुनिश्चित करें कि उन्हें डेटा स्टोर से गलती से न माना जाए। यदि गोल या गोलाकार आयताकार आकृतियों का उपयोग कर रहे हैं, तो दस्तावेज में संगतता बनाए रखें।
- कोई असंगत घटक नहीं: सुनिश्चित करें कि प्रत्येक आकृति कम से कम एक अन्य तत्व से जुड़ी हो। अलग-थलग प्रक्रियाएँ या एकांत तत्व एक टूटे हुए कार्यप्रवाह का संकेत करते हैं।
2. डेटा प्रवाह की सटीकता 🔄
डेटा प्रवाह आरेख की धमनियाँ हैं। यदि वे गलत हैं, तो पूरी प्रणाली की तर्कशास्त्र गलत है।
- केवल संज्ञा वाक्यांशों का उपयोग करें:डेटा प्रवाह पर लेबल संज्ञा (उदाहरण के लिए, “आदेश विवरण”) होने चाहिए, क्रिया (उदाहरण के लिए, “आदेश प्रक्रिया”) नहीं। क्रियाएँ प्रक्रियाओं पर ही होनी चाहिए।
- द्विदिशात्मक प्रवाह: यदि एक ही तीर दो घटकों को जोड़ता है, तो सुनिश्चित करें कि डेटा वास्तव में दोनों दिशाओं में प्रवाहित हो रहा है। यदि डेटा प्रत्येक दिशा में अलग-अलग गति से चलता है, तो उन्हें दो अलग-अलग तीरों में विभाजित करें और उन्हें अलग-अलग लेबल दें।
- भूत प्रवाह: किसी भी डेटा प्रवाह को हटाएं जो वास्तविक जानकारी नहीं ले जा रहा हो। दो प्रक्रियाओं को जोड़ने वाली रेखा जो कोई डेटा नहीं ले जा रही हो, शोर है।
- नियंत्रण बनाम डेटा: नियंत्रण संकेतों और डेटा के बीच अंतर स्पष्ट करें। नियंत्रण संकेत (जैसे “शुरू” या “रुक”) डेटा नहीं हैं। यदि वे अवस्था परिवर्तन का प्रतिनिधित्व करते हैं, तो उन्हें अलग तरीके से मॉडल किया जाना चाहिए या अलग से दस्तावेज़ीकृत किया जाना चाहिए।
3. प्रक्रिया तर्क की पुष्टि ⚙️
प्रक्रियाएँ डेटा को बदलती हैं। यदि रूपांतरण तर्क गलत है, तो आउटपुट बेकार हो जाएगा।
- काला छेद जाँच: सुनिश्चित करें कि कोई प्रक्रिया बिना किसी उत्पादन के डेटा का उपभोग न करे। एक प्रक्रिया जो डेटा लेती है लेकिन उसके साथ कुछ नहीं करती है, एक काला छेद है और ऐसा नहीं होना चाहिए।
- ग्रे होल जाँच: सुनिश्चित करें कि कोई प्रक्रिया बिना किसी उपभोग के डेटा उत्पन्न न करे। एक प्रक्रिया जो किसी भी चीज़ के बिना आउटपुट उत्पन्न करती है, एक ग्रे होल (जादू) है।
- रूपांतरण स्पष्टता: इनपुट डेटा और आउटपुट डेटा अलग-अलग होने चाहिए। यदि आउटपुट इनपुट के समान है, तो प्रक्रिया अतिरिक्त हो सकती है, बशर्ते कि वह मेटाडेटा या समयचिह्न जोड़े।
- निर्णय बिंदु: डीएफडी आमतौर पर “यदि/नहीं” जैसे आंतरिक तर्क को नहीं दिखाते हैं। यदि किसी प्रक्रिया में शाखा तर्क शामिल है, तो उसे अलग विवरण प्रलेख में वर्णित किया जाना चाहिए, न कि एक ही आकृति के रूप में बनाया जाना चाहिए (जो फ्लोचार्ट में होता है)।
डेटा संतुलन सुनिश्चित करना ⚖️
डीएफडी में सबसे महत्वपूर्ण तकनीकी आवश्यकताओं में से एक संतुलन है। संतुलन सुनिश्चित करता है कि माता-पिता प्रक्रिया में प्रवेश करने वाला डेटा और उससे बाहर निकलने वाला डेटा निम्न स्तर के आरेख में उसके बच्चे प्रक्रियाओं में प्रवेश करने वाले और बाहर निकलने वाले डेटा के समान हो।
संतुलन क्यों महत्वपूर्ण है
संतुलन के बिना, विघटन के दौरान जानकारी खो जाती है या बनाई जाती है। इससे उच्च स्तर के अवलोकन और विस्तृत कार्यान्वयन योजना के बीच अंतर आता है।
संतुलन की पुष्टि कैसे करें
- इनपुट मिलान: बच्चे के आरेख में प्रवेश करने वाले डेटा प्रवाहों का योग माता-पिता प्रक्रिया में प्रवेश करने वाले डेटा प्रवाहों के बराबर होना चाहिए।
- आउटपुट मिलान: बच्चे के आरेख से बाहर निकलने वाले डेटा प्रवाहों का योग माता-पिता प्रक्रिया से बाहर निकलने वाले डेटा प्रवाहों के बराबर होना चाहिए।
- डेटा स्टोर सुसंगतता: यदि एक पितृ प्रक्रिया एक डेटा स्टोर को प्राप्त करती है, तो उसी स्टोर को प्राप्त करने वाली बच्ची प्रक्रियाओं को समान इनपुट/आउटपुट संबंध बनाए रखना चाहिए।
- पुनर्प्रमाणीकरण: हर बार जब आप एक प्रक्रिया को विभाजित करते हैं, तो आपको संतुलन की पुनराप्रमाणीकरण करना होगा। जूम-इन प्रक्रिया के दौरान डेटा प्रवाह को खो देना आसान है।
नामकरण प्रथाएं और स्पष्टता 🏷️
एक आरेख एक संचार उपकरण है। यदि नाम अस्पष्ट हैं, तो संचार विफल हो जाता है। स्पष्ट नामकरण प्रथाएं समीक्षा के दौरान मौखिक व्याख्या की आवश्यकता को कम करती हैं।
प्रक्रिया नामकरण
- क्रिया-संज्ञा संरचना: प्रक्रियाओं के नाम क्रिया के बाद संज्ञा के साथ रखें (उदाहरण के लिए, “कर की गणना करें”, “इन्वेंटरी अपडेट करें”)।
- एकल नाम: “प्रक्रिया 1” या “कुछ करें” जैसे सामान्य नामों से बचें। प्रत्येक प्रक्रिया का एक अद्वितीय, वर्णनात्मक नाम होना चाहिए।
- सुसंगतता: यदि आप एक आरेख में इसे “उपयोगकर्ता की पुष्टि करें” कहते हैं, तो दूसरे में इसे “लॉगिन जांचें” न कहें। सभी स्तरों पर एक ही शब्दावली का उपयोग करें।
डेटा स्टोर नामकरण
- संज्ञा वाक्यांश: डेटा स्टोर के नाम बहुवचन संज्ञा के साथ रखे जाने चाहिए (उदाहरण के लिए, “ग्राहक रिकॉर्ड”, “आदेश लॉग”)।
- तार्किक बनाम भौतिक: भौतिक कार्यान्वयन के आधार पर डेटा स्टोर के नाम न रखें (उदाहरण के लिए, “SQL_Table_1”)। सामग्री का वर्णन करने वाले तार्किक नाम का उपयोग करें (उदाहरण के लिए, “ग्राहक डेटाबेस”)।
- एकाकीपन: सुनिश्चित करें कि कोई भी दो डेटा स्टोर एक ही नाम साझा न करें, भले ही वे अलग-अलग आरेखों में हों।
डेटा प्रवाह नामकरण
- विशिष्ट डेटा: किसी प्रवाह को “डेटा” के रूप में लेबल न करें। विशिष्ट हों (उदाहरण के लिए, “शिपिंग पता”, “भुगतान पुष्टि”)।
- अवस्था परिवर्तन: यदि डेटा की अवस्था बदलती है (उदाहरण के लिए, “ड्राफ्ट आदेश” को “अंतिम आदेश” में बदल दिया जाता है), तो डेटा प्रवाह लेबल में इस अंतर को दर्शाना चाहिए या प्रक्रिया का नाम इस परिवर्तन को दर्शाने के लिए होना चाहिए।
बचने के लिए सामान्य त्रुटियां ⚠️
यहां तक कि अनुभवी विश्लेषक भी जाल में फंस जाते हैं। यहां डीएफडी की गुणवत्ता को कम करने वाली सबसे आम त्रुटियां हैं।
- सीधे संस्था-से-संस्था प्रवाह: डेटा एक बाहरी संस्था से दूसरी बाहरी संस्था में सीधे प्रवाहित नहीं हो सकता, बिना सिस्टम सीमा के भीतर एक प्रक्रिया से गुजरे। इससे सिस्टम तर्क को छोड़ दिया जाता है।
- डेटा स्टोर से डेटा स्टोर प्रवाह: डेटा एक डेटा स्टोर से दूसरे डेटा स्टोर में सीधे नहीं जा सकता है। इसे एक प्रक्रिया द्वारा पढ़ा जाना चाहिए, परिवर्तित किया जाना चाहिए, और फिर नए स्टोर में लिखा जाना चाहिए।
- नियंत्रण और डेटा को गलती से मिलाना: “बटन क्लिक करें” या “समय सीमा समाप्त” जैसे सिग्नल घटनाएँ हैं, डेटा नहीं। उन्हें डेटा प्रवाह के रूप में नहीं बनाया जाना चाहिए, जब तक कि वे सूचना पेलोड नहीं ले रहे हों।
- अत्यधिक जटिलता: एक ही आरेख पर बहुत अधिक विवरण न डालें। यदि एक आरेख में 7 से 9 प्रक्रियाओं से अधिक हैं, तो यह एक ही दृश्य के लिए अत्यधिक जटिल होने की संभावना है। इसे तोड़ने के लिए विघटन का उपयोग करें।
- संदर्भ का अभाव: कभी भी लेवल 1 या लेवल 2 आरेख को संदर्भ बिंदु के रूप में संदर्भ आरेख (लेवल 0) के बिना प्रस्तुत न करें।
हितधारक प्रमाणीकरण 🤝
तकनीकी सटीकता केवल आधा युद्ध है। आरेख को उन लोगों द्वारा समझा जाना चाहिए जो प्रणाली को बनाएंगे और उपयोग करेंगे। प्रमाणीकरण में हितधारकों के सक्रिय भागीदारी शामिल है।
- वॉकथ्रू: ऐसे सत्रों की योजना बनाएं जहां आप हितधारक के साथ मौखिक रूप से डेटा प्रवाह का अनुसरण करें। उनसे एक विशिष्ट लेनदेन के शुरू से अंत तक अनुसरण करने के लिए कहें।
- प्रश्न प्रेरक: आरेख की दृढ़ता का परीक्षण करने के लिए प्रश्न पूछें, जैसे, “यदि यह डेटा गायब हो जाए तो क्या होगा?” या “इस सूचना को कहाँ संग्रहीत किया गया है?”
- अंतर विश्लेषण: आरेख की आवश्यकता दस्तावेज़ के बराबर तुलना करें। सुनिश्चित करें कि प्रत्येक आवश्यकता जिसमें डेटा गतिशीलता शामिल है, दृश्य रूप से प्रस्तुत की गई है।
- विकासकर्मी प्रतिक्रिया: तकनीकी टीम को लागूता के लिए आरेख की समीक्षा करने के लिए कहें। वे डेटा स्टोरेज बॉटलनेक या तार्किक असंभवताओं को पहचान सकते हैं जो व्यावसायिक विश्लेषक छोड़ देते हैं।
रखरखाव और संस्करण नियंत्रण 🔄
प्रणालियाँ विकसित होती हैं। आवश्यकताएँ बदलती हैं। एक डीएफडी एक जीवित दस्तावेज़ है, एक स्थिर वस्तु नहीं। उचित रखरखाव सुनिश्चित करता है कि आरेख समय के साथ कार्यान्वयन योग्य बना रहे।
- संस्करण निर्धारण: अपने आरेखों को संस्करण संख्या दें (उदाहरण के लिए, v1.0, v1.1)। परिवर्तन की तारीख और अद्यतन के कारण का दस्तावेज़ीकरण करें।
- परिवर्तन लॉग: परिवर्तनों का अलग लॉग बनाए रखें। नोट करें कि किन प्रक्रियाओं को जोड़ा, हटाया या नाम बदला गया। इससे बाद में ऑडिटिंग और डीबगिंग में मदद मिलती है।
- आवश्यकताओं के साथ समन्वय करें: हर बार जब एक आवश्यकता बदलती है, तुरंत आरेख को अपडेट करें। आरेख को आवश्यकताओं से दूर होने न दें।
- पुराने संस्करणों को संग्रहीत करें: पिछले संस्करणों को उपलब्ध रखें। यदि एक नया फीचर पुराने वर्कफ्लो को तोड़ता है, तो पुराना आरेख लीगेसी व्यवहार के लिए एक संदर्भ के रूप में काम आता है।
अंतिम समीक्षा चरण 🔍
दस्तावेज़ीकरण को अंतिम रूप देने से पहले, इस त्वरित चेकलिस्ट का उपयोग करके अंतिम जांच करें।
- क्या सभी प्रक्रियाओं को सही तरीके से नंबर दिया गया है?
- क्या प्रत्येक डेटा प्रवाह एक संज्ञा वाक्यांश के साथ चिह्नित है?
- क्या सभी डेटा स्टोर कम से कम एक प्रक्रिया से प्राप्त किए जा सकते हैं?
- क्या आरेख सभी स्तरों पर संतुलित है?
- क्या बाहरी एकाधिकार केवल प्रक्रियाओं से जुड़े हैं?
- क्या सिस्टम सीमा स्पष्ट रूप से परिभाषित है?
- क्या कोई तैरते तत्व या असंबंधित घटक हैं?
- क्या प्रतिपादन दस्तावेज के सभी हिस्सों में संगत है?
इन दिशानिर्देशों का पालन करने से आप सुनिश्चित करते हैं कि आपके डेटा प्रवाह आरेख केवल चित्रण नहीं हैं, बल्कि सिस्टम वास्तुकला के भरोसेमंद नक्शे हैं। अच्छी तरह से प्रमाणित DFD विकास के पुनरावृत्ति को कम करता है, संचार को स्पष्ट करता है, और यह सुनिश्चित करता है कि अंतिम उत्पाद इच्छित डेटा आवश्यकताओं को पूरा करता है।
 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online