 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











एक डेटा फ्लो डायग्राम (DFD) एक प्रणाली के माध्यम से जानकारी के आवागमन का दृश्य प्रतिनिधित्व है। यह प्रणाली के बाहरी रूप के बारे में नहीं है, बल्कि डेटा के प्रसंस्करण, भंडारण और स्थानांतरण के बारे में है। विश्लेषकों और वास्तुकारों के लिए, इस नोटेशन को समझना जटिल कार्यप्रवाहों को समझने के लिए आवश्यक है, ताकि तकनीकी कार्यान्वयन विवरणों में फंसे न रहें।
यह मार्गदर्शिका DFD के अनातम को समझाती है। हम इन आरेखों के निर्माण करने वाले पांच मुख्य तत्वों का अध्ययन करेंगे, उनके बीच बातचीत का अध्ययन करेंगे, और व्यावहारिक उदाहरण प्रदान करेंगे। अंत तक, आप स्पष्ट और क्रियान्वयन योग्य प्रणाली नक्शा बनाने के लिए आवश्यक संरचनात्मक ठोसता को समझ लेंगे।
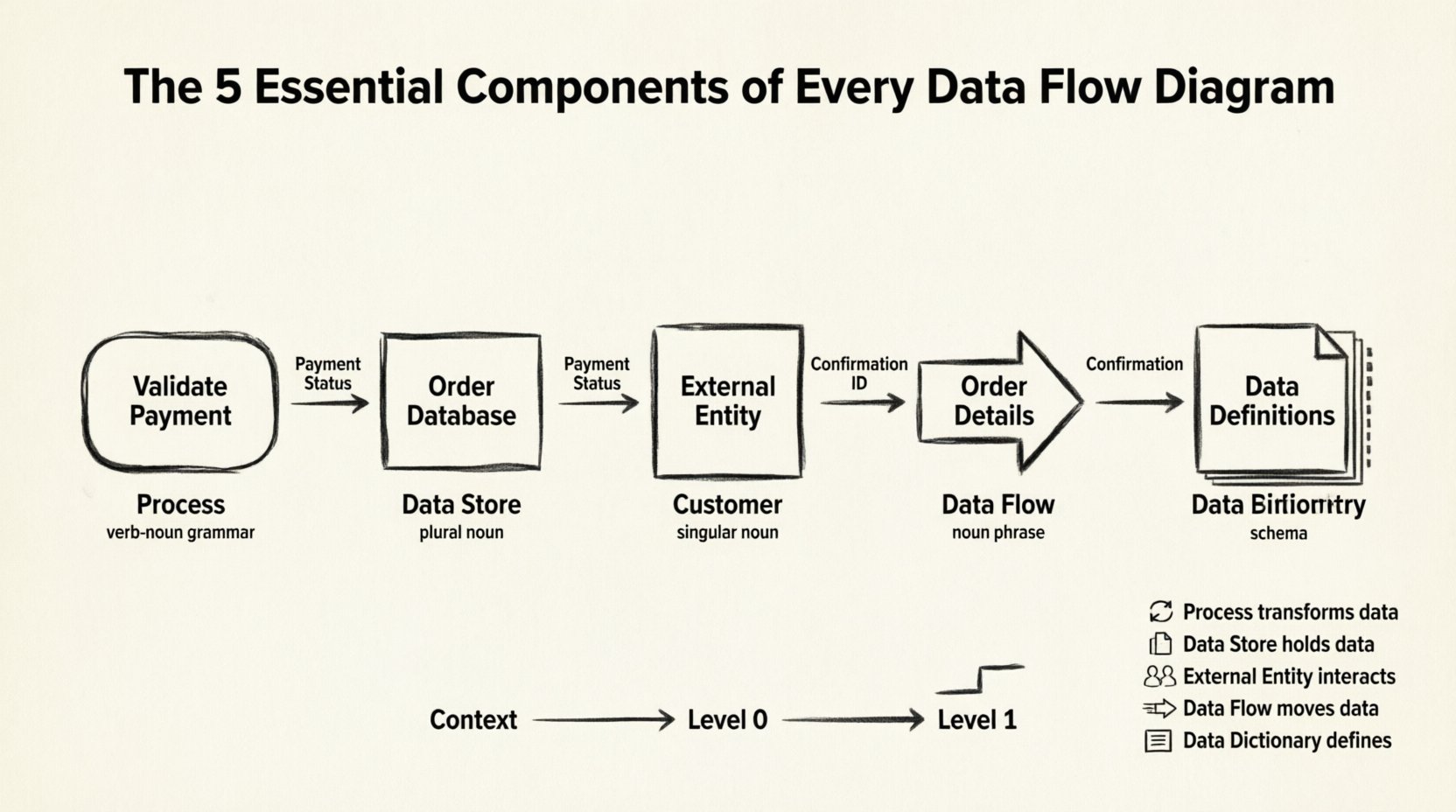
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। एक फ्लोचार्ट के विपरीत जो नियंत्रण तर्क और निर्णय बिंदुओं पर ध्यान केंद्रित करता है, एक DFD डेटा गति पर ध्यान केंद्रित करता है। यह भौतिक कार्यान्वयन को सारांशित करता है ताकि सूचना के तार्किक प्रवाह को दिखाया जा सके।
DFD हीरार्किक होते हैं। वे एक उच्च स्तर के दृश्य से शुरू होते हैं और विशिष्ट विवरणों में गहराई तक जाते हैं। इस परतदार दृष्टिकोण से स्टेकहोल्डर्स को प्रणाली को एक नजर में समझने में सक्षम होते हैं, जबकि डेवलपर्स को विशिष्ट डेटा आवश्यकताओं को देखने में सक्षम होते हैं।
एक वैध DFD बनाने के लिए, आपको पांच विशिष्ट तत्वों को शामिल करना होगा। जबकि पहले चार आलेखी प्रतीक हैं, पांचवां एक अवधारणात्मक आवश्यकता है जो सटीकता के लिए आवश्यक है।
एक प्रक्रिया एक ऐसे कार्य का प्रतिनिधित्व करती है जो इनपुट डेटा को आउटपुट डेटा में बदलती है। यह प्रणाली का इंजन है। DFD में, एक प्रक्रिया अक्सर एक गोलाकार आयत या एक वृत्त के रूप में दिखाई जाती है, नोटेशन शैली के अनुसार (यौरडॉन/डेमार्को बनाम गेने/सर्सन)।
मुख्य विशेषताएं:
उदाहरण:एक ई-कॉमर्स प्रणाली को ध्यान में रखें। एक प्रक्रिया हो सकती है“भुगतान की पुष्टि करें”। यह क्रेडिट कार्ड डेटा (इनपुट) प्राप्त करता है और अनुमोदन या अस्वीकृति कोड (आउटपुट) वापस करता है।
एक डेटा स्टोर वह स्थान है जहां सूचना बाद में उपयोग के लिए रखी जाती है। यह एक डेटाबेस, एक फ़ाइल, एक कागजी फाइल बॉक्स या कोई भी स्थायित्व तंत्र का प्रतिनिधित्व करता है। महत्वपूर्ण बात यह है कि एक डेटा स्टोर डेटा को प्रसंस्कृत नहीं करता है; यह बस इसे रखता है।
मुख्य विशेषताएं:
उदाहरण: एक पुस्तकालय प्रणाली में, “पुस्तक भंडार” डेटा भंडार उपलब्ध पुस्तकों के विवरण रखता है। जब कोई पुस्तक ली जाती है या वापस की जाती है, तो इसे अद्यतन किया जाता है।
बाहरी एकाधिकारी मॉडल की जाने वाली प्रणाली की सीमा के बाहर डेटा के स्रोत या गंतव्य हैं। वे लोगों, संगठनों या अन्य प्रणालियों का प्रतिनिधित्व करते हैं जो मुख्य प्रणाली के साथ अंतरक्रिया करते हैं लेकिन इसकी आंतरिक तर्क का हिस्सा नहीं हैं।
मुख्य विशेषताएँ:
उदाहरण: एक वेतन प्रणाली में, “कर्मचारी” घंटे काम करने वाले और वेतन प्राप्त करने वाले एक बाहरी एकाधिकारी है।
डेटा प्रवाह प्रक्रियाओं, डेटा भंडार और बाहरी एकाधिकारियों को जोड़ने वाले तीर हैं। वे डेटा की गति का प्रतिनिधित्व करते हैं। एक डेटा प्रवाह का नाम होना चाहिए जो स्थानांतरित डेटा की सामग्री का वर्णन करे।
मुख्य विशेषताएँ:
उदाहरण: एक तीर जो “लॉगिन” प्रक्रिया को “उपयोगकर्ता डेटाबेस” डेटा स्टोर को लेबल किया जाता है “प्रमाणीकरण अनुरोध”.
आरेख में खींचे नहीं गए होने के बावजूद, डेटा शब्दकोश एक पूर्ण DFD विवरण का पांचवां महत्वपूर्ण घटक है। यह एक केंद्रीकृत भंडार है जो आरेख में उपयोग किए जाने वाले प्रत्येक डेटा तत्व की संरचना, प्रकार और प्रारूप को परिभाषित करता है। इसके बिना, आरेख अस्पष्ट हो जाता है।
मुख्य विशेषताएँ:
उदाहरण: शब्दकोश में हो सकता है कि “जन्म तिथि” के रूप में YYYY-MM-DD कोई खाली मान नहीं। इससे प्रक्रियाओं में तर्क त्रुटियाँ रोकी जाती हैं।
डिज़ाइन चरण के दौरान प्रत्येक घटक के गुणों को त्वरित रूप से संदर्भित करने के लिए इस सारणी का उपयोग करें।
| घटक | प्रतीक आकृति | कार्य | उदाहरण लेबल | व्याकरण नियम |
|---|---|---|---|---|
| प्रक्रिया | गोल आयत / वृत्त | डेटा को परिवर्तित करता है | कर की गणना करें | क्रिया + संज्ञा |
| डेटा भंडार | खुला आयत / समानांतर रेखाएं | डेटा भंडारित करता है | आदेश इतिहास | संज्ञा (बहुवचन) |
| बाहरी एकाई | वर्ग / आयत | स्रोत/स्त्रोत | बैंक प्रणाली | संज्ञा (एकवचन) |
| डेटा प्रवाह | तीर | डेटा को हटाता है | भुगतान विवरण | संज्ञा वाक्यांश |
| डेटा शब्दकोश | दस्तावेज / सूची | डेटा को परिभाषित करता है | डेटा परिभाषाएं | तकनीकी योजना |
डीएफडी को अक्सर अलग-अलग नहीं बनाया जाता है। वे एक विशेष वर्गीकरण में मौजूद होते हैं जो विभिन्न स्तरों के सारांश की अनुमति देते हैं। इन स्तरों को समझने से यह सुनिश्चित होता है कि प्रत्येक चरण पर 5 घटकों का सही तरीके से उपयोग किया जाता है।
यह सबसे ऊंचा स्तर का दृश्य है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है। यह बाहरी संस्थाओं और प्रणाली में प्रवेश या निकास होने वाली प्रमुख डेटा प्रवाहों की पहचान करता है।
यह आरेख संदर्भ आरेख से एकल प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित करता है। यह आ inter डेटा भंडार और प्रक्रियाओं की पहली परत का परिचय देता है।
इस स्तर को स्तर 0 प्रक्रियाओं को उनके संघटक कार्यों में विभाजित करता है। इसका उपयोग विस्तृत डिजाइन और विकास के लिए किया जाता है।
DFD बनाना एक आवर्ती प्रक्रिया है। आरेख के उपयोगी और सटीक रहने की गारंटी के लिए, इन संरचनात्मक नियमों का पालन करें।
जब आप एक प्रक्रिया को निम्न स्तरों में विभाजित करते हैं, तो इनपुट और आउटपुट को संगत रहना चाहिए। यदि एक मातृ प्रक्रिया को “आदेश डेटा” प्राप्त होता है, तो बच्चे की प्रक्रियाओं को उसी “आदेश डेटा” को संयुक्त रूप से संभालना चाहिए। आप बिना कुछ से डेटा नहीं बना सकते या उसे नष्ट नहीं कर सकते।
संगतता महत्वपूर्ण है। सभी घटकों के लिए एक मानकीकृत नामकरण प्रणाली का उपयोग करें। संक्षिप्त रूपों से बचें, जब तक कि वे आपके संगठन में सार्वभौमिक रूप से समझे न जाएँ। सुनिश्चित करें कि एक आरेख में “इन्वॉइस” के रूप में चिह्नित डेटा प्रवाह दूसरे आरेख में “बिल” के रूप में न चिह्नित हो।
एक सामान्य गलती नियंत्रण तर्क (if/else) को DFD में मिलाना है। DFDs डेटा गति को दिखाते हैं, निर्णय तर्क को नहीं। नियंत्रण तर्क के लिए निर्णय तालिका या प्रवाहचित्र का उपयोग करें। DFD में, एक निर्णय बिंदु एक प्रक्रिया द्वारा दर्शाया जाता है जो इनपुट पर आधारित विभिन्न डेटा प्रवाह उत्पन्न करता है।
डेटा स्टोर को इनपुट और आउटपुट दोनों होने चाहिए, अन्यथा यह एक नया निर्माण या आर्काइव है। एक ऐसा स्टोर जो केवल डेटा प्राप्त करता है, एक काला छेद है। एक ऐसा स्टोर जो केवल डेटा प्रदान करता है, एक चमत्कार है (किसी भी चीज के बिना निर्माण)। दोनों सिस्टम तर्क के विरुद्ध हैं।
यहां तक कि अनुभवी मॉडलर भी गलतियां करते हैं। इन सामान्य जाल में से बचने की समीक्षा विश्लेषण चरण के दौरान समय बचा सकती है।
आइए 5 घटकों को एक वास्तविक दुनिया के परिदृश्य में लागू करें। एक सरलीकृत ऑनलाइन आदेश प्रणाली की कल्पना करें।
DFD का एक खाली स्थान में अस्तित्व नहीं होता है। वे अक्सर अन्य मॉडलिंग तकनीकों के पूरक होते हैं।
अपने डेटा फ्लो डायग्राम्स से मूल्य प्राप्त करने के लिए, निम्नलिखित सिद्धांतों को ध्यान में रखें।
इन पांच घटकों के कठोर रूप से अनुप्रयोग और संरचनात्मक नियमों के अनुसरण करके, आप प्रणाली विकास के लिए एक टिकाऊ ब्लूप्रिंट बनाते हैं। इस स्पष्टता से अस्पष्टता कम होती है, पुनरावृत्ति कम होती है, और यह सुनिश्चित करती है कि अंतिम कार्यान्वयन इच्छित डेटा संरचना के अनुरूप है।
याद रखें, एक DFD एक जीवित दस्तावेज है। जैसे ही आवश्यकताएं बदलती हैं, डायग्राम को प्रणाली की नई वास्तविकता को दर्शाने के लिए विकसित करना होगा। डायग्राम और उसके साथ आने वाले डेटा डिक्शनरी का नियमित रखरखाव परिपक्व विश्लेषण प्रक्रिया की पहचान है।