 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online











La création d’un diagramme de flux de données (DFD) est une étape importante dans l’analyse des systèmes. Il cartographie le déplacement des données à travers un système, en définissant comment les informations sont traitées, stockées et transférées. Toutefois, un diagramme qui semble visuellement attrayant n’est pas nécessairement fonctionnellement précis. La validation est la phase cruciale où vous vérifiez que le diagramme représente correctement les exigences du système sans erreurs logiques. Ce processus garantit que les flux de données sont cohérents, que les processus sont équilibrés et que la structure soutient la logique métier souhaitée.
La validation n’est pas une simple action, mais une revue rigoureuse. Elle exige une approche méthodique pour vérifier chaque élément par rapport aux règles établies. En suivant un processus de revue structuré, vous éliminez toute ambiguïté et vous assurez que le diagramme sert de plan fiable pour le développement et la communication avec les parties prenantes. Ce guide décrit les étapes complètes nécessaires pour valider efficacement votre DFD, garantissant ainsi précision et cohérence tout au long de la conception du système.
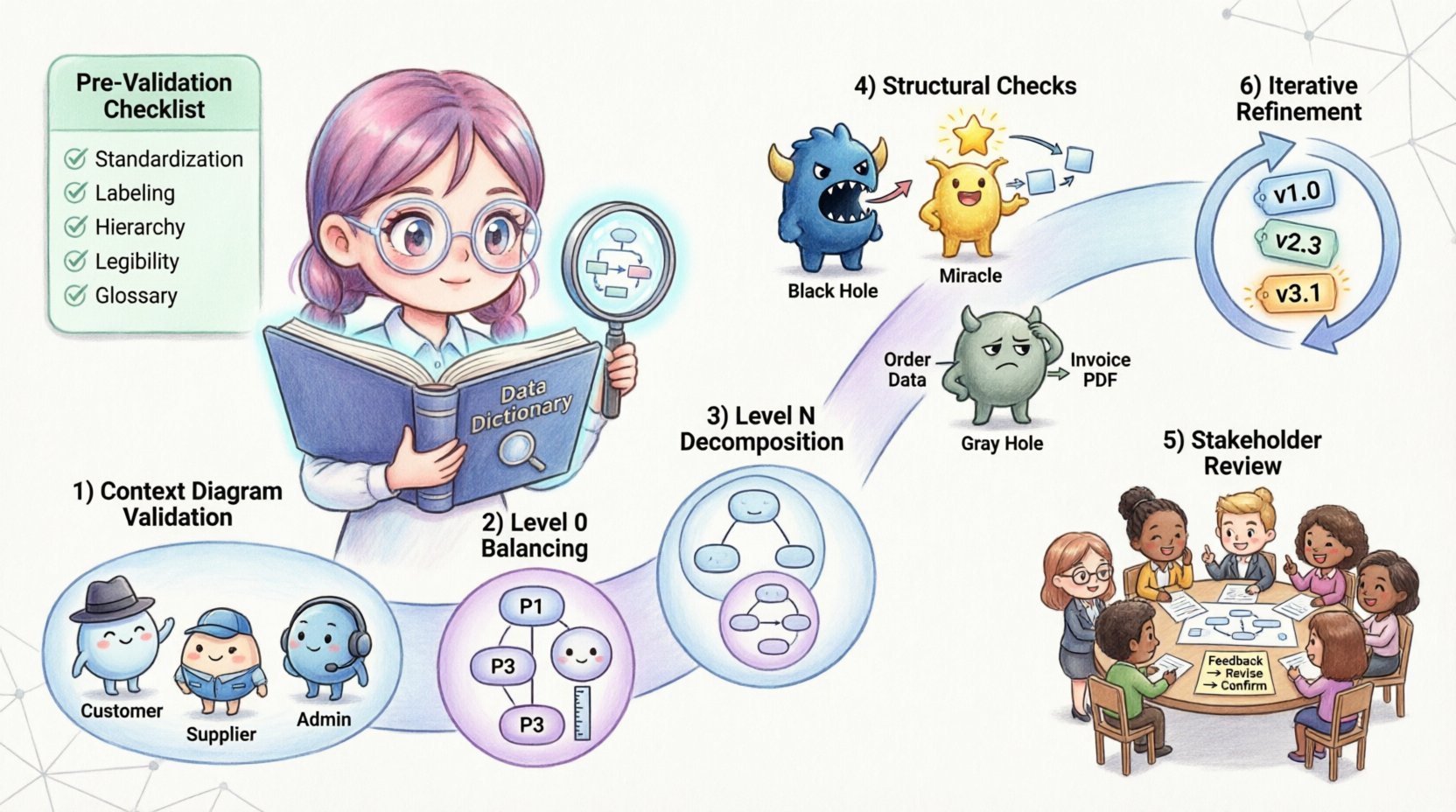
Avant de plonger dans les étapes spécifiques, il est essentiel de comprendre ce que la validation permet d’accomplir dans le contexte de la conception des systèmes. La vérification demande : « Construisons-nous le produit correctement ? » La validation demande : « Construisons-nous le bon produit ? » Dans le contexte des DFD, la validation comble le fossé entre les exigences abstraites et le comportement concret du système.
Un DFD validé garantit :
Sauter cette phase conduit souvent à des reprises coûteuses pendant la phase de développement. Des problèmes tels que des flux de données manquants ou des entrepôts de données non définis sont coûteux à corriger une fois que le code est en cours d’écriture. Un processus de revue rigoureux atténue ces risques dès le début.
Avant de commencer la revue formelle, assurez-vous que le diagramme est prêt à être examiné. Un diagramme en désordre ou mal organisé rend la validation difficile. Utilisez la liste suivante pour préparer votre travail :
Le diagramme de contexte est le niveau d’abstraction le plus élevé. Il représente le système comme un seul processus et ses interactions avec les entités externes. C’est la première ligne de défense dans la validation.
Les entités externes représentent des sources ou des destinations de données situées à l’extérieur des limites du système. Assurez-vous que chaque entité affichée est nécessaire et clairement définie. Posez les questions suivantes :
Le processus unique représentant le système doit contenir toute la logique interne. Vérifiez qu’aucun flux de données ne traverse la frontière sans passer par ce processus. Si les données passent d’une entité externe à une autre sans entrer dans le système, elles ne doivent pas être affichées sur le diagramme de contexte, car elles sortent du périmètre.
Examinez chaque flèche connectée au processus central. Chaque entrée doit avoir une sortie correspondante ou une action de stockage. Si un flux de données entre dans le système mais que rien ne sort, cela peut indiquer un processus « trou noir », où les données disparaissent sans raison.
Le DFD Niveau 0 décompose le processus unique du diagramme de contexte en sous-systèmes majeurs. La règle la plus critique ici estl’équilibre. Les entrées et sorties du processus parent doivent correspondre exactement aux entrées et sorties des processus enfants.
Pour chaque flux de données entrant dans le processus du diagramme de contexte, il doit y avoir un flux de données correspondant entrant dans le diagramme Niveau 0. La même règle s’applique aux sorties. Cela s’appelle la conservation des données. Si le diagramme de contexte montre « Commande client » entrant dans le système, le diagramme Niveau 0 doit montrer « Commande client » entrant dans au moins un des processus majeurs.
Le Niveau 0 contient généralement entre 3 et 7 processus. Si vous en avez plus de 7, le diagramme peut être trop complexe pour une seule vue. Si vous en avez moins de 3, vous devrez peut-être le décomposer davantage. Assurez-vous que chaque processus est distinct et effectue une seule fonction logique.
Vérifiez que chaque magasin de données au Niveau 0 est nécessaire. Un magasin de données ne doit exister que si les données doivent être conservées pour une utilisation ultérieure. Assurez-vous que les flux de données entrant et sortant des magasins sont correctement étiquetés. Les magasins de données ne doivent pas être connectés directement aux entités externes ; toutes les données doivent passer par un processus.
Les diagrammes Niveau N fournissent des détails supplémentaires pour des processus spécifiques identifiés au Niveau 0. La validation à ce niveau se concentre sur la cohérence avec le processus parent.
Tout comme au Niveau 0, les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties agrégées de ses enfants. Si le processus 1.0 prend « Données de connexion » et produit « Jeton d’accès » dans le diagramme Niveau 0, la décomposition Niveau 1 du processus 1.0 doit également accepter « Données de connexion » et produire « Jeton d’accès ».
Assurez-vous que la décomposition est logique. Le diagramme enfant explique-t-ilcommentle fonctionnement du processus parent ? Évitez d’introduire de nouvelles entités externes ou magasins de données dans un diagramme enfant qui n’étaient pas implicites dans le parent. Si un nouveau magasin de données est introduit, il doit être justifié par la nécessité de conserver des données.
Les étiquettes des flux de données dans les diagrammes enfants doivent correspondre aux étiquettes du diagramme parent là où cela s’applique. Si un flux est affiné dans un diagramme enfant (par exemple, « Données » devient « Données utilisateur »), ce changement doit être cohérent avec le dictionnaire des données. L’ambiguïté ici crée de la confusion lors de l’implémentation.
Il existe des anomalies structurelles spécifiques qui indiquent des erreurs dans la conception du DFD. Ces modèles courants doivent être identifiés et corrigés lors de la validation.
Un processus trou noir est un processus qui possède des entrées mais aucune sortie. Les données entrent dans le processus et disparaissent. Cela indique généralement un flux de sortie manquant ou une définition de processus incomplète. Chaque processus doit produire un résultat, qu’il s’agisse de données à stocker, de données à envoyer ailleurs ou d’un résultat de décision.
Un processus miracle est un processus qui possède des sorties mais aucune entrée. Il crée des données à partir de rien. Cela est logiquement impossible dans une conception de système. Chaque sortie doit être générée à partir de données d’entrée ou dérivée de données stockées.
Un trou gris se produit lorsque les entrées ne correspondent pas logiquement aux sorties. Par exemple, si l’entrée est « Adresse du client » et la sortie « Détails de paiement », le processus effectue plus qu’une simple transformation ; il crée des données qui ne peuvent pas être déduites de l’entrée. Cela suggère des flux de données manquants ou des magasins de données absents.
Assurez-vous que les flux de données ne vont pas directement d’une entité externe à un magasin de données. Toutes les données entrant ou sortant d’un magasin doivent passer par un processus. Cela garantit que les règles d’intégrité des données et la logique métier sont appliquées avant le stockage.
Utilisez ce tableau comme référence rapide lors de vos sessions de revue. Il résume les règles essentielles et les vérifications spécifiques requises pour chaque élément.
| Élément | Règle de validation | Erreur courante |
|---|---|---|
| Processus | Doit avoir au moins une entrée et une sortie | Processus trou noir ou miracle |
| Magasin de données | Doit être connecté à un processus, et non à une entité | Flux direct entité-vers-magasin |
| Flux de données | Doit être étiqueté avec une phrase nominale | Étiquettes verbales ou étiquettes manquantes |
| Entité externe | Doit être à l’extérieur des limites du système | Entité à l’intérieur des limites du système |
| Consistance | Les entrées/sorties parent et enfant doivent correspondre | Flux de données déséquilibrés |
| Décomposition | L’enfant doit expliquer « comment », et non « pourquoi » | Ajout de logique hors du périmètre |
La validation n’est pas seulement un contrôle technique ; c’est un outil de communication. Une fois que les règles techniques sont respectées, le diagramme doit être revu par les parties prenantes afin de s’assurer qu’il répond aux besoins métiers.
Ne présentez pas le diagramme en isolation. Préparez une présentation guidée qui explique le flux des données. Fournissez le contexte expliquant pourquoi certains entrepôts de données existent et comment les processus interagissent. Assurez-vous que toutes les parties prenantes ont accès au dictionnaire des données pour comprendre la terminologie.
Encouragez les parties prenantes à remettre en question le flux. Posez des questions spécifiques telles que :
Enregistrez tous les retours et les modifications proposées. Si une partie prenante suggère un nouveau flux de données, validez-le par rapport aux règles d’équilibre avant de l’accepter. Mettez à jour le diagramme et le dictionnaire des données simultanément pour maintenir la synchronisation. La gestion des versions est cruciale ; conservez des traces de l’état du diagramme à chaque cycle de revue.
La validation est rarement un événement ponctuel. Au fur et à mesure que les exigences évoluent, le DFD doit évoluer avec elles. Cette section traite de la gestion des modifications tout au long du cycle de vie du projet.
Lorsqu’une modification est demandée, analysez son impact sur toute la hiérarchie. Si un processus au niveau 1 change, cela affecte-t-il le niveau 0 ? Exige-t-il un nouvel entrepôt de données ? A-t-il un impact sur d’autres processus partageant le même flux de données ? Effectuer cette analyse des impacts permet d’éviter des erreurs en cascade.
Maintenez un historique clair des révisions du diagramme. Utilisez des numéros de version (par exemple, v1.0, v1.1) et des dates de révision. Cela permet à l’équipe de suivre l’évolution du design du système et de revenir en arrière si nécessaire. Bien que des outils spécifiques ne soient pas requis, une convention de nommage rigoureuse pour les fichiers est essentielle.
Après avoir mis en œuvre les modifications, exécutez à nouveau le processus de validation. Ne supposez pas qu’une petite modification préserve l’intégrité de l’ensemble. Vérifiez à nouveau les règles d’équilibre, les conventions de nommage et l’intégrité structurelle. Une petite modification peut parfois rompre l’équilibre d’un diagramme précédemment validé.
Le dictionnaire des données est le pilier de votre DFD. Il définit la structure de chaque élément de données. La validation doit aller au-delà du diagramme visuel pour inclure les définitions textuelles.
Assurez-vous que les étiquettes des flux de données sur le diagramme correspondent exactement aux entrées du dictionnaire. Si le diagramme indique « ID de facture » et que le dictionnaire dit « Identifiant de facture », cette incohérence peut entraîner de la confusion lors de la conception de la base de données. Standardisez la terminologie dans tous les documents.
Vérifiez que chaque entrepôt de données a une structure définie dans le dictionnaire. Liste les attributs, les types de données et les contraintes clés. Si un entrepôt de données est référencé dans le DFD mais qu’il n’a pas d’entrée dans le dictionnaire, le design est incomplet. Ce manque entraîne souvent des erreurs de base de données ultérieurement.
Validez que les types de données implicites dans le diagramme correspondent aux règles métiers. Par exemple, si un flux de données représente « Date de naissance », il ne doit pas être traité comme une chaîne de caractères dans le dictionnaire. Il doit avoir un format de date. Ce niveau de détail garantit que la mise en œuvre technique s’aligne sur le design conceptuel.
Même les analystes expérimentés rencontrent des pièges spécifiques lors du processus de validation. Être conscient de ces pièges courants vous aide à mieux naviguer la revue.
Une fois la validation terminée, la documentation doit être finalisée avant remise à l’équipe de développement. Cela implique la compilation des diagrammes, du dictionnaire des données et du rapport de validation.
Réunissez tous les diagrammes de niveau 0, les diagrammes de niveau N et le diagramme de contexte dans un seul ensemble. Assurez-vous que la hiérarchie est clairement indiquée afin que les développeurs puissent suivre la décomposition. Incluez le dictionnaire des données comme document complémentaire.
Créez un rapport récapitulatif du processus de validation. Listez tous les problèmes identifiés lors de la revue et comment ils ont été résolus. Ce document sert de preuve que le design a été validé. Il fournit également un contexte pour les futurs mainteneurs qui n’ont pas participé à la revue initiale.
Définissez le processus de remise des diagrammes de flux de données validés. Cela doit inclure une réunion où le design est expliqué à l’équipe de développement. Traitez toutes les questions concernant les flux ambigus ou les magasins de données complexes. Assurez-vous que l’équipe comprend que le DFD est la source de vérité pour les exigences de données.
Le travail ne s’arrête pas à la validation. Le diagramme doit rester précis au fur et à mesure que le système évolue. Mettez en place un processus de gouvernance pour les modifications futures.
En suivant ces étapes de validation, vous vous assurez que vos diagrammes de flux de données sont robustes, précis et utiles tout au long du cycle de vie du système. Cette discipline réduit l’ambiguïté, prévient les erreurs coûteuses et crée une base solide pour un développement système réussi.