Concevoir un système logiciel complexe exige une carte claire du déplacement des données et de leur emplacement. Sans une approche structurée, les architectures peuvent devenir fragiles, difficiles à maintenir et sujettes à des erreurs logiques. Deux des techniques fondamentales de modélisation en génie des systèmes sont le diagramme de flux de données (DFD) et le diagramme entité-association (MCD). Bien qu’ils servent tous deux la fonction essentielle de visualisation, ils traitent des aspects fondamentalement différents du système.
Comprendre la distinction entre ces deux modèles n’est pas simplement un exercice académique ; c’est une nécessité pratique pour les architectes système, les analystes métier et les développeurs. Utiliser le mauvais modèle à la mauvaise phase du développement peut entraîner des malentendus, des inefficacités de base de données ou une logique métier défaillante. Ce guide explore les subtilités de chaque type de diagramme, leurs composants spécifiques, ainsi que les scénarios stratégiques où l’un prévaut sur l’autre.
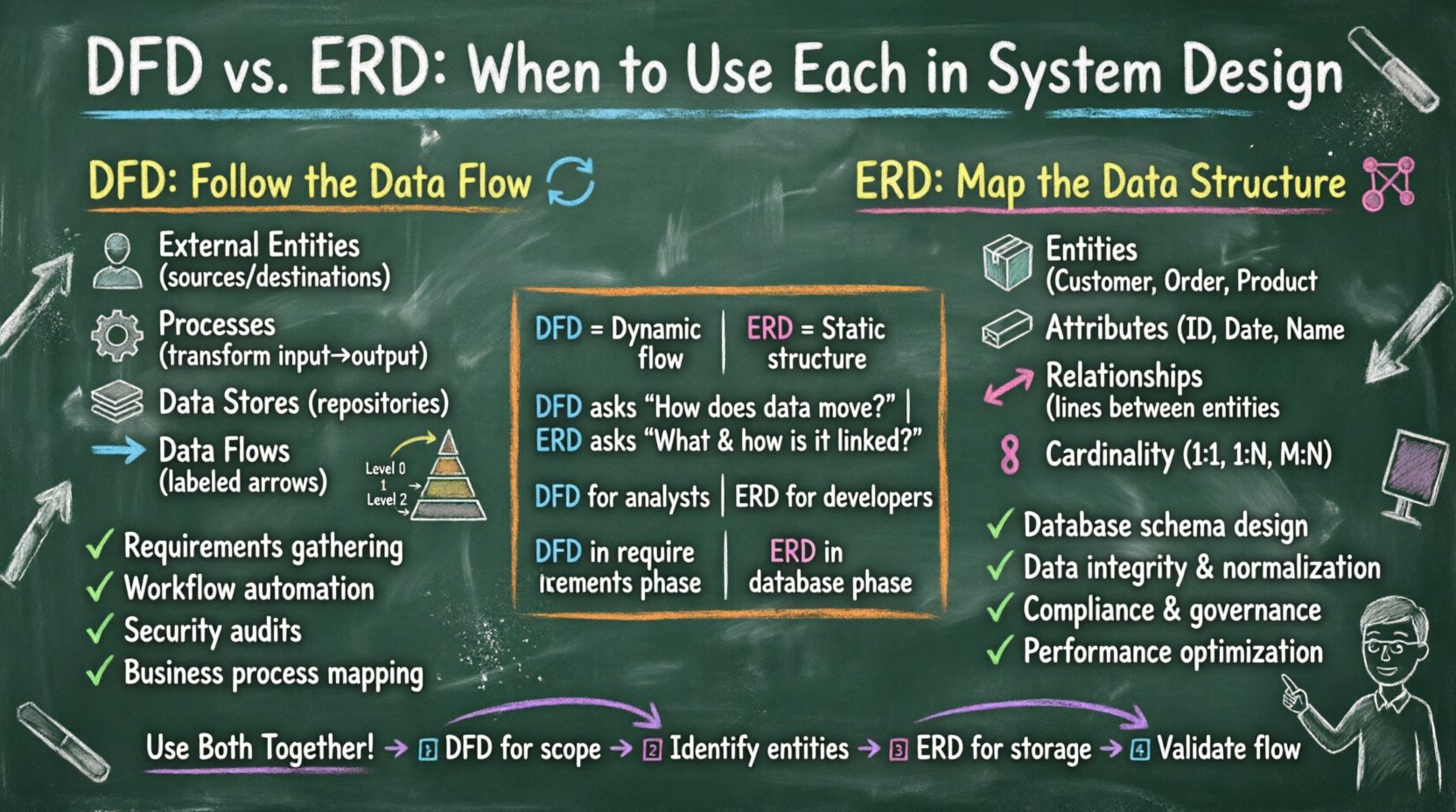
Comprendre le diagramme de flux de données (DFD) 🔄
Le diagramme de flux de données se concentre sur le déplacement des données à travers un système. Il visualise comment les informations sont traitées, transformées et stockées. Le DFD ne s’intéresse pas aux détails d’implémentation physique ni au moment des processus. Il fournit plutôt une vue d’ensemble du flux logique des informations.
Composants fondamentaux d’un DFD
- Entités externes : Elles représentent les sources ou destinations des données situées en dehors de la frontière du système. Elles peuvent être des utilisateurs, d’autres systèmes ou des organisations. Elles initient ou reçoivent des données, mais ne les traitent pas dans le cadre de ce modèle spécifique.
- Processus : Représentés par des rectangles arrondis, ce sont des activités qui transforment les données d’entrée en données de sortie. Un processus modifie l’état ou la forme de l’information qui le traverse. Il est essentiel que chaque processus dispose d’au moins une entrée et une sortie.
- Stockages de données : Ce sont des répertoires où les données sont conservées pour une utilisation ultérieure. Dans un DFD, ils représentent des fichiers, des bases de données ou des archives. Ils ne supposent pas une technologie spécifique, mais uniquement l’existence d’un stockage persistant.
- Flux de données : Représentés par des flèches, ils indiquent la direction du déplacement des données. Chaque flux doit être étiqueté par le nom du paquet de données transféré. Les flux de données relient les entités, les processus et les stockages.
Niveaux d’abstraction
Les DFD sont généralement créés de manière hiérarchique pour gérer la complexité :
- Diagramme de contexte (Niveau 0) : Il s’agit de la vue de niveau le plus élevé. Il représente l’ensemble du système comme un seul processus et identifie toutes les entités externes interagissant avec lui. Il définit clairement les frontières du système.
- Diagramme de niveau 1 : Il décompose le processus unique du diagramme de contexte en sous-processus principaux. Il fournit davantage de détails sur la manière dont le système gère les données à l’intérieur, sans s’embourber dans la logique.
- Niveau 2 et au-delà : Ces diagrammes décomposent des processus spécifiques du niveau 1 en détails supplémentaires. Ce niveau est souvent utilisé pour des modules complexes où des transformations de données spécifiques nécessitent une définition rigoureuse.
Quand appliquer le DFD
Les DFD sont les plus efficaces pendant les phases de collecte des exigences et de conception fonctionnelle. Ils aident les parties prenantes à visualiser le comportement du système sans être distraits par des contraintes techniques. Ils sont particulièrement utiles pour :
- Identifier les exigences de données manquantes.
- Communiquer les processus métiers aux parties prenantes non techniques.
- Définir le périmètre d’un projet.
- Analyser la sécurité de l’information en identifiant où les données sensibles entrent et sortent.
Comprendre le diagramme entité-association (MCD) 🔗
Alors que le DFD suit le mouvement, le diagramme entité-association se concentre sur la structure. Un MCD est un modèle conceptuel utilisé pour définir les exigences de données et les relations au sein d’une base de données. Il décrit la nature statique des données, garantissant l’intégrité et la normalisation.
Composantes principales d’un diagramme ER
- Entités : Représentées sous forme de rectangles, ce sont des objets ou des concepts du monde réel sur lesquels des données sont stockées. Des exemples incluent « Client », « Commande » ou « Produit ». Les entités sont les éléments de base de la structure des données.
- Attributs : Ce sont les propriétés ou caractéristiques d’une entité. Ils sont généralement listés à l’intérieur de la boîte de l’entité ou y reliés. Les attributs définissent les points de données spécifiques, tels que « Identifiant du client » ou « Date de commande ». Certains attributs servent de clés primaires, identifiant un enregistrement de manière unique.
- Relations : Représentées sous forme de losanges ou de lignes, elles définissent la manière dont les entités interagissent. Une relation indique qu’un enregistrement dans une entité est associé à un enregistrement dans une autre.
- Cardinalité : Cela définit la relation quantitative entre les entités. Les cardinalités courantes incluent Un-à-Un (1:1), Un-à-Plusieurs (1:N) et Plusieurs-à-Plusieurs (M:N). Comprendre la cardinalité est essentiel pour éviter la redondance des données.
Normalisation et intégrité des données
Les diagrammes ER sont souvent le point de départ de la normalisation. La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Un diagramme ER permet de visualiser le schéma logique avant la création des tables physiques. Il garantit que :
- Les données ne sont pas dupliquées de manière inutile.
- L’intégrité référentielle est maintenue (par exemple, une commande ne peut exister sans client).
- Les contraintes telles que l’unicité et les champs obligatoires sont claires.
Quand appliquer un diagramme ER
Les diagrammes ER sont essentiels pendant la phase de conception de base de données. Ils combler le fossé entre les exigences métier et la mise en œuvre technique. Ils sont particulièrement utiles lorsque :
- La conception du schéma pour une base de données relationnelle.
- La définition des contraintes de données et des règles de validation.
- Assurer la cohérence des données dans l’application.
- Planifier l’efficacité de la récupération des données et les stratégies d’indexation.
Différences clés en un coup d’œil 🆚
Comparer ces deux modèles côte à côte met en évidence leurs objectifs distincts. Bien qu’ils puissent sembler similaires en termes de complexité visuelle, leur intention diverge considérablement.
| Fonctionnalité |
Diagramme de flux de données (DFD) |
Diagramme d’entité-association (ERD) |
| Objectif principal |
Processus et déplacement des données |
Structure des données et relations |
| Dimension temporelle |
Dynamique (montre le flux dans le temps) |
Statique (montre la structure à un instant donné) |
| Question clé |
Comment les données circulent-elles ? |
Quelles données sont stockées et comment sont-elles liées ? |
| Public cible |
Analystes métiers, parties prenantes |
Administrateurs de bases de données, développeurs backend |
| Phase du cycle de vie |
Exigences, conception fonctionnelle |
Conception de base de données, mise en œuvre |
| Logique vs. Stockage |
Se concentre sur la logique |
Se concentre sur le stockage |
| Complexité |
Peut être complexe en raison de nombreux flux |
Peut être complexe en raison des relations |
Quand privilégier la modélisation du flux de données 📉
Il existe des scénarios spécifiques où le diagramme de flux de données (DFD) devient l’outil principal pour la conception du système. Choisir le DFD en premier est souvent la bonne approche lorsque la logique métier est la partie la plus complexe du système.
- Automatisation des flux de travail : Si le système implique des chaînes d’approbation complexes, des changements d’état ou des transactions à plusieurs étapes, un DFD clarifie la séquence des opérations. Il aide à identifier les points de congestion dans le processus.
- Intégrations externes : Lorsqu’un système interagit avec de nombreuses API externes ou systèmes hérités, le DFD aide à cartographier les points d’entrée et de sortie des données. Il évite la perte de données lors des transferts entre systèmes.
- Audits de sécurité : Les équipes de sécurité utilisent souvent les DFD pour suivre le parcours des données sensibles dans l’application. Elles peuvent identifier les points où le chiffrement est nécessaire ou où des contrôles d’accès doivent être appliqués.
- Réingénierie des processus métiers : Lors de l’optimisation des flux de travail existants, un DFD fournit une base de référence. Vous pouvez comparer le processus « Tel qu’il est » avec le processus « Tel qu’il devrait être » pour mesurer les améliorations.
Dans ces cas, se concentrer trop tôt sur le MCD peut masquer la logique du système. Une base de données peut être conçue parfaitement, mais si le flux de processus est défectueux, l’application échouera à répondre aux besoins des utilisateurs.
Quand privilégier la modélisation de la structure des données 🏗️
Inversement, il existe des situations où l’intégrité et la structure des données sont les facteurs clés de succès. Le MCD prime lorsque le volume de données, les relations et les contraintes sont les moteurs principaux.
- Applications intensives en données : Dans les systèmes tels que les plateformes d’analyse ou les entrepôts de données, la structure des données est primordiale. Un schéma ER garantit que le schéma supporte les requêtes complexes et les agrégations.
- Migration des systèmes hérités : Lors du déplacement des données d’un ancien système vers un nouveau, comprendre les relations existantes est essentiel. Un schéma ER aide à cartographier les anciennes tables vers les nouvelles structures, en garantissant que aucune donnée n’est perdue ou corrompue.
- Conformité et gouvernance : Les secteurs tels que la finance et la santé exigent une gouvernance stricte des données. Un schéma ER documente où se trouvent les données, qui en est propriétaire et comment elles sont liées aux autres points de données, facilitant ainsi les rapports de conformité.
- Exigences de haute performance : Si le système nécessite des opérations de lecture/écriture rapides, le schéma ER guide les stratégies d’indexation et de partitionnement. Comprendre les relations aide à concevoir efficacement les opérations de jointure.
Sauter la création du schéma ER dans ces scénarios peut entraîner une « base de données spaghetti » où les tables sont redondantes, les relations sont ambiguës et les performances se dégradent au fil du temps.
Intégrer les deux pour une architecture robuste 🤝
Bien qu’il soit utile de distinguer entre le DFD et le schéma ER, les systèmes les plus réussis utilisent souvent les deux. Ils sont complémentaires, et non exclusifs. Un processus de conception de système robuste passe généralement du flux à la structure.
L’approche séquentielle
- Définir le périmètre avec le DFD :Commencez par un diagramme de contexte pour comprendre les limites. Identifiez toutes les entrées et sorties.
- Décomposer les processus :Décomposez les processus pour comprendre les transformations spécifiques des données nécessaires.
- Identifier les entités de données : En analysant les flux de données, identifiez les objets persistants qui sont déplacés. Ceux-ci deviennent les entités candidates pour le schéma ER.
- Concevoir le schéma ER : Créez le diagramme d’entités et de relations pour définir comment ces entités sont stockées et liées.
- Valider le flux : Cartographiez les flux de données vers les tables de base de données. Assurez-vous que chaque processus du DFD a une opération de stockage correspondante dans le schéma ER.
Cartographie des magasins de données
Dans un DFD, un magasin de données est un espace réservé générique. Dans un schéma ER, ce même magasin de données devient une définition détaillée de table. Le processus de cartographie implique :
- Conversion des magasins de données DFD en entités ERD.
- Assurer que toutes les attributs des flux DFD sont pris en compte dans les attributs du schéma ER.
- Vérifier que la cardinalité dans le schéma ER supporte la multiplicité des flux dans le DFD.
Par exemple, si un DFD montre un « Client » envoyant plusieurs « Commandes », le schéma ER doit refléter une relation un-à-plusieurs entre les entités Client et Commande. Si le DFD implique une relation complexe plusieurs-à-plusieurs (par exemple, « Étudiants » et « Cours »), le schéma ER doit introduire une entité associative pour la résoudre.
Péchés courants à éviter ⚠️
Mélanger ces modèles ou les utiliser incorrectement peut entraîner une dette technique importante. Voici des erreurs courantes à surveiller.
1. Mélanger logique et stockage
N’incluez pas de logique de traitement dans un MCD. Un MCD doit définir la structure, pas le comportement. Si vous vous retrouvez à dessiner des flèches représentant un « traitement » dans un MCD, vous décrivez probablement un MLD plutôt que le contraire.
2. Sur-modélisation du MLD
Un MLD ne doit pas être un organigramme de code. Il ne doit pas détailler chaque branche conditionnelle ou chaque routine de gestion des erreurs. Gardez le MLD au niveau logique. Si vous détaillez chaque instruction « si-sinon », le diagramme devient illisible et perd sa valeur d’aperçu de haut niveau.
3. Ignorer la cardinalité dans le MCD
Tracer des lignes entre des entités sans définir la cardinalité est une erreur courante. Une ligne seule ne vous indique pas si un client peut avoir zéro commande ou un million. Spécifiez toujours 1:1, 1:N ou M:N pour éviter toute ambiguïté.
4. Négliger les attributs de données
Les deux diagrammes souffrent lorsque les attributs de données sont flous. Dans un MLD, les flux doivent être nommés de manière descriptive (par exemple, « Informations de paiement validées » plutôt que « Données »). Dans un MCD, les attributs doivent définir les types de données et les contraintes là où cela est possible.
5. Créer des processus orphelins
Dans un MLD, un processus ne peut exister sans données qui entrent ou sortent de lui. Assurez-vous que chaque boîte de processus a au moins un flux entrant et un flux sortant. Les processus orphelins indiquent une logique morte ou des exigences de données manquantes.
Meilleures pratiques pour la documentation 📝
Pour maintenir la clarté et l’utilité, respectez ces normes de documentation.
- Nommage cohérent :Utilisez la même terminologie dans les deux diagrammes. Si un MLD l’appelle « Client », le MCD doit l’appeler « Client », et non « Utilisateur ». La cohérence réduit la charge cognitive pour l’équipe.
- Contrôle de version :Traitez les diagrammes comme du code. Maintenez un historique de version. Au fur et à mesure que le système évolue, les diagrammes doivent être mis à jour pour refléter l’état actuel.
- Notes contextuelles :Ajoutez des annotations aux zones complexes. Si une relation est non standard, expliquez pourquoi. Si un flux de données représente un traitement en arrière-plan, indiquez qu’il est asynchrone.
- Cycles de revue :Menez des revues formelles avec les parties prenantes métiers (pour le MLD) et les responsables techniques (pour le MCD). Un analyste métier pourrait repérer une faille logique dans le MLD qu’un développeur pourrait manquer, et inversement.
Réflexions finales sur le choix du modèle 🧠
Le choix entre un diagramme de flux de données et un diagramme entité-association ne consiste pas à privilégier l’un plutôt que l’autre. Il s’agit de choisir l’outil adapté à une phase spécifique du cycle de conception. Le MLD éclaire le parcours des données, garantissant que le système fonctionne comme prévu. Le MCD ancre ces données, garantissant qu’elles sont stockées de manière fiable et efficace.
En maîtrisant les objectifs distincts de ces deux modèles, les architectes peuvent concevoir des systèmes à la fois logiquement solides et structurellement robustes. L’objectif n’est pas de produire un diagramme parfait, mais de produire une compréhension claire du système. Quand l’équipe peut regarder un MLD et y voir le processus, et regarder un MCD et y voir les données, la fondation d’un projet réussi est posée.
Souvenez-vous que ces modèles sont des outils de communication. Leur valeur réside dans la compréhension partagée qu’ils créent au sein de l’équipe. Que vous soyez en train de cartographier une transaction complexe ou de définir un profil utilisateur, gardez l’accent sur la clarté, l’exactitude et l’alignement avec les objectifs métiers. Avec la bonne combinaison de flux et de structure, la conception de système devient une forme d’art disciplinée plutôt qu’un jeu de devinettes.
 Visual Paradigm Desktop |
Visual Paradigm Desktop |  Visual Paradigm Online
Visual Paradigm Online